
Apache Kafka的Exactly-once的定義 原理和實現
2018年,Apache Kafka以一種特殊的設計和方法實現了強語義的exactly-once和事務性。熱淚盈眶啊!
這篇文章將講解kafka中exactly-once和事務操作的原理,具體為
- (1)exactly-once在kafka中的定義。
- (2)資料生產者“冪等操作”,kafka的事務性以及exactly-once實現原理。
- (3)exactly-once的流處理。
1. 什麼是恰好一次exactly-once
exactly-once定義為: 不管在處理的時候是否有錯誤發生,計算的結果(包括所有所改變的狀態)都一樣。
所以,在計算的時候如果發生了一個錯誤,系統重新計算,重新計算的結果和沒有錯誤發生所得到的結果是一樣的,因為這些計算操作是“恰好一次的”。這有另外一個專業術語:“冪等操作”。
為什麼exactly-once那麼重要呢?(1)在流處理操作中,很多應用場景必須需要“恰好一次”的支援。比如生活著有一個很重要的使用場景:在轉賬給朋友的時候,使用者只希望一次轉賬,如果不支援“恰好一次”,那麼就無法保障在違背使用者本意的情況下重複轉賬。(2)對於kafka而言,其是流處理平臺的核心部件,因為kafka通常作為公司內部的訊息系統中介軟體,是其他系統的訊息傳輸的橋樑。(3)支援exactly-once操作可以解鎖更過的應用,比如金融行業應用。
使用Kafka進行流處理通常主要包含三個步驟:根據topic讀取資料 - 流操作 - 將結果儲存到指定的topic下。Kafka的流處理支援無狀態的流操作(stateless)和有狀態的流操作(stateful),無狀態的意思是流處理的時候只需要針對某一條訊息進行處理,結果只受到這條訊息的影響,比如在每一條訊息後面追加字元“a”;有狀態指的是在訊息處理的時候需要儲存前後多條訊息的相關資訊,結果受到多條訊息的影響,比如count,average操作。所以有狀態操作更加強大但是實現起來更加困難,特別是當它也支援“恰好一次”的時候。

如果不支援exactly-once操作,那麼可能出現下面的錯誤:
