
第6天資料型別之元組,字典,集合
元組(不可變,有序,多個值)
元組型別就是一個不可變的列表,為什麼會有元組呢?因為在我們寫程式的過程中可能會出現這樣的一個情況,也就是為了防止一些不必要的bug,一些重要的資料別人是可以讀取的,但是不能夠進行更改,這個時候我們就需要用到元組了。對於列表而言,python中對於元祖的儲存相對來說更為儲存空間的。(因為它不必再像列表一樣維護更改操作了)
既然元組本身就是一個不可變的列表了,那它的除了修改列表的操作之外的一些操作和列表是完全一樣的,此處就不再陳述了,但是此處我要說的是元組的不可變究竟指的是什麼不可變?例如下面的操作:
tuple1 = ('a', 'b', 'c', ['a', 'b', 'c']) print(tuple1) tuple1[3].append('d') print(tuple1) 結果: ('a', 'b', 'c', ['a', 'b', 'c']) ('a', 'b', 'c', ['a', 'b', 'c', 'd']) # 不是說元組不可變嗎,為什麼此處還是可以對元組進行新增資料呢
這個現象的原因是因為無論是列表還是元組存放值得時候並不是把裡面的內容直接存放到了列表或者元組中,而是把這些值對應的記憶體空間放在了元組中,我們通常所說的不改變元組也就是指不改變元組記憶體儲的記憶體空間地址而已。如上面的例子,tuple1更改的是元組中最後一項列表的值,但是對於列表而言是一個可變的型別,就算是裡面的值增加了一個,它的記憶體地址是不會改變的,因此存在元組中的記憶體地址也就不會發生改變了。
元組的方法(和列表是一樣的)
index取對應的索引值,沒有就報錯
count,得到對應元素的個數
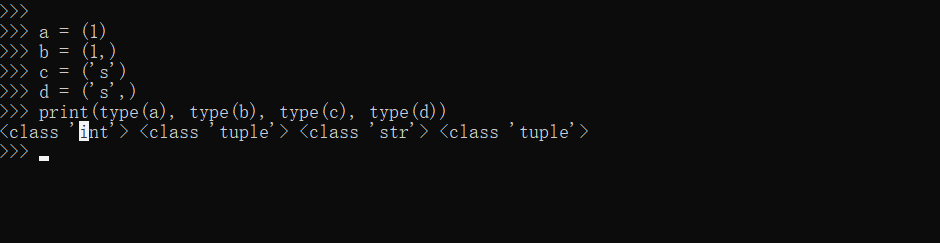
元組需要注意的地方:元組內如果只有一個內容的話,需要加上逗號,否則就是包含的意思。如下圖
元組練習:
#簡單購物車,要求如下: 實現列印商品詳細資訊,使用者輸入商品名和購買個數,則將商品名,價格,購買個數加入購物列表,如果輸入為空或其他非法輸入則要求使用者重新輸入 msg_dic={ 'apple':10, 'tesla':100000, 'mac':3000, 'lenovo':30000, 'chicken':10, }


''' #簡單購物車,要求如下: 實現列印商品詳細資訊,使用者輸入商品名和購買個數,則將商品名,價格, 購買個數加入購物列表,如果輸入為空或其他非法輸入則要求使用者重新輸入 msg_dic={ 'apple':10, 'tesla':100000, 'mac':3000, 'lenovo':30000, 'chicken':10, }實現程式碼''' msg_dic={ 'apple':10, 'tesla':100000, 'mac':3000, 'lenovo':30000, 'chicken':10, } # 購物列表 shop_list = [] for key, value in msg_dic.items(): print('{name}, {price} |'.format(name=key, price=value), end=' ') print() temp_info = '請' while True: shop_name = input(temp_info + '輸入商品名稱:').strip() if shop_name not in msg_dic: print('您輸入的商品不存在!') temp_info = '請重新' continue break temp_info = '請' while True: shop_count = input(temp_info + '請輸入商品個數:').strip() if not shop_count.isdigit(): print('您輸入的有誤!') temp_info = '請重新' continue shop_count = int(shop_count) break shop_list.append((shop_name, shop_count, msg_dic[shop_name])) print('您的購物車為:') print(shop_list)
字典(可變,多個值,無序)
字典的定義(字典的key必須是不可變型別,value可以是任意型別)
a = {'name': 'hu', 'age': 18} # ==> a = dict({'name': 'hu', 'age': 18})
a = {1 : [], 1.1: [], 'name': [], (1,2,3): []} # 這個是正確的定義方式
a = {1 : [], 1.1: [], 'name': [], (1,2,3): [], [1,2,3]: 1} # 這個是錯誤的,因為key中有列表,列表是可變型別
字典的轉換
a = dict([('name', 'hu'), ('age', 18)]) # 只能轉換如下型別的,一個列表或者元組裡麵包含一個個的小元組的情況,並且小元組裡面只有兩個值,一個代表key,一個代表value b = dict((('name', 'hu'), ('age', 18))) print(a, b)
