Ubantu 安裝 TensorFlow
1、安裝 Python3
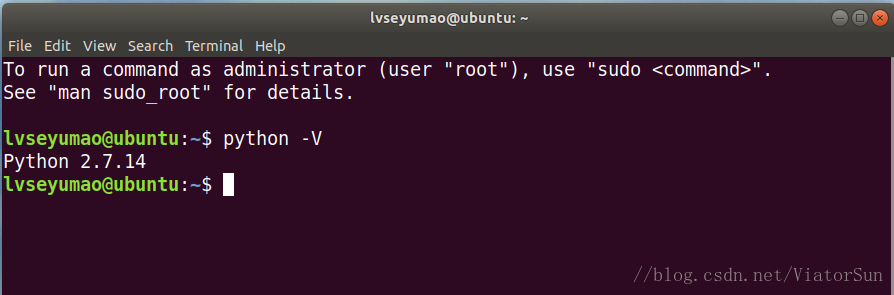
1)檢視系統所安裝的python版本
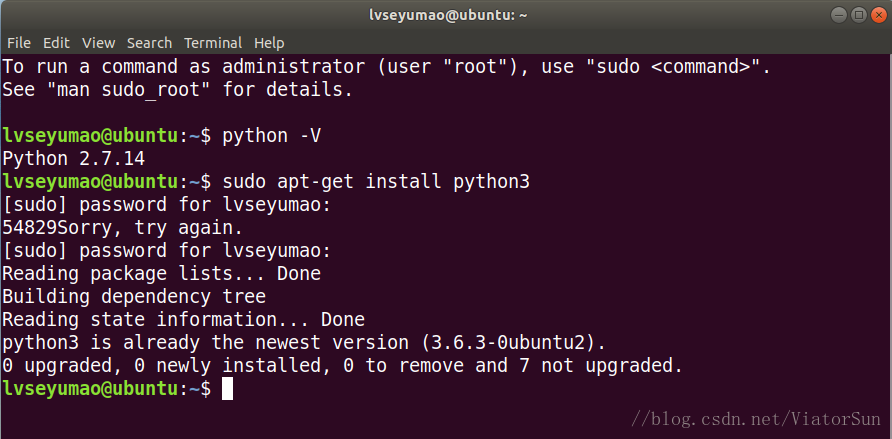
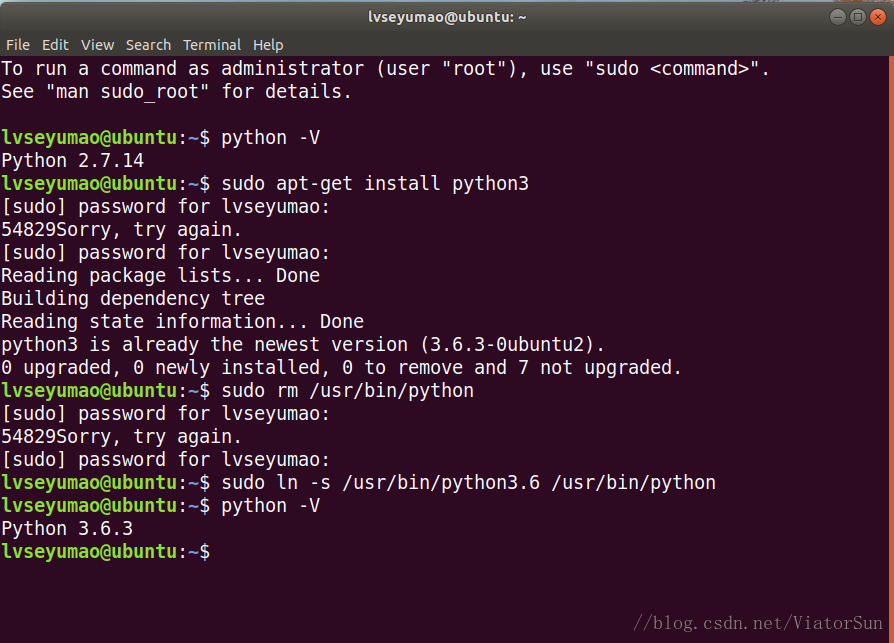
開啟終端(快捷鍵:Ctrl+Alt+T)輸入指令:python -V (大寫 V),如圖所示,我的系統是ubuntu17.10,預設安裝的python版本為2.7.14。
2)安裝最新 Python3##
通過命令列sudo apt-get install python3 即可安裝最新版本的Python3:
由於我安裝的是Ubantu 17.10.1 系統自帶Python 3,所以提示安裝0個安裝包
 剛才的Python3是被預設安裝帶usr/local/lib/python3.6目錄中,如下
剛才的Python3是被預設安裝帶usr/local/lib/python3.6目錄中,如下

由於Ubuntu很多底層採用的是Python2.*,而Python2和Python3是互相不相容的,所以此時不能解除安裝Python2,需要將預設Python的指向Python3
3)重指定系統預設 Python
在命令提示符中輸入:sudo rm /usr/bin/python 移除預設的python2.7
輸 入:sudo ln -s /usr/bin/python3.6 /usr/bin/python 指定python3.6為預設python
