
[JVM]java物件結構
先轉載一篇文章作為開頭,因為講的非常詳細,我就簡單加工下放到這裡:
物件結構
在HotSpot虛擬機器中,物件在記憶體中儲存的佈局可以分為3塊區域:物件頭(Header)、例項資料(Instance Data)和對齊填充(Padding)。下圖是普通物件例項與陣列物件例項的資料結構:
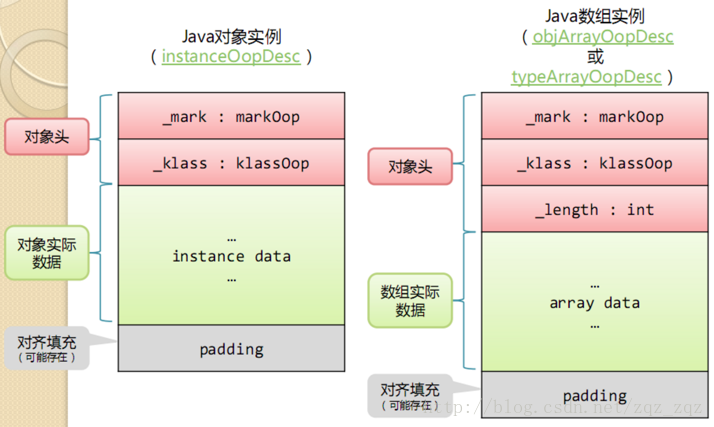
(Header)物件頭
HotSpot虛擬機器的物件頭包括兩部分資訊:
- MarkWord 第一部分markword,用於儲存物件自身的執行時資料,如雜湊碼(HashCode)、GC分代年齡、鎖狀態標誌、執行緒持有的鎖、偏向執行緒ID、偏向時間戳等,這部分資料的長度在32位和64位的虛擬機器(未開啟壓縮指標)中分別為32bit和64bit,官方稱它為“MarkWord”。
- klass 物件頭的另外一部分是klass型別指標,即物件指向它的類元資料的指標,虛擬機器通過這個指標來確定這個物件是哪個類的例項.
- 陣列長度(只有陣列物件有) 如果物件是一個數組, 那在物件頭中還必須有一塊資料用於記錄陣列長度.
(InstanceData)例項資料
Longs doubles shorts/charts
例項資料部分是物件真正儲存的有效資訊,也是在程式程式碼中所定義的各種型別的欄位內容。無論是從父類繼承下來的,還是在子類中定義的,都需要記錄起來。
(Padding)對齊填充
第三部分對齊填充並不是必然存在的,也沒有特別的含義,它僅僅起著佔位符的作用。由於HotSpot VM的自動記憶體管理系統要求物件起始地址必須是8位元組的整數倍,換句話說,就是物件的大小必須是8位元組的整數倍。而物件頭部分正好是8位元組的倍數(1倍或者2倍),因此,當物件例項資料部分沒有對齊時,就需要通過對齊填充來補全。
物件大小計算
要點 1. 在32位系統下,存放Class指標的空間大小是4位元組,MarkWord是4位元組,物件頭為8位元組。 2. 在64位系統下,存放Class指標的空間大小是8位元組,MarkWord是8位元組,物件頭為16位元組。 3. 64位開啟指標壓縮的情況下,存放Class指標的空間大小是4位元組,MarkWord是8位元組,物件頭為12位元組。 陣列長度4位元組+陣列物件頭8位元組(物件引用4位元組(未開啟指標壓縮的64位為8位元組)+陣列markword為4位元組(64位未開啟指標壓縮的為8位元組))+對齊4=16位元組。 4. 靜態屬性不算在物件大小內。
補充:
HotSpot物件模型
HotSpot中採用了OOP-Klass模型,它是描述Java物件例項的模型,它分為兩部分:
- 類被載入到記憶體時,就被封裝成了klass,klass包含類的元資料資訊,像類的方法、常量池這些資訊都是存在klass裡的,你可以認為它是java裡面的java.lang.Class物件,記錄了類的全部資訊;
- OOP(Ordinary Object Pointer)指的是普通物件指標,它包含MarkWord 和元資料指標,MarkWord用來儲存當前指標指向的物件執行時的一些狀態資料;元資料指標則指向klass,用來告訴你當前指標指向的物件是什麼型別,也就是使用哪個類來創建出來的;
- 那麼為何要設計這樣一個一分為二的物件模型呢?這是因為HotSopt JVM的設計者不想讓每個物件中都含有一個vtable(虛擬函式表),所以就把物件模型拆成klass和oop,其中oop中不含有任何虛擬函式,而klass就含有虛擬函式表,可以進行method dispatch。
HotSpot中,OOP-Klass實現的程式碼都在/hotspot/src/share/vm/oops/路徑下,oop的實現為instanceOop 和 arrayOop,他們來描述物件頭,其中arrayOop物件用於描述陣列型別。
以下就是oop.hhp檔案中oopDesc的原始碼,可以看到兩個變數_mark就是MarkWord,_metadata就是元資料指標,指向klass物件,這個指標壓縮的是32位,未壓縮的是64位;
volatile markOop _mark; //標識執行時資料
union _metadata {
Klass* _klass;
narrowKlass _compressed_klass;
