
Java核心資料結構(List、Map、Set)原理與使用技巧
JDK提供了一組主要的資料結構實現,如List、Map、Set等常用資料結構。這些資料都繼承自java.util.Collection介面,並位於java.util包內。
一、List介面
最重要的三種List介面實現:ArrayList、Vector、LinkedList。它們的類圖如下:
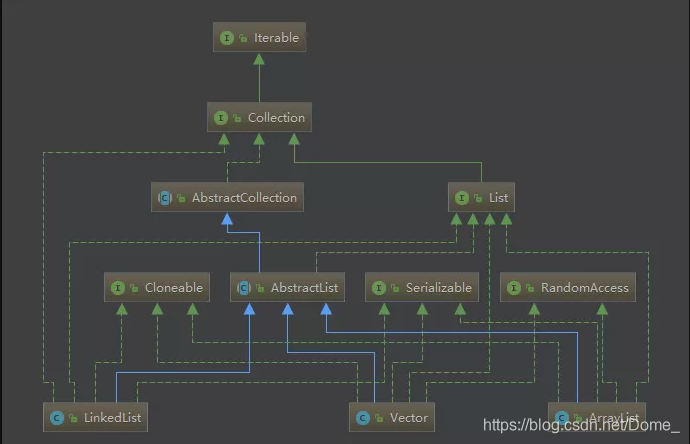
可以看到,3種List均來自AbstratList的實現。而AbstratList直接實現了List介面,並擴充套件自AbstratCollection。
ArrayList和Vector使用了陣列實現,可以認為,ArrayList封裝了對內部陣列的操作。比如向陣列中新增、刪除、插入新的元素或陣列的擴充套件和重定義。對ArrayList或者Vector的操作,等價於對內部物件陣列的操作。
ArrayList和Vector幾乎使用了相同的演算法,它們的唯一區別可以認為是對多執行緒的支援。ArrayList沒有對一個方法做執行緒同步,因此不是執行緒安全的。Vector中絕大多數方法都做了執行緒同步,是一種執行緒安全的實現。因此ArrayList和Vector的效能特性相差無幾。
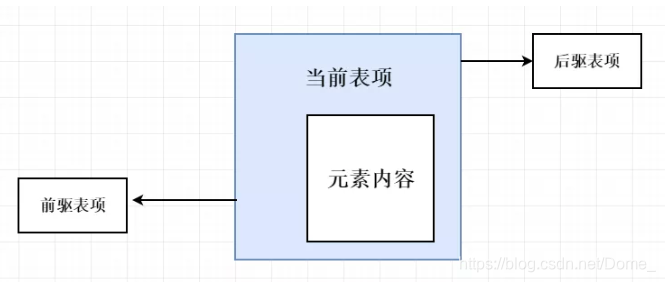
LinkedList使用了迴圈雙向連結串列資料結構。LinkedList由一系列表項連線而成。一個表項總是包含3個部分:元素內容、前驅表項和後驅表項。如圖所示:
LinkedList的表項原始碼:
private static class Node<E> { E item; Node<E> next; Node<E> prev; Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } }
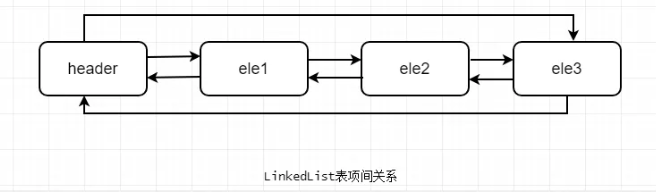
無論LinkedList是否為空,連結串列都有一個header表項,它既是連結串列的開始,也表示連結串列的結尾。它的後驅表項便是連結串列的第一個元素,前驅表項便是連結串列的最後一個元素。如圖所示:
下面比較下ArrayList和LinkedList的不同。
1、增加元素到列表尾端
對於ArrayList來說,只要當前容量足夠大,add()操作的效率是非常高的。
只有當ArrayList對容量的需求超過當前陣列的大小時,才需要進行擴容。擴容會進行大量的陣列複製操作。而複製時最終呼叫的是System.arraycopy()方法,因此,add()效率還是相當高的。
LinkedList由於使用了連結串列的結構,因此不需要維護容量的大小。這點比ArrayList有優勢,不過,由於每次元素增加都需要新建Node物件,並進行更多的賦值操作。在頻繁的系統呼叫中,對效能會產生一定影響。
2、插入元素到列表任意位置
