
[譯] Async IO on Linux: select, poll, and epoll
雖然一直是個 Java 程式設計師,但是 select、poll、epoll 這些詞彙還是經常聽見的,上次寫完 UNIX I/O 之後又去再看了一下這部分內容,遇到了這篇文章,感覺不錯特此翻譯下來,下面是正文。
Chapter63:Alternative I/O models
章節內容主要關於當新的資料輸入/輸出到來時,如何監聽如此多的檔案描述符呢?誰需要同時關注這麼多的檔案描述符呢?答案是 Server。
例如,你在 Linux 上用 node.js 寫一個 web server,實際上它會使用 epoll 系統呼叫。讓我們談談 epoll 和 select、poll 的區別在哪裡,和它們是如何工作的。
Servers need to watch a lot of file descriptors
假設你是一個 web server,每次你使用 accept 系統呼叫接收一個連線時,你會得到一個新的檔案描述符來表示那個連線。
作為一個 web server,同一時間你可能有成千上萬的連線。你需要知道何時某個連線有新的資料需要發給你,這樣你才能處理請求並返回響應。
怎樣監聽這些檔案描述符呢?你可能會用下面的迴圈方式:
for x in open_connections:
if has_new_input(x):
process_input(x)
上述程式碼的問題是,它會浪費許多 CPU。與其消耗所有 CPU 時間去詢問:“有資料更新麼?現在呢?現在呢?現在有麼?”,我們還不如直接告訴核心,“現在有 100 個檔案描述符,當其中一個有資料更新時通知我。”
有三個系統呼叫方法可以讓你達到告知 Linux 核心去監聽檔案描述符的目的,它們分別是 poll、epoll 和 select,讓我們先從 poll 和 select 開始,因為章節內容就是從他倆先開始的。
First way: select & poll
這兩個系統呼叫在任何 UNIX 系統中都有,而 epoll 是 Linux 獨佔的。他倆的工作原理是:
- 傳給它們一堆等待資料的檔案描述符
- 它們會回答你,其中哪個檔案描述符對應的資料準備好,可以讀寫了它們會回答你,其中哪個檔案描述符對應的資料準備好,可以讀寫了
我從書裡學到的第一個令人驚訝的事實是,poll 和 select 的程式碼幾乎是相同的!我去看了一下 Linux 核心原始碼中關於 poll
select 的定義之後確信這是真的。
它倆都呼叫了很多相同的函式,書裡特別提到的是 poll 返回了一堆可能的 fd 集合例如
POLLRDNORM | POLLRDBAND | POLLIN | POLLHUP | POLLERR
而 select 僅僅告知你
there’s input / there’s output / there’s an error
相比於 poll 返回的更具體的結果,例如 fd 集合,select 僅僅返回粗粒度的資訊,例如“你可以讀取資訊了”。你可以自己閱讀這部分功能的具體程式碼。
我從書中學習到的另一個事實是,在檔案描述符稀少的情況下,poll 的效能比 select 更好。為了證明這點,你可以看看 poll 和 select 的方法簽名:
int ppoll(struct pollfd *fds, nfds_t nfds,
const struct timespec *tmo_p, const sigset_t
*sigmask)`
int pselect(int nfds, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, const struct timespec *timeout,
const sigset_t *sigmask);
poll 方法中,你告訴它 “這是我想監聽的檔案描述符:1,3,8,19 等等” (即是 pollfd 引數)。select 方法中,你告訴它 “我希望監聽 19 個檔案描述符,我關心其中某個fd的三種(read/write/exception)狀態變更(select 使用三個點陣圖來表示三個 fdset)” 所以當 select 執行時,它會輪詢這 19 個檔案描述符,即使你只關心其中幾個。
書中還有許多 poll 和 select 不同的細節,但是這兩點是我學到的最主要的。
why don’t we use poll and select ?
但是,我們說了你的 nods.js web 伺服器不會使用 select 或者 poll,而是使用 epoll,這是為什麼呢?
從書中可得:
每次呼叫 select 或者 poll,核心必須檢查所有上述的檔案描述符來發現它們是否準備好了。當監聽的檔案描述符數量非常多、範圍非常大時,耗時就會很誇張、效能自然也不好。
總結看就是核心不會記錄它應該監聽的檔案描述符列表。
Signal-driven I/O (is this a thing people use ?)
書中描述了兩種通知核心記錄監聽檔案描述符列表的方式:訊號驅動式 I/O 和 epoll。訊號驅動式 I/O 讓核心在一個檔案描述符更新資料時,通過呼叫 fcntl 返回一個訊號給你。我從沒聽過任何人使用這個,書中敘述看上去就認為 epoll 是更好的,所以我們乾脆就直接忽略了,來談談 epoll 吧。
level-triggered vs edge-triggered
在我們談論 epoll 時,我們先來討論一下 “level-triggered” 和 “edge-triggered” 兩種檔案描述符通知模式。我之前從沒聽過這種專業術語(可能來自於電子工程界?)總結起來,接受通知有兩種方式:
- 拿到每個可讀的且是你感興趣的 fd 的列表(
level-triggered) - 每當一個 fd 可讀時就收到一個通知(
edge-triggered)
what’s epoll ?
好,我們可以來講講 epoll 了。我很興奮,因為之前我瀏覽程式碼經常見到 epoll_wait,我經常困惑它到底有什麼作用。
epoll 類的系統呼叫(epoll_create, epoll_ctl, epoll_wait)給予了 Linux 核心檔案描述符來跟蹤和檢查資料更新的功能。
下面是使用 epoll 的步驟:
- 呼叫
epoll_create告訴核心你將要 epolling 了!它會返回你一個 id - 呼叫
epoll_ctl來告訴核心你關心哪些檔案描述符。有趣的是,你可以傳進許多檔案描述符(pipes,FIFOs,sockets,POSIX message queues,inotify instances,devices & more),但不是有規律的檔案。我覺得是合理的 —— pipes & sockets 的 API 很簡單(一個處理對 pipe 的寫,一個處理讀),所以可以說 “這個 pipe 有新的資料可以讀” 。但檔案是另類的,你可以朝一個檔案的中間寫入資料!所以你不能簡單的說 “該檔案有新的資料可以讀取”。 - 呼叫
epoll_wait來等待你關心的檔案有資料更新
performance: select & poll vs epoll
書中有個表格比較了監聽十萬個操作下的效能優劣:
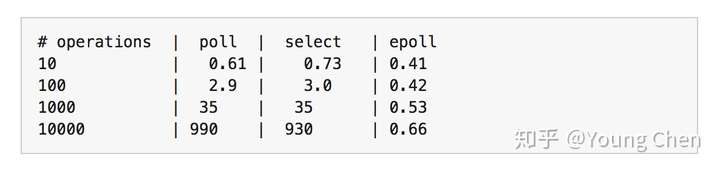 所以當你需要監聽大於 10 個 fd 時,使用 epoll 確實會快很多。
所以當你需要監聽大於 10 個 fd 時,使用 epoll 確實會快很多。