} _metadata; //klass指標
一個Java物件在記憶體中的佈局可以連續分成兩部分:instanceOop(繼承自oop.hpp)和例項資料;
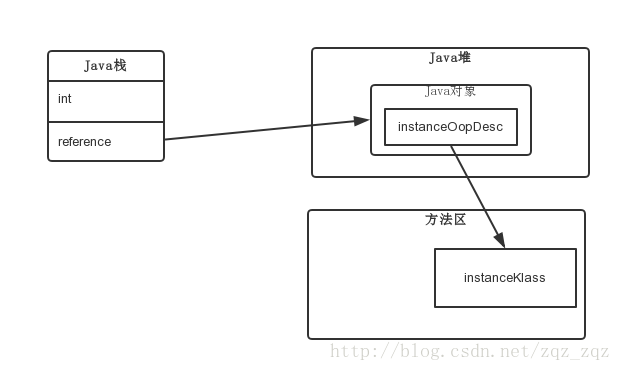
上圖可以看到,通過棧幀中的物件引用reference找到Java堆中的物件,再通過物件的instanceOop中的元資料指標klass來找到方法區中的instanceKlass,從而確定該物件的型別。
下面來分析一下,執行new A()的時候,JVM 做了什麼工作。首先,如果這個類沒有被載入過,JVM就會進行類的載入,並在JVM內部建立一個instanceKlass物件表示這個類的執行時元資料(相當於Java層的Class物件)。初始化物件的時候(執行invokespecial A::),JVM就會建立一個instanceOopDesc物件表示這個物件的例項,然後進行Mark Word的填充,將元資料指標指向Klass物件,並填充例項變數。
元資料—— instanceKlass 物件會存在元空間(方法區),而物件例項—— instanceOopDesc 會存在Java堆。Java虛擬機器棧中會存有這個物件例項的引用。
成員變數重排序
為了提高效能,每個物件的起始地址都對齊於8位元組,當封裝物件的時候為了高效率,物件欄位宣告的順序會被重排序成下列基於位元組大小的順序:
- double (8位元組) 和 long (8位元組)
- int (4位元組) 和 float (4位元組)
- short (2位元組) 和 char (2位元組):char在java中是2個位元組。java採用unicode,2個位元組(16位)來表示一個字元。
- boolean (1位元組) 和 byte (1位元組)
- reference引用 (4/8 位元組)
- <子類欄位重複上述順序>
子類欄位重複上述順序。 我們可以測試一下java對不同型別的重排序,使用jdk1.8,採用反射的方式先獲取到unsafe類,然後獲取到每個field在類裡面的偏移地址,就能看出來了 測試程式碼如下:
import java.lang.reflect.Field;
import sun.misc.Contended;
import sun.misc.Unsafe;
public class TypeSequence {
@Contended
private boolean contended_boolean;
private volatile byte a;
private volatile boolean b;
@Contended
private int contended_short;
private volatile char d;
private volatile short c;
private volatile int e;
private volatile float f;
@Contended
private int contended_int;
@Contended
private double contended_double;
private volatile double g;
private volatile long h;
public static Unsafe UNSAFE;
static {
try {
@SuppressWarnings("ALL")
Field theUnsafe = Unsafe.class.getDeclaredField("theUnsafe");
theUnsafe.setAccessible(true);
UNSAFE = (Unsafe) theUnsafe.get(null);
} catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws NoSuchFieldException, SecurityException{
System.out.println("e:int \t"+UNSAFE.objectFieldOffset(TypeSequence.class.getDeclaredField("e")));
System.out.println("g:double \t"+UNSAFE.objectFieldOffset(TypeSequence.class.getDeclaredField("g")));