ArrayList是基於陣列實現的,而陣列是一塊連續的記憶體空間,每次插入操作,都會進行一次陣列複製。大量的陣列複製會導致系統性能低下。
LinkedList是基於連結串列實現的,在任意位置插入和在尾端增加是一樣的。所以,如果系統應用需要對List物件在任意位置進行頻繁的插入操作,可以考慮用LinkedList替代ArrayList。
3、刪除任意位置元素
對ArrayList來說,每次remove()移除元素都需要進行陣列重組。並且元素位置越靠前開銷越大,要刪除的元素越靠後,開銷越小。
在LinkedList的實現中,首先需要通過迴圈找到要刪除的元素。如果要刪除的元素位置處於List的前半段,則從前往後找;若處於後半段,則從後往前找。如果要移除中間位置的元素,則需要遍歷完半個List,效率很低。
4、容量引數
容量引數是ArrayList 和 Vector等基於陣列的List的特有效能引數,它表示初始陣列的大小。
合理的設定容量引數,可以減少陣列擴容,提升系統性能。
預設ArrayList的陣列初始大小為10。
private static final int DEFAULT_CAPACITY = 10;
5、遍歷列表
常用的三種列表遍歷方式:ForEach操作、迭代器和for迴圈。
對於ForEach操作,反編譯可知實際上是將ForEach迴圈體作為迭代器處理。不過ForEach比自定義的迭代器多了一步賦值操作,效能不如直接使用迭代器的方式。
使用For迴圈通過隨機訪問遍歷列表,ArrayList表現很好,速度最快;但是LinkedList的表現非常差,應避免使用,這是因為對LinkedList的隨機訪問時,總會進行一次列表的遍歷操作。
二、Map介面
Map是一種非常常用的資料結構。圍繞著Map介面,最主要的實現類有Hashtable, HashMap, LinkedHashMap 和 TreeMap,在Hashtable中,還有Properties 類的實現。
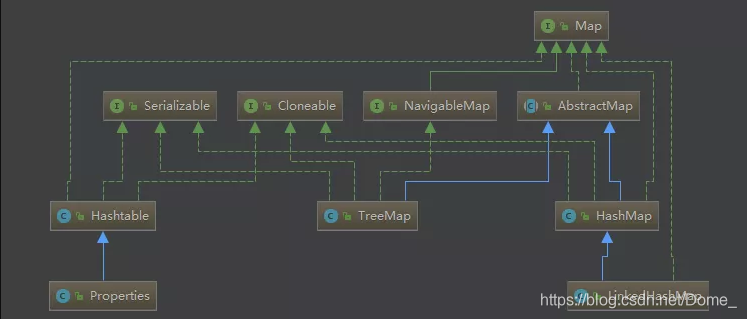
Hashtable和hashMap的區別在於Hashtable的大部分方法都做了執行緒同步,而HashMap沒有,因此,Hashtable是執行緒安全的,HashMap不是。其次,Hashtable 不允許key或value使用null值,而HashMap可以。
第三,它們在內部對key的hash演算法和hash值到記憶體索引的對映演算法不同。
由於HashMap使用廣泛,本文以HashMap為例,闡述它的實現原理。
1、HashMap的實現原理
簡單來說,HashMap就是將key做hash演算法,然後將hash值對映到記憶體地址,直接取得key所對應的資料。在HashMap中,底層資料結構使用的是陣列。所謂的記憶體地址,就是陣列的下標索引。
用程式碼簡單表示如下:
object[key_hash] = value;
2、Hash衝突
當需要存放的兩個元素1和2經hash計算後,發現對應在記憶體中的同一個地址。此時HashMap又會如何處理以保證資料的完整存放?