並 通 過:python -V 檢查系統預設指定Python版本
對於已經安裝過Python3的可以通過sudo apt-get install python3來升級Python3到最新版本,然後從新定向Python
sudo mv /usr/bin/python3 /usr/bin/python3-old
sudo ln -s /usr/bin/python3.x /usr/bin/python3
2、安裝 pip3
pip是一個安裝和管理Python包的工具。在pip的幫助下,你可以安裝獨特版本的包。最重要的是,pip可以通過一個“requirements”的工具來管理一個由包組成的列表和版本號。pip很像easy_install,但是pip有一些額外的特色。
1)更新系統包
sudo apt-get update
sudo apt-get upgrade
2)安裝 pip3
# python2環境下安裝pip # sudo apt-get install pip # python3環境下安裝pip sudo apt-get install python3-pip
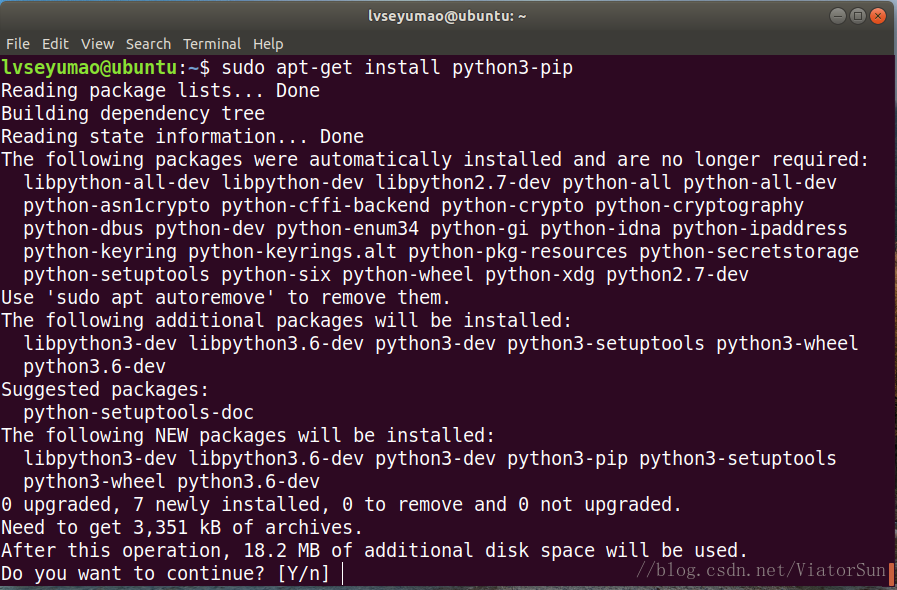
對於已經安裝過pip的可以通過以下命令直接升級pip版本
# python 2.7版本:
sudo pip install --upgrade pip
# python 3.x版本:
sudo pip3 install --upgrade pip
3)檢查是否安裝成功
檢查 pip3 是否安裝成功
pip3 -V

4)解除安裝舊版本 pip