字典的取值(因為字典是無序的,因此字典本身是不能通過索引進行取值的,更不能切片)
# 列表是不能通過索引直接賦值的方式新增的,但是字典是可以的a = {'name': 'hu', 'age': 18}
res = a['name'] # 如果有key,就是把值直接取出來
print(res)
a['sex'] = 'male' # 如果沒有,就是直接在字典中新增key和value
print(a)
字典的方法
keys, values, items,對於python2和python3此方法的返回值是不一樣的,python3返回的是一個列表的生成器,而python2是直接把字典的key,value已經items直接以列表的形式返回回來了。這對於一些比較大的資料字典而言,python3明顯要比python2更加的節省記憶體。

clear, copy函式
a = {'name': 'hu', 'age': 18}
b = a.copy() # 完整的複製一個字典
a.clear() # 把字典給清空掉
print(a, b)
update更新方法
# update方法,update裡面的引數可以是字典{},也可以是以下形式的列表[(), ()] # 如果更新的內容原字典中是有的,就直接更新,如果沒有,就新增 a = {'name': 'hu', 'age': 18} a.update({'name': 'agon', 'sex': 'male'}) print(a) # 結果: # {'name': 'agon', 'age': 18, 'sex': 'male'}
setdefault方法
# setdefault有兩個引數,第一個引數是key,如果key在原字典中存在,則直接返回原字典對應的key的值 # 如果原字典中key不存在,則新增key到原字典中,value的值為第二個引數,並且返回第二個引數 a = {'name': 'hu', 'age': 18} res = a.setdefault('sex', None) print(a, res) # 結果: # {'name': 'hu', 'age': 18, 'sex': None} None
pop, popitem刪除方法
# pop根據key去刪除相應的鍵值對,返回對應的key的值,如果key不存在會報錯 # popitem隨機的刪除一個鍵值對,以元組的形式返回這個鍵值對,如果字典為空也會報錯 a = {'name': 'hu', 'age': 18} res1 = a.pop('name') print(res1) res2 = a.popitem() print(res2) #結果: # hu # ('age', 18)
fromkeys方法
#fromkeys可以通過已經給定的key快速的建立一個初始化的字典 res1 = {}.fromkeys('str', None) res2 = {}.fromkeys(['name', 'age', 'sex'], None) print(res1) print(res2) # 結果 # {'s': None, 't': None, 'r': None} # {'name': None, 'age': None, 'sex': None}
get方法
# 通過a['name']也是可以得到字典的值得,但是當key不存在的時候會報錯,所以我們一般通過get方法去得到相應的值a = {'name': 'hu', 'age': 18}
res1 = a.get('name')
res2 = a.get('sex') # 如果字典中不存在,不會報錯,會返回一個None
print(res1, res2)
結果:
hu None
字典練習:
1. 有如下值集合 [11,22,33,44,55,66,77,88,99,90...],將所有大於 66 的值儲存至字典的第一個key中,將小於 66 的值儲存至第二個key的值中
''' 1 有如下值集合 [11,22,33,44,55,66,77,88,99,90...],將所有大於 66 的值儲存至字典的第一個key中,將小於 66 的值儲存至第二個key的值中 即: {'k1': 大於66的所有值, 'k2': 小於66的所有值} ''' a = [11,22,33,44,55,66,77,88,99,90] di = {} for i in a: if i > 66: di.setdefault('k1', []) di['k1'].append(i) if i < 66: di.setdefault('k2', []) di['k2'].append(i) print(di)解題
2. 統計s='hello alex alex say hello sb sb'中每個單詞的個數
''' 2 統計s='hello alex alex say hello sb sb'中每個單詞的個數 結果如:{'hello': 2, 'alex': 2, 'say': 1, 'sb': 2} ''' d = {} s = 'hello alex alex say hello sb sb' for word in s.split(): d.setdefault(word, s.count(word)) print(d)解題程式碼1通過setdefault