在HashMap的底層使用陣列,但陣列內的元素不是簡單的值,而是一個Entity類的物件。每一個Entity表項包括key,value,next,hash幾項。注意這裡的next部分,它指向另外一個Entity。
當put()操作有衝突時,新的Entity會替換原有的值,為了保證舊值不丟失,會將next指向舊值。這便實現了在一個數組空間記憶體放多個值項。因此,HashMap實際上是一個連結串列的陣列。
而在進行get()操作時,如果定位到的陣列元素不含連結串列(當前entry的next指向null),則直接返回;如果定位到的陣列元素包含連結串列,則需要遍歷連結串列,通過key物件的equals方法逐一比對查詢。
3、容量引數
和ArrayList一樣,基於陣列的結構,不可避免的需要在陣列空間不足時,進行擴充套件。而陣列的重組比較耗時,因此對其做一定的優化很有必要了。
HashMap提供了兩個可以指定初始化大小的建構函式:
HashMap(int initialCapacity)
構造一個帶指定初始容量和預設負載因子 (0.75) 的空 HashMap。
HashMap(int initialCapacity, float loadFactor)
構造一個帶指定初始容量和負載因子的空 HashMap。
其中,HashMap會使用大於等於initialCapacity並且是2的指數次冪的最小的整數作為內建陣列的大小。
負載因子又叫做填充比,它是介於0和1之間的浮點數。
負載因子 = 實際元素個數 / 內部陣列總大小
負載因子的作用就是決定HashMap的閾值(threshold)。
閾值 = 陣列總容量 × 負載因子
當HashMap的實際容量超過閾值便會進行擴容,每次擴容將新的陣列大小設定為原大小的1.5倍。
預設情況下,HashMap的初始大小是16,負載因子為0.75。
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
static final float DEFAULT_LOAD_FACTOR = 0.75f;
4、LinkedHashMap
LinkedHashMap繼承自HashMap,因此,它具備了HashMap的優良特性,並在此基礎上,LinkedHashMap又在內部增加了一個連結串列,用以存放元素的順序。因此,LinkedHashMap可以簡單理解為一個維護了元素次序表的HashMap.
LinkedHashMap提供兩種型別的順序:一是元素插入時的順序;二是最近訪問的順序。
LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder)
構造一個帶指定初始容量、負載因子和排序模式的空 LinkedHashMap 例項
其中accessOrder為true時,按照元素最後訪問時間排序;當accessOrder為false 時,按照插入順序排序。預設為 false 。
在內部實現中,LinkedHashMap通過繼承HashMap.Entity類,實現LinkedHashMap.Entity,為HashMap.Entity增加了before和after屬性用以記錄某一表項的前驅和後繼,並構成迴圈連結串列。
5、TreeMap
TreeMap可以簡單理解為一種可以進行排序的Map實現。與LinkedHashMap不同,LinkedHashMap是根據元素增加或者訪問的先後順序進行排序,而TreeMap則根據元素的Key進行排序。為了確定Key的排序演算法,可以使用兩種方式指定:
(1)在TreeMap的建構函式中注入一個Comparator:
TreeMap(Comparator<? super K> comparator)
(2)使用一個實現了 Comparable 介面的 Key。
TreeMap的內部實現是基於紅黑樹的。紅黑樹是一種平衡查詢樹,這裡不做過多介紹。
TreeMap 其它排序介面如下:
subMap(K fromKey, K toKey)
返回此對映的部分檢視,其鍵值的範圍從 fromKey(包括)到 toKey(不包括)。
tailMap(K fromKey)
返回此對映的部分檢視,其鍵大於等於 fromKey。
firstKey()
返回此對映中當前第一個(最低)鍵。
headMap(K toKey)
返回此對映的部分檢視,其鍵值嚴格小於 toKey。
一個簡單示例如下:
public class MyKey implements Comparable<MyKey> {
private int id;
