
redis 主從架構剖析
阿新 • • 發佈:2018-12-13
圖解redis replication基本原理
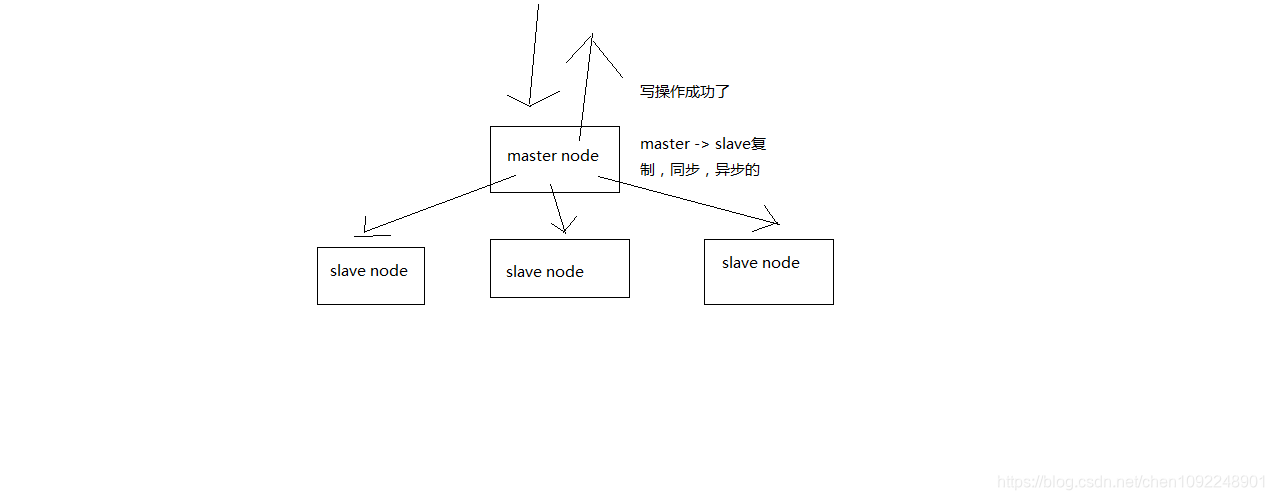
redis replication的核心機制
(1)redis採用非同步方式複製資料到slave節點,不過redis 2.8開始,slave node會週期性地確認自己每次複製的資料量 (2)一個master node是可以配置多個slave node的 (3)slave node也可以連線其他的slave node (4)slave node做複製的時候,是不會block master node的正常工作的 (5)slave node在做複製的時候,也不會block對自己的查詢操作,它會用舊的資料集來提供服務; 但是複製完成的時候,需要刪除舊資料集,載入新資料集,這個時候就會暫停對外服務了 (6)slave node主要用來進行橫向擴容,做讀寫分離,擴容的slave node可以提高讀的吞吐量
master持久化對於主從架構的安全保障的意義
(1)如果採用了主從架構,那麼建議必須開啟master node的持久化!不建議用slave node作為master node的資料熱備,因為那樣的話,如果你關掉master的持久化,可能在master宕機重啟的時候資料是空的,然後可能一經過複製,salve node資料也丟了,master -> RDB和AOF都關閉了 -> 全部在記憶體中,master宕機,重啟,是沒有本地資料可以恢復的,然後就會直接認為自己IDE資料是空的,master就會將空的資料集同步到slave上去,所有slave的資料全部清空,100%的資料丟失,master節點,必須要使用持久化機制。 (2)master的各種備份方案,要不要做,萬一說本地的所有檔案丟失了; 從備份中挑選一份rdb去恢復master; 這樣才能確保master啟動的時候,是有資料的,即使採用了後續講解的高可用機制,slave node可以自動接管master node,但是也可能sentinal還沒有檢測到master failure,master node就自動重啟了,還是可能導致上面的所有slave node資料清空故障
主從架構的核心原理

1.當啟動一個slave node的時候,它會發送一個PSYNC命令給master node(相當於去ping下master) 2.如果這是slave node重新連線master node,那麼master node僅僅會複製給slave部分缺少的資料; 否則如果是slave node第一次連線master node,那麼會觸發一次full resynchronization(全量複製) 3.開始full resynchronization的時候,master會啟動一個後臺執行緒,開始生成一份RDB快照檔案,同時還會將從客戶端收到的所有寫命令快取在記憶體中。RDB檔案生成完畢之後,master會將這個RDB傳送給slave,slave會先寫入本地磁碟,然後再從本地磁碟載入到記憶體中。然後master會將記憶體中快取的寫命令傳送給slave,slave也會同步這些資料。 4.slave node如果跟master node有網路故障,斷開了連線,會自動重連。master如果發現有多個slave node都來重新連線,僅僅會啟動一個rdb save操作,用一份資料服務所有slave node。
主從複製的斷點續傳
1.從redis 2.8開始,就支援主從複製的斷點續傳,如果主從複製過程中,網路連線斷掉了,那麼可以接著上次複製的地方,繼續複製下去,而不是從頭開始複製一份
2.master node會在記憶體中常見一個backlog,master和slave都會儲存一個replica offset還有一個master id,offset就是儲存在backlog中的。如果master和slave網路連線斷掉了,slave會讓master從上次的replica offset開始繼續複製,但是如果沒有找到對應的offset,那麼就會執行一次resynchronization(offset相當於一個標記)
無磁碟化複製
master在記憶體中直接建立rdb,然後傳送給slave,不會在自己本地落地磁碟了
repl-diskless-sync yes/no
repl-diskless-sync-delay,等待一定時長再開始複製,因為要等更多slave重新連線過來
過期key處理