''' 2 統計s='hello alex alex say hello sb sb'中每個單詞的個數 結果如:{'hello': 2, 'alex': 2, 'say': 1, 'sb': 2} ''' d = {} s = 'hello alex alex say hello sb sb' s_set = set(s.split()) for word in s_set: d[word] = s.count(word) print(d)通過set集合減少迴圈的次數
集合(可變,無序,存多個值)
集合的定義
# 集合定義的過程需要注意的 # 1. 值必須是不可變型別 # 2. 沒有重複 # 3. 沒有順序 a = {1, 1.1, 'str', (1, 2)} # ==>a = set({1, 1.1, 'str', (1, 2)})
集合的轉換
# 集合的轉換過程 # 1.轉換的必須是可迭代型別 # 2.轉換的值中不能包含有可變型別 a1 = set('str[1,2,3]') a2 = set((1,2)) a3 = set([1, 2, 3]) # a3 = set([1, 2, [1,2,3]]) # 這個是錯誤的 a4 = set({'a': 1, 'b': 2, 'c': [1, 2, 3]}) print(a1, a2, a3, a4)
集合運算
# 集合有交集,並集,差集,對稱差集,父子關係,相等 pythons = {'hu', 'zhou', 'zhang', 'li', 'yang'} linuxs = {'hu', 'li', 'yang', 'xiao', 'chen', 'ti', 'bai'} # 交集 print(pythons & linuxs) print(pythons.intersection(linuxs)) # 並集 print(pythons | linuxs) print(pythons.union(linuxs)) # 差集 print(pythons - linuxs) # 在python中但是不在Linux中 print(linuxs - pythons) # 在linux中但是不在python中 print(pythons.difference(linuxs)) print(linuxs.difference(pythons)) # 對稱差集 print(pythons ^ linuxs) print(pythons.symmetric_difference(linuxs)) # 相等 print(pythons == linuxs) # 父子 print(pythons >= linuxs) # 判斷pythons是否包含linuxs
集合方法
a = {1, 2, 3}
# 新增
a.add(4) # 新增的值如果存在,就不變
print(a)
# 刪除
a.pop() # 隨機刪除
a.remove(3) # 刪除元素,必須存在
a.discard(3) # 元素如果存在則刪除,如果不存在,就不變
# 更新
b = {1, 4, 5}
a.update(b) # 有則不變,沒有則新增
print(a)
res = a.isdisjoint(b) # 如果兩個集合沒有交集,則返回True,否則Flase
print(res)
集合的練習
1. 第一題
一.關係運算 有如下兩個集合,pythons是報名python課程的學員名字集合,linuxs是報名linux課程的學員名字集合 pythons={'alex','egon','yuanhao','wupeiqi','gangdan','biubiu'} linuxs={'wupeiqi','oldboy','gangdan'} 1. 求出即報名python又報名linux課程的學員名字集合 2. 求出所有報名的學生名字集合 3. 求出只報名python課程的學員名字 4. 求出沒有同時這兩門課程的學員名字集合
pythons={'alex','egon','yuanhao','wupeiqi','gangdan','biubiu'}
linuxs={'wupeiqi','oldboy','gangdan'}
# 1. 求出即報名python又報名linux課程的學員名字集合
print(pythons.intersection(linuxs))
# 2. 求出所有報名的學生名字集合
print(pythons.update(linuxs))
# 3. 求出只報名python課程的學員名字
print(pythons.difference(linuxs))
# 4. 求出沒有同時這兩門課程的學員名字集合
print(pythons.symmetric_difference(linuxs))
答案
2. 第二題