System.out.println("h:long \t"+UNSAFE.objectFieldOffset(TypeSequence.class.getDeclaredField("h")));
System.out.println("f:float \t"+UNSAFE.objectFieldOffset(TypeSequence.class.getDeclaredField("f")));
System.out.println("c:short \t"+UNSAFE.objectFieldOffset(TypeSequence.class.getDeclaredField("c")));
System.out.println("d:char \t"+UNSAFE.objectFieldOffset(TypeSequence.class.getDeclaredField("d")));
System.out.println("a:byte \t"+UNSAFE.objectFieldOffset(TypeSequence.class.getDeclaredField("a")));
System.out.println("b:boolean\t"+UNSAFE.objectFieldOffset(TypeSequence.class.getDeclaredField("b")));
System.out.println("contended_boolean:boolean\t"+UNSAFE.objectFieldOffset(TypeSequence.class.getDeclaredField("contended_boolean")));
System.out.println("contended_short:short\t"+UNSAFE.objectFieldOffset(TypeSequence.class.getDeclaredField("contended_short")));
System.out.println("contended_int:int\t"+UNSAFE.objectFieldOffset(TypeSequence.class.getDeclaredField("contended_int")));
System.out.println("contended_double:double\t"+UNSAFE.objectFieldOffset(TypeSequence.class.getDeclaredField("contended_double")));
}
}
以上程式碼執行結果如下
e:int 12
g:double 16
h:long 24
f:float 32
c:short 38
d:char 36
a:byte 40
b:boolean 41
contended_boolean:boolean 170
contended_short:short 300
contended_int:int 432
contended_double:double 568除了int欄位跑到了前面來了,還有兩個添加了contended註解的欄位外,其它欄位都是按照重排序的順序,型別由最長到最短的順序排序的;
物件頭對成員變數排序的影響
有的童鞋疑惑了,為啥int跑到前面來了呢?這是因為int欄位被提升到前面填充物件頭了,物件頭有12個位元組,會優先在欄位中選擇一個或多個能夠將物件頭填充為16個位元組的field放到前面,如果填充不滿,就加上padding,上面的例子加上一個4位元組的int,正好是16位元組,地址按8位元組對齊;
擴充套件contended對成員變數排序的影響
那麼contended註解呢?這個註解是為了解決cpu快取行偽共享問題的,cpu快取偽共享是併發程式設計效能殺手,不知道什麼是偽共享的可以檢視我前面寫的LongAdder類的原始碼解讀 或者《java 中的鎖 – 偏向鎖、輕量級鎖、自旋鎖、重量級鎖》這篇文章都有講到,加了contended註解的欄位會按照宣告的順序放到末尾,contended註解如果是用在類的field上會在該field前面插入128位元組的padding,如果是用在類上則會在類所有field的前後都加上128位元組的padding。