
CAS 無鎖式同步機制
計算機系統中,CPU 和記憶體之間是通過匯流排進行通訊的,當某個執行緒佔有 CPU 執行指令的時候,會盡可能的將一些需要從記憶體中訪問的變數快取在自己的快取記憶體區中,而修改也不會立即對映到記憶體。
而此時,其他執行緒將看不到記憶體中該變數的任何改動,這就是我們說的記憶體可見性問題。連續的文章中,我們總共提出了兩種解決辦法。
其一是使用關鍵字 volatile 修飾共享的全域性變數,而 volatile 的實現原理大致分兩個步驟,任何對於該變數的修改操作都會由虛擬機器追加一條指令立馬將該變數所在快取區中的值回寫記憶體,接著將失效該變數在其他 CPU 快取區的引用。也就意味著,其他 CPU 如果再想要使用該變數,快取中是沒有的,進而逼迫去訪問記憶體拿最新的資料。
其二是使用關鍵字 synchronized 並藉助物件內建鎖實現資料一致性,主要思路是,如果一個執行緒因為競爭某個鎖失敗而被阻塞了,那麼它就認為別的執行緒正在工作,很可能會改了某些共享變數的資料,進而在獲得鎖後第一時間重新刷記憶體中的資料,同時一個執行緒走出同步程式碼塊之前會同步資料到記憶體。
其實我們也很少會使用第二種方法來解決記憶體可見性問題,著實有點大材小用的感覺,使用 volatile 關鍵字算是一個比較常用的方式。但是 volatile 是有特定的適用場景的,也具有它的侷限性,我們一起來看。
volatile 的侷限性
廢話不多說,先看一段程式碼:
public class MainTest { private static volatile int count; @Test public void testVolatile() throws InterruptedException { Thread1[] thread1s = new Thread1[100]; for (int i = 0; i < 100; i++){ thread1s[i] = new Thread1(); thread1s[i].start(); } for (int j = 0; j < 100; j++){ thread1s[j].join(); } System.out.println(count); } //每個執行緒隨機自增 count private class Thread1 extends Thread{ @Override public void run(){ try { Thread.sleep((long) (Math.random() * 500)); } catch (InterruptedException e) { e.printStackTrace(); } count++; } } }
我們將變數 count 使用 volatile 進行修飾,然後建立一百個執行緒並啟動,按照我們之前的理解,變數 count 的值一旦被修改就可以被其他執行緒立馬看到,不會快取在自己的工作記憶體。但是結果卻不是這樣。
多次執行,結果不盡相同
94
96
98
....
其實原因很簡單,我們只說過 volatile 會在變數值被修改後回寫記憶體並失效其他 CPU 快取中該變數的引用迫使其他執行緒從主存中重新去獲取該變數的值。
但是 count++ 這個操作並不是原子操作,之前我們說過這一點,這個操作會使得 CPU 做以下幾件事情:
- 從 CPU 快取讀出變數的值放入暫存器 A 中
- 為 count 加一併將值儲存在另一個暫存器 B 中
- 將暫存器 B 中的資料寫到快取並通過快取鎖回寫記憶體
而如果第一步剛執行結束,或第二步剛執行結束,但沒有執行第三步的時候,其他的某個執行緒更改了該變數的值並失效了當前 CPU 中快取中該變數的引用,那麼第三步會由於快取失效而先去記憶體中讀一個值過來,然後用暫存器 B 中的值覆蓋快取並刷到記憶體中。
這就意味著,在此之前其他執行緒的修改被覆蓋,進而我們得不到我們預期的結果。結論就是,volatile 關鍵字具有可見性而不具有原子性。
原子型別變數
JDK1.5 以後由 Doug Lea 大神設計的 java.util.concurrent.atomic 包中包含了原子型別相關的所有類。
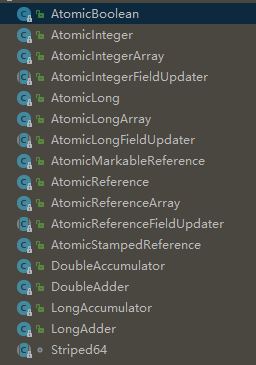
其中,
- AtomicBoolean:對應的 Boolean 型別的原子型別
- AtomicInteger:對應的 Integer 型別的原子型別
- AtomicLong:類似
- AtomicIntegerArray:對應的陣列型別
- AtomicLongArray:類似
- AtomicReference:對應的引用型別的原子型別
- AtomicIntegerFieldUpdater:欄位更新型別
剩餘的幾個類的作用,我們稍後再詳細介紹。
針對基本型別所對應的原子型別,我們以 AtomicInteger 這個類為例,看看它的原始碼實現情況。
AtomicInteger 相關實現
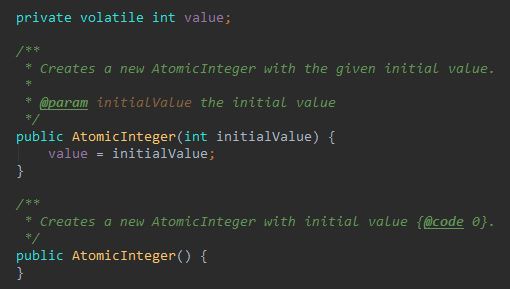
內部定義了一個 int 型別的變數 value,並且 value 修飾為 volatile,表示 value 這個欄位值的任何修改都對其他執行緒立即可見。
而建構函式允許你傳入一個初始的 value 數值,不傳的話就會導致 value 的值為零。
public final int getAndIncrement() {