(1)重複寫入。下圖所示左邊為輸入資料,中間為資料處理,右邊是結果寫入。現在計算出了結果並且成功寫入,但是由於某些原因,系統沒有正確識別成功寫入結果這個訊號,所以系統重試了,這樣就導致了下面第二張圖所示的結果:也就是計算結果重複寫入。
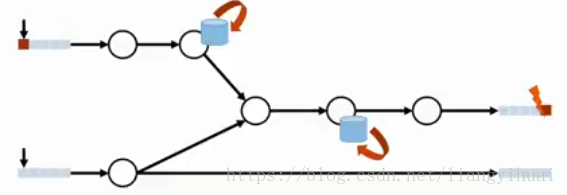
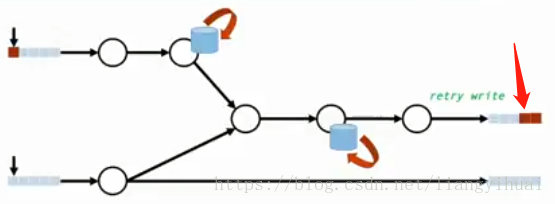
(2)計算狀態被多次更新。
如下圖所示,箭頭所指的是一個有狀態的操作(前面已經講到無狀態操作和有狀態操作),第一次計算的時候更新了該處的狀態。那麼如果因為某些原因第一次的計算有問題需要重新計算,箭頭所指的狀態會被再次更新,從而導致最終的計算結果不正確。因為正確的計算是狀態只被更新一次。這裡所說的狀態似乎有一點抽象,舉一個例子,在統計操作中,count++,可以表示成一個狀態,每次來一個數據,就增加1個量。
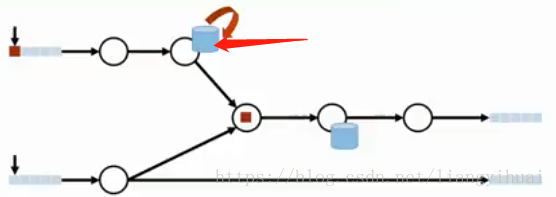
(3)重複讀入
第一個資料已經順利讀取,處理和結果寫入,但是由於資料讀取的原因,系統沒有正確識別到第一次資料的讀取,所以再次讀取了相同的資料,再次計算並輸出結果。此時如下面第二張圖所示。這樣同樣的輸入資料就產生了兩個結果寫入,而且如果中間的流操作是有狀態的,這兩個結果很可能是不一樣的。
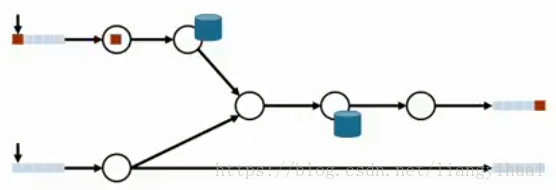
上面所闡述的問題,進一步說明了exactly-once的重要性。kafka提供了自己的exactly-once保證。
2. 要麼都做,要麼都不做
要麼都做,要麼都不做。做什麼呢?體現在:(1)寫出所有的計算結果 (計算結果寫入到kafka指定的topic中).(2)所有狀態的更新。(3)把輸入的訊息標記為已消費(這裡的輸入資料理解為kafka的消費者從broker中pull資料)。對上面這三個,kafka使用另一種具有相同語義的方式表示,分別為:(1)將計算結果寫入輸出topic中(2)把更新操作寫入“更新日誌changelog”中(注意,操作的狀態能夠根據“更新日誌”進行回滾,類似於MySQL的更新日誌,這個有別於普通的系統操作日誌)(3)把消費的訊息偏移量寫入相應的topic中。這也就是Apache Kafka實現“要麼都做,要麼都不做”和exactly-once的總體設計思路。