二.去重 1. 有列表l=['a','b',1,'a','a'],列表元素均為可hash型別,去重,得到新列表,且新列表無需保持列表原來的順序 2.在上題的基礎上,儲存列表原來的順序 3.去除檔案中重複的行,肯定要保持檔案內容的順序不變 4.有如下列表,列表元素為不可hash型別,去重,得到新列表,且新列表一定要保持列表原來的順序 l=[ {'name':'egon','age':18,'sex':'male'}, {'name':'alex','age':73,'sex':'male'}, {'name':'egon','age':20,'sex':'female'}, {'name':'egon','age':18,'sex':'male'}, {'name':'egon','age':18,'sex':'male'},
# 1. 有列表l=['a','b',1,'a','a'],列表元素均為可hash型別,去重,得到新列表,且新列表無需保持列表原來的順序 l = ['a', 'b', 1, 'a', 'a'] new_l = list(set(l)) print(new_l) # 2.在上題的基礎上,儲存列表原來的順序 new_l = [] for l_item in l: if l_item not in new_l: new_l.append(l_item) print(new_l) # 3.去除檔案中重複的行,肯定要保持檔案內容的順序不變 # 4.有如下列表,列表元素為不可hash型別,去重,得到新列表,且新列表一定要保持列表原來的順序 l=[ {'name':'egon','age':18,'sex':'male'}, {'name':'alex','age':73,'sex':'male'}, {'name':'egon','age':20,'sex':'female'}, {'name':'egon','age':18,'sex':'male'}, {'name':'egon','age':18,'sex':'male'}, ] new_l = [] for l_item in l: if l_item not in new_l: new_l.append(l_item) print(new_l)答案
作業1
列印省、市、縣三級選單
可返回上一級
可隨時退出程式
menu = { '北京': { '海淀': { '五道口': { 'soho': {}, '網易': {}, 'google': {} }, '中關村': { '愛奇藝': {}, '汽車之家': {}, 'youku': {}, }, '上地': { '百度': {}, }, }, '昌平': { '沙河': { '老男孩': {}, '北航': {}, }, '天通苑': {}, '回龍觀': {}, }, '朝陽': {}, '東城': {}, }, '上海': { '閔行': { "人民廣場": { '炸雞店': {} } }, '閘北': { '火車戰': { '攜程': {} } }, '浦東': {}, }, '山東': {}, } ''' #要求: 列印省、市、縣三級選單 可返回上一級 可隨時退出程式 ''' flag = True # 用來控制是否退出程式 while flag: # 第一層 for key in menu: print(key) choice = input('第一層>>: ').strip() if choice == 'b': continue if choice == 'q': flag = False print('退出!') break if choice not in menu: print('請重新輸入!') continue while flag: menu_2 = menu[choice] for key in menu_2: print(key) choice2 = input('第二層>>: ').strip() if choice2 == 'b': break if choice2 == 'q': flag = False print('退出!') break if choice2 not in menu_2: print('請重新輸入!') continue while flag: menu_3 = menu[choice][choice2] for key in menu_3: print(key) choice3 = input('第三層>>: ').strip() if choice3 == 'b': break if choice3 == 'q': flag = False print('退出!') break if choice3 not in menu_3: print('請重新輸入!') continue while flag: menu_4 = menu[choice][choice2][choice3] for key in menu_4: print(key) choice4 = input('第四層>>: ').strip() if choice4 == 'b': break if choice4 == 'q': flag = False print('退出!') break if choice4 not in menu_4: print('請重新輸入!') continue普通邏輯板
menu = { '北京':{ '海淀':{ '五道口':{ 'soho':{},