slave不會過期key,只會等待master過期key。如果master過期了一個key,或者通過LRU淘汰了一個key,那麼會模擬一條del命令傳送給slave。
複製的完整流程

(1)slave node啟動,僅僅儲存master node的資訊,包括master node的host和ip,但是複製流程沒開始
master host和ip是從哪兒來的,redis.conf裡面的slaveof配置的
(2)slave node內部有個定時任務,每秒檢查是否有新的master node要連線和複製,如果發現,就跟master node建立socket網路連線
(3)slave node傳送ping命令給master node
(4)口令認證,如果master設定了requirepass,那麼salve node必須傳送masterauth的口令過去進行認證
(5)master node第一次執行全量複製,將所有資料發給slave node
(6)master node後續持續將寫命令,非同步複製給slave node
資料同步相關的核心機制
指的就是第一次slave連線msater的時候,執行的全量複製,那個過程裡面你的一些細節的機制
(1)master和slave都會維護一個offset
master會在自身不斷累加offset,slave也會在自身不斷累加offset
slave每秒都會上報自己的offset給master,同時master也會儲存每個slave的offset
這個倒不是說特定就用在全量複製的,主要是master和slave都要知道各自的資料的offset,才能知道互相之間的資料不一致的情況
(2)backlog
master node有一個backlog,預設是1MB大小
master node給slave node複製資料時,也會將資料在backlog中同步寫一份,backlog主要是用來做全量複製中斷候的增量複製的
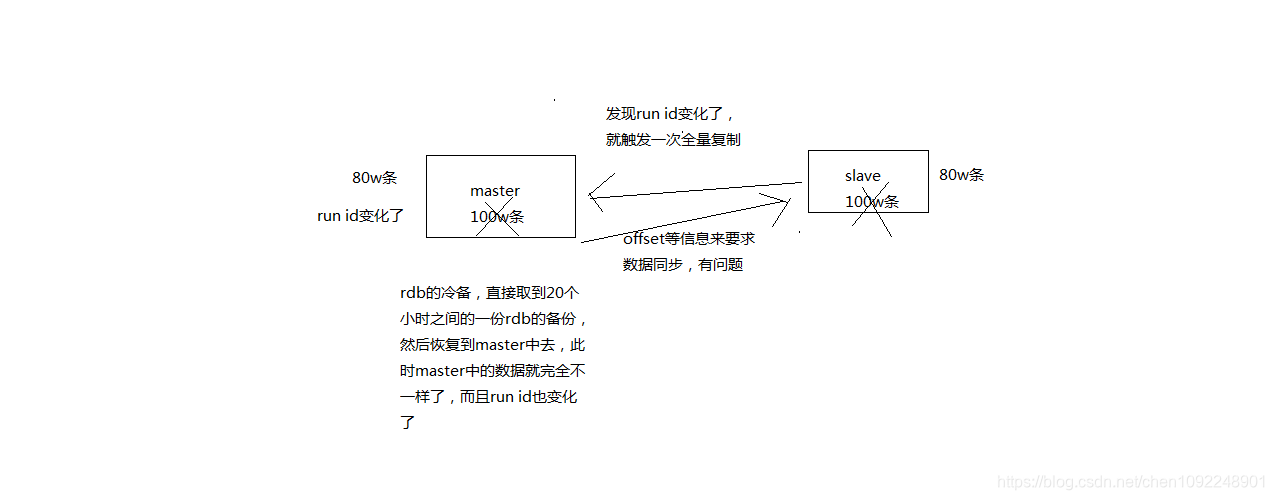
(3)master run id
info server,可以看到master run id
如果根據host+ip定位master node,是不靠譜的,如果master node重啟或者資料出現了變化,那麼slave node應該根據不同的run id區分,run id不同就做全量複製,如果需要不更改run id重啟redis,可以使用redis-cli debug reload命令
(4)psync
從節點使用psync從master node進行復制,psync runid offset master node會根據自身的情況返回響應資訊,可能是FULLRESYNC runid offset觸發全量複製,可能是CONTINUE觸發增量複製
全量複製
(1)master執行bgsave,在本地生成一份rdb快照檔案
(2)master node將rdb快照檔案傳送給salve node,如果rdb複製時間超過60秒(repl-timeout),那麼slave node就會認為複製失敗,可以適當調節大這個引數
(3)對於千兆網絡卡的機器,一般每秒傳輸100MB,6G檔案,很可能超過60s
(4)master node在生成rdb時,會將所有新的寫命令快取在記憶體中,在salve node儲存了rdb之後,再將新的寫命令複製給salve node
(5)client-output-buffer-limit slave 256MB 64MB 60,如果在複製期間,記憶體緩衝區持續消耗超過64MB,或者一次性超過256MB,那麼停止複製,複製失敗
(6)slave node接收到rdb之後,清空自己的舊資料,然後重新載入rdb到自己的記憶體中,同時基於舊的資料版本對外提供服務
(7)如果slave node開啟了AOF,那麼會立即執行BGREWRITEAOF,重寫AOF
增量複製
(1)如果全量複製過程中,master-slave網路連線斷掉,那麼salve重新連線master時,會觸發增量複製
(2)master直接從自己的backlog中獲取部分丟失的資料,傳送給slave node,預設backlog就是1MB
(3)msater就是根據slave傳送的psync中的offset來從backlog中獲取資料的
heartbeat(心跳)
主從節點互相都會發送heartbeat資訊
master預設每隔10秒傳送一次heartbeat,salve node每隔1秒傳送一個heartbeat
非同步複製
master每次接收到寫命令之後,現在內部寫入資料,然後非同步傳送給slave node