但有時通過apt-get安裝的pip版本太老,使用舊版本pip安裝一些包時會報出提醒來升級pip。如果想升級最新的pip,需要先解除安裝pip,命令為
sudo apt-get remove python-pip
5)pip 常用命令
- 檢視pip幫助:pip -help
- 安裝新的python包:pip install packageName
- 解除安裝python包:pip uninstall packageName
- 尋找python包:pip search packageName
3、安裝 vim
系統是沒有自帶Vim的,需要我們通過以下指令進行安裝
sudo apt-get install vim
4、安裝 scrapy
scrapy是一個快速高層次的螢幕抓取和web抓取框架,用於抓取web站點並從頁面中提取結構化的資料,可以用於資料探勘、檢測和自動化測試。
該擴充套件庫具有如下優點:整個爬取過程簡單。建立一個類,並定義要刪除的專案型別,編寫一些從網頁中提取資料的規則,結果將以JSON、XML、CSV或其他的格式匯出,蒐集的資料可以儲存在raw,也可以在匯入時進行清理。此外scrapy可以擴充套件允許其他行為例如網站登入處理、會話cookie處理。影象也可被scrapy自動提取並與被抓取的內容進行關聯。 總之scrapy是一個很強大的爬蟲爬取框架。
需要在root模式下使用如下命令安裝
# 通過sudo su進入到root模式,可能需要輸入命令
sudo su
# 通過以下命令安裝scrapy
pip3 install scrapy
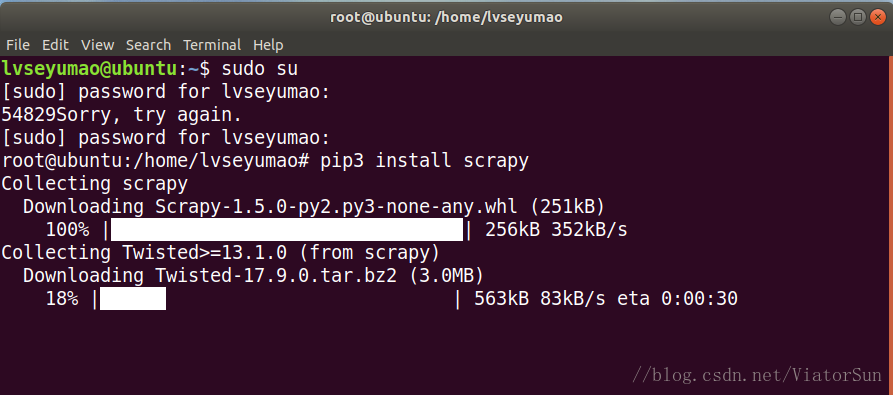
5、安裝 numpy