public MyKey(int id) {
this.id = id;
}
@Override
public int compareTo(MyKey o) {
if (o.id < this.id){
return 1;
}else if (o.id > this.id){
return -1;
}
return 0;
}
public static void main(String[] args) {
MyKey myKey1 = new MyKey(1);
MyKey myKey2 = new MyKey(2);
MyKey myKey3 = new MyKey(3);
Map<MyKey,Object> map = new TreeMap<>();
map.put(myKey1,"一號");
map.put(myKey3,"三號");
map.put(myKey2,"二號");
Iterator<MyKey> iterator = map.keySet().iterator();
while (iterator.hasNext()){
System.out.println(map.get(iterator.next()));
}
}
}
三、Set介面
Set並沒有在Collection介面之上增加額外的操作,Set集合中的元素是不能重複的。
其中最為重要的是HashSet、LinkedHashSet、TreeSet 的實現。這裡不再一一贅述,因為所有的這些Set實現都只是對應的Map的一種封裝而已。
四、優化集合訪問程式碼
1、分離迴圈中被重複呼叫的程式碼
舉個例子,當我們要使用for迴圈遍歷集合時
for (int i =0;i<collection.size();i++){
//.....
}
很明顯,每次迴圈都會呼叫size()方法,並且每次都會返回相同的數值。分離所有類似的程式碼對提升迴圈效能有著積極地意義。因此,可以將上段程式碼改造成
int size= collection.size();
for (int i =0;i<size;i++){
//.....
}
當元素的數量越多時,這樣的處理就越有意義。
2、省略相同的操作
假設我們有一段類似的操作如下
int size= collection.size();
for (int i =0;i<size;i++){
if (list.get(i)==1||list.get(i)==2||list.get(i)==3){
//...
}
}
雖然每次迴圈呼叫get(i)的返回值不同,但在同一次呼叫中,結果是相同的,因此可以提取這些相同的操作。
int size= collection.size();
int k=0;
for (int i =0;i<size;i++){
if ((k = list.get(i))==1||k==2||k==3){
//...
}
}
3、減少方法呼叫
方法呼叫是需要消耗系統堆疊的,如果可以,則儘量訪問內部元素,而不要呼叫對應的介面,函式呼叫是需要消耗系統資源的,直接訪問元素會更高效。
假設上面的程式碼是Vector.class的子類的部分程式碼,那麼可以這麼改寫
int size = this.elementCount;
Object k=null;
for (int i =0;i<size;i++){
if ((k = elementData[i])=="1"||k=="2"||k=="3"){
//...
}
}
可以看到,原本的 size() 和 get() 方法被直接替代為訪問原始變數,這對系統性能的提升是非常有用的。
五、RandomAccess介面
RandomAccess介面是一個標誌介面,本身並沒有提供任何方法,任何實現RandomAccess介面的物件都可以認為是支援快速隨機訪問的物件。此介面的主要目的是標識那些可以支援快速隨機訪問的List實現。
在JDK中,任何一個基於陣列的List實現都實現了RandomAccess介面,而基於連結串列的實現則沒有。這很好理解,只有陣列能夠快速隨機訪問,(比如:通過 object[5],object[6]可以直接查詢並返回物件),而對連結串列的隨機訪問需要進行連結串列的遍歷。
在實際操作中,可以根據list instanceof RandomAccess來判斷物件是否實現 RandomAccess介面,從而選擇是使用隨機訪問還是iterator迭代器進行訪問。
在應用程式中,如果需要通過索引下標對 List 做隨機訪問,儘量不要使用 LinkedList,ArrayList和Vector都是不錯的選擇。