return unsafe.getAndAddInt(this, valueOffset, 1);
}這個方法就是原子的「i++」操作,我們跟進去看:
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}幾個引數簡單說一下,var1 是我們的 AtomicInteger 例項引用,var2 是一個欄位偏移量,通過它我們可以定位到其中的 value 欄位。var4 這裡固定為一。
程式碼的邏輯也是簡單的,取出內部 value 欄位的值並暫存在變數 value5 中,然後再次判斷,如果 value 欄位的值依然等於 value5,那麼將原子操作式將 value 修改為 value4 + value5,本質上就是加一。
否則,說明在當前執行緒上次訪問後,又有其他執行緒修改了這個 value 欄位的值,於是我們重新獲取這個欄位的值,直到沒有人修改為止並自增它。
這個 compareAndSwapInt 方法我們一般把它叫做『CAS』,底層有系統指令做支撐,是一個比較並修改的原子指令,如果值等於 A 則將它修改為 B,否則返回。
AtomicInteger 中的其餘方法大致類似,都是依賴這個『CAS』方法實現的。
- int getAndAdd(int delta):自增 delta 並獲取修改之前的值
- int incrementAndGet():自增並獲取修改後的值
- int decrementAndGet():自減並獲取修改後的值
- int addAndGet(int delta):自增 delta 並獲取修改後的值
基於這一點,我們重構上述的執行緒不安全的 demo:
//構建一個原子型別變數 aCount
private static volatile AtomicInteger aCount = new AtomicInteger(0);
@Test
public void testAtomic() throws InterruptedException {
Thread2[] threads = new Thread2[100];
for (int i = 0; i < 100; i++){
threads[i] = new Thread2();
threads[i].start();
}
for (int i = 0; i < 100; i++){
threads[i].join();
}
System.out.println(aCount.get());
}
private class Thread2 extends Thread{
@Override
public void run(){
try {
Thread.sleep((long) (500 * Math.random()));
} catch (InterruptedException e) {
e.printStackTrace();
}
//原子自增
aCount.getAndIncrement();
}
}修改後的程式碼無論執行多少次,總會得到結果 100 。有關 AtomicLong、AtomicReference 的相關內容大致類似,都是依賴我們這個『CAS』方法,這裡不再贅述。
FieldUpdater 是基於反射來原子修改變數的值,這裡不多說了,下面我們看看『CAS』的一些問題。
CAS 的侷限性
ABA 問題
CAS 有一個典型問題就是「ABA 問題」,我們知道 CAS 工作的基本原理是,先讀取目標變數的值,然後呼叫原子指令判斷該值是否等於我們期望的值,如果等於就認為沒有被別人改過,否則視作資料髒了,重新去讀變數的值。
但是問題是,如果變數 a 的值為 100,我們的 CAS 方法也讀到了 100,接著來了一個執行緒將這個變數改為 999,之後又來一個執行緒再改了一下,改成 100 。而輪到我們的主執行緒發現 a 的值依然是 100,它視作沒有人和它競爭修改 a 變數,於是修改 a 的值。
這種情況,雖然 CAS 會更新成功,但是會存在潛在的問題,中途加入的執行緒的操作對於後一個執行緒根本是不可見的。而一般的解決辦法是為每一次操作加上加時間戳,CAS 不僅關注變數的原始值,還關注上一次修改時間。
迴圈時間長開銷大
我們的 CAS 方法一般都定義在一個迴圈裡面,直到修改成功才會退出迴圈,如果在某些併發量較大的情況下,變數的值始終被別的執行緒修改,本執行緒始終在迴圈裡做判斷比較舊值,效率低下。
所以說,CAS 適用於併發量不是很高的情況下,效率遠遠高於鎖機制。
只能保證一個變數的原子操作
CAS 只能對一個變數進行原子性操作,而鎖機制則不同,獲得鎖之後,就可以對所有的共享變數進行修改而不會發生任何問題,因為別人沒有鎖不能修改這些共享變數。
總結一下,鎖其實是一種悲觀的思想,「我認為所有人都會和我來競爭某些資源的使用,所以我得到資源之後把它鎖上,用完再釋放掉鎖」,而 CAS 則是一種樂觀的思想,「我以為只有我一個人在使用這些資源,假如有人也在使用,那我再次嘗試即可」。
CAS 是以後的各種併發容器的實現基石,是一種樂觀的、非阻塞式的演算法,將有助於提升我們的併發效能。
文章中的所有程式碼、圖片、檔案都雲端儲存在我的 GitHub 上:
(https://github.com/SingleYam/overview_java)
歡迎關注微信公眾號:OneJavaCoder,所有文章都將同步在公眾號上。