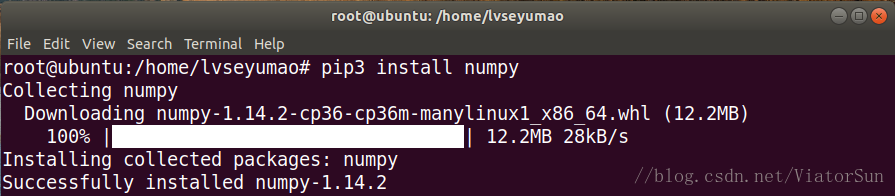
numpy是一個開源的科學計算和數學工作基礎包,包括統計學、線性代數、矩陣等 可使用如下命令安裝,同樣需要取得root許可權:
sudo su
pip3 install numpy
6、安裝TensorFlow
TensorFlow可以安裝CPU和GPU兩種版本,對於深度學習GPU執行效率大約是CPU的幾倍至幾十倍,相同的程式,CPU版可能需要執行一天左右(假設),那麼GPU版本可能幾個小時就執行完了,而目前跑深度學習的GPU暫時主要是英偉達(NVIDIA)。 ##1) GPU 版本安裝: GPU安裝過程要比CPU安裝複雜許多,大致過程有以下幾步:
- 更新電腦顯示卡驅動,直接在更新裡面就可以完成;
- 先更改gcc和g++,Ubantu17自帶的gcc和g++為7版本的,Tensorflow暫時還不支援這麼高的版本,所以首先我們需要將gcc和g++降低版本(gcc和g++的作用如同windows裡的vc和vs一樣,為c和c++編譯器,而gcc和g++就是Ubantu裡的c和c++編譯器);
- 安裝CUDA,CUDA是英偉達專門為GPU計算推出的計算平臺,從CUDA3.0開始已經支援C++和FORTRAN,所以上面我們需要將gcc和g++調整到CUDA支援的版本;
- 安裝cuDNN,cuDNN是英偉達為CUDA加速運算推出的加速庫,用於在GPU上實現高效能現代平行計算;
而如何才能知道自己的電腦是否支援TensorFlow的GPU版本,需要檢視自己的電腦硬體配置,如果檢視電腦硬體不太方便的話,可以通過以下命令檢視Ubantu顯示卡的型號:
lspci|grep VGA
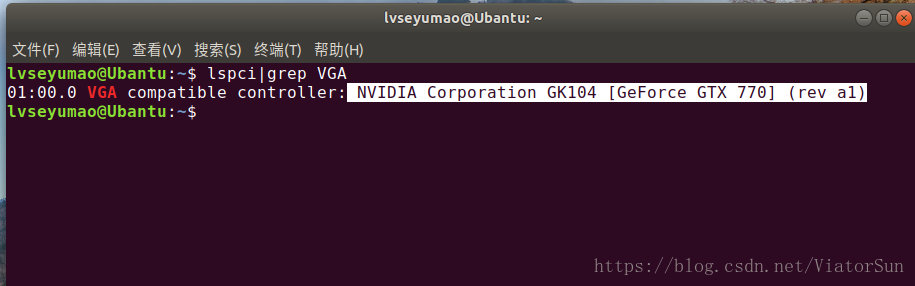

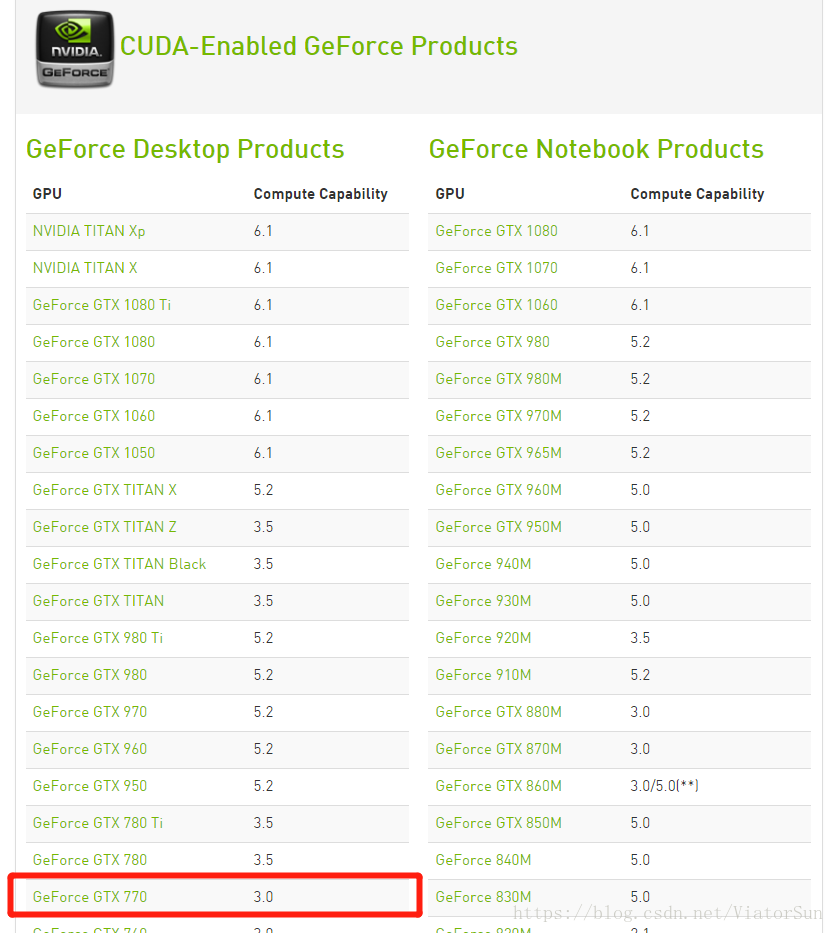
GPU版本安裝命令如下: 具體安裝教程請參考https://blog.csdn.net/dream_an/article/details/74992346
2)CPU 版本安裝命令如下:
CPU效能雖然不如GPU效率高,但是GPU也不是常有的,所以CPU版本的更適用沒有很好地獨立顯示卡的小夥伴們,CPU的各個系列型號的效能也是不盡相同的,通過以下指令可以直接檢視電腦的CPU資訊:
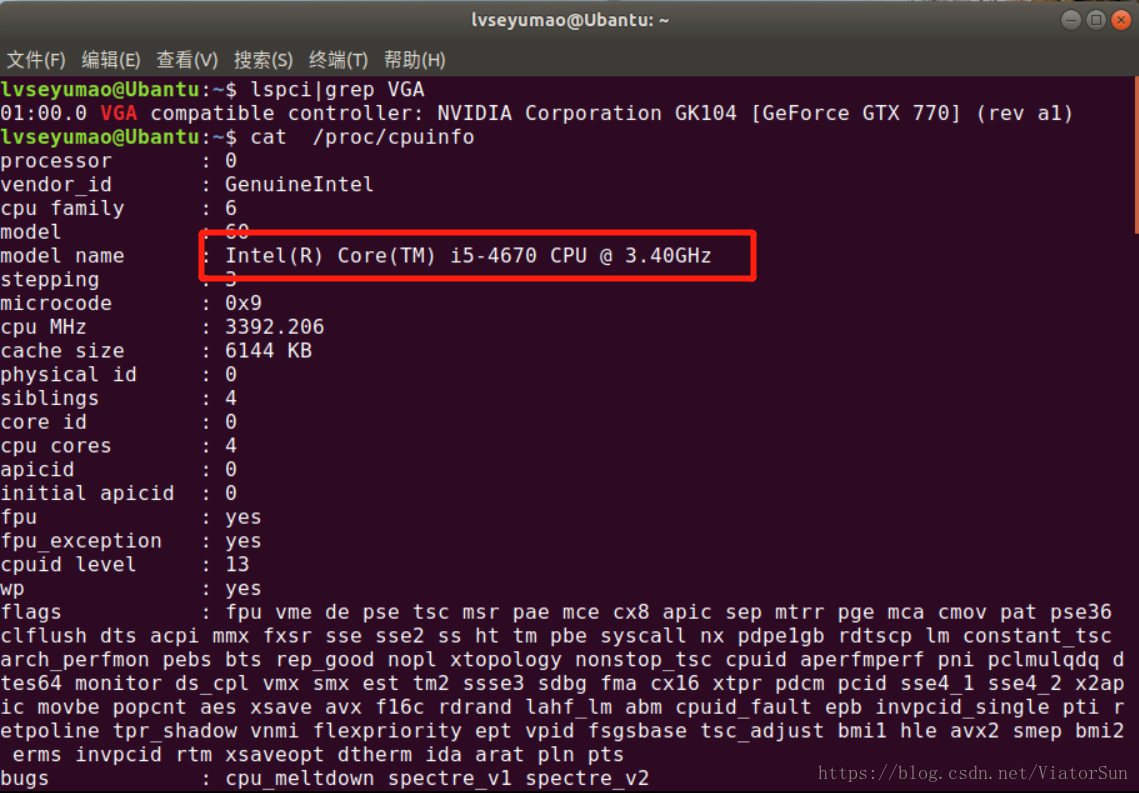
CPU版本的TensorFlow安裝也很簡單,命令如下:
# python 2.7版本:
sudo pip install tensorflow
# python 3.x版本:
sudo pip3 install tensorflow
若上述命令執行過程沒有報錯,則安裝成功
若提示錯誤,請檢查網路,重試上述命令
3)解除安裝Tensorflow
如果剛開始安裝了CPU版本的TensorFlow,後來發現GPU支援,那麼需要先解除安裝CPU版本的TensorFlow,命令如下:
sudo pip uninstall tensorflow
成功解除安裝效果為:
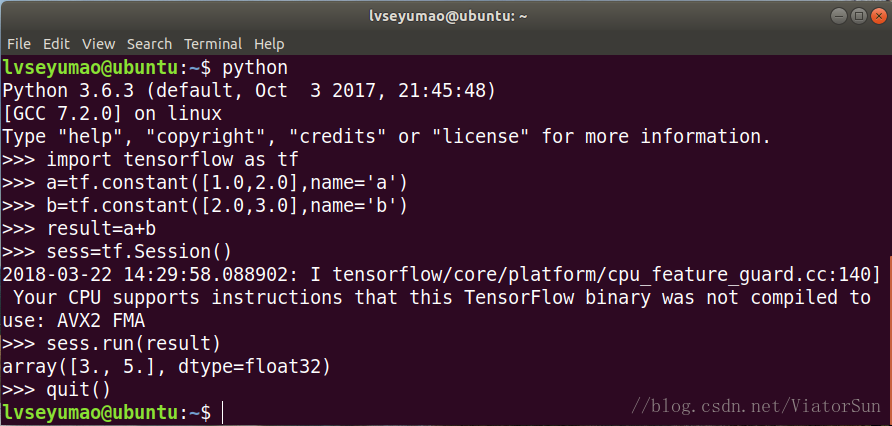
7、測試安裝結果
進入python編譯環境,匯入TensorFlow,做一個簡單的加法運算,如圖所示。