具體地,上面闡述關係到三個操作,分別為:

- 訊息生產者提交資料到broker
- broker進行訊息處理,
- 消費者消費資料
對於第一點,需要實現冪等操作以及多分割槽地原子寫入。這裡的“寫入”指的是訊息的producer向broker傳入訊息。這裡不多講“冪等”操作,可以簡單理解為同一個訊息,producer一次或者多次重複向broker傳輸,對broker的影響是一樣的。多分割槽原子寫入指的是,producer將多條訊息一次向broker中的多個partition傳輸,原子性體現在要麼這些訊息都成功傳入了,要麼都沒有傳入。
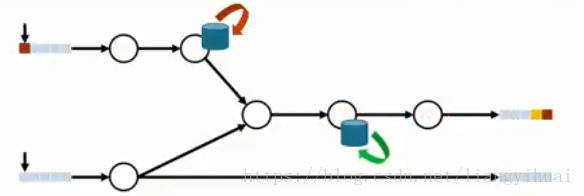
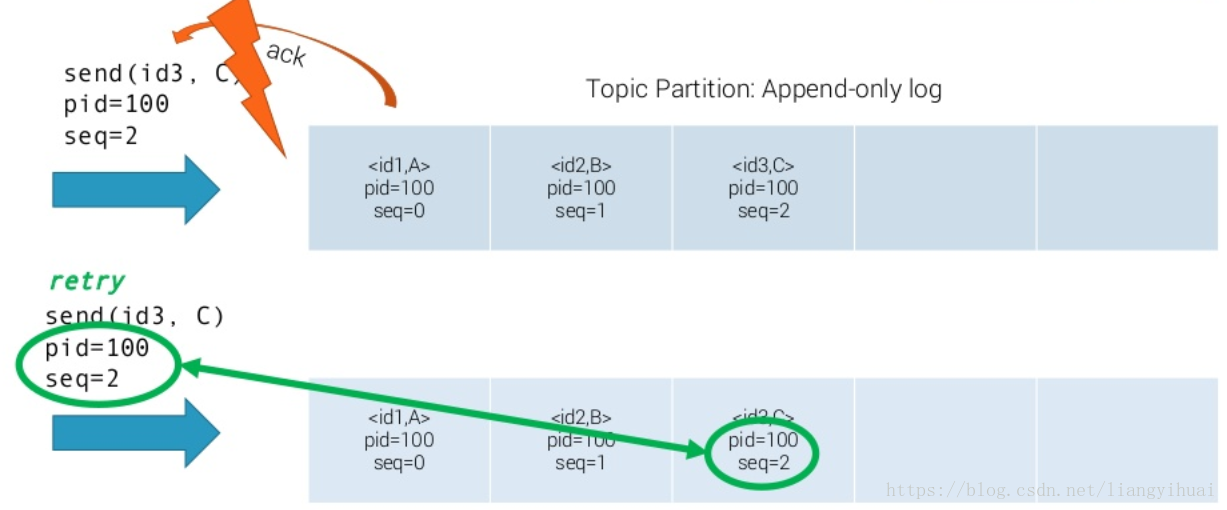
在下面第一張圖片中展示了kafka實現訊息傳輸的冪等操作的原理。每一條訊息除了訊息的key和訊息的值,還增加了兩個欄位,分別是producer的ID和一個全域性唯一的序列號。這個序列號由broker生成,類似於流水號。在圖片中,閃電錶示訊息的ack失敗,訊息重傳,kafka根據訊息的pid和seq來判斷這條訊息是否已經傳過。因為pid和seq也同訊息一樣存在kafka的patition中的,所以不需要當心丟失問題。要啟動kafka的冪等性,無需修改程式碼,預設為關閉,需要修改配置檔案:enable.idempotence=true 同時要求 ack=all 且 retries>1。
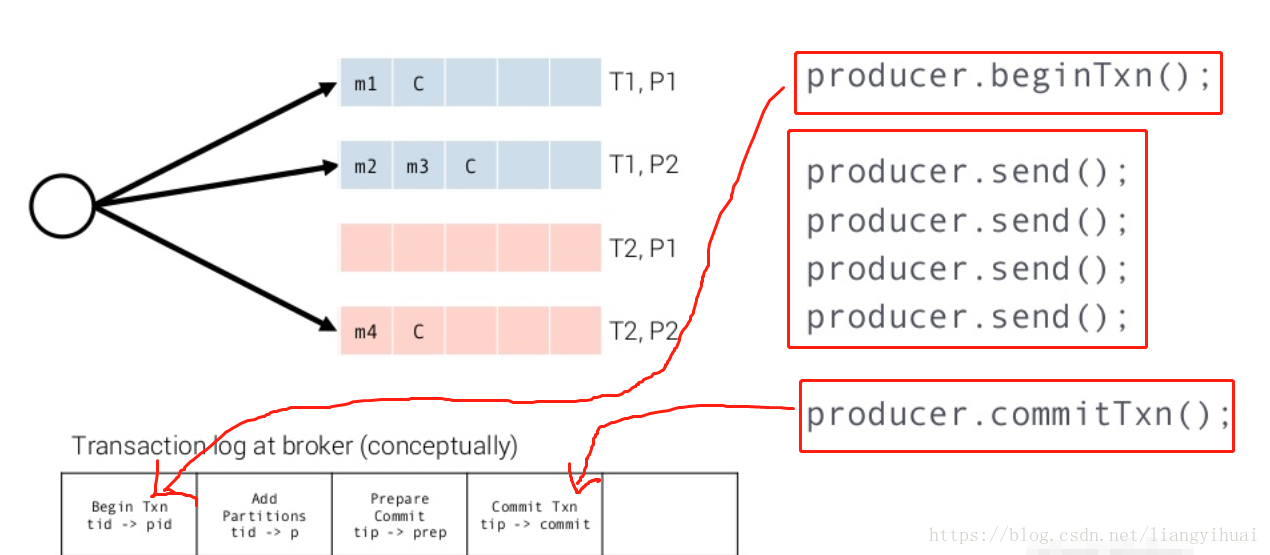
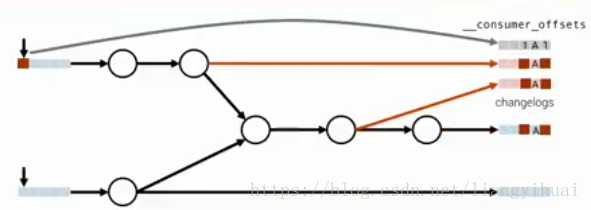
對於第二點,需要實現:將模式“訊息讀入->訊息處理->結果寫出”作為事務操作,並且整個操作滿足exactly-once。所謂的事務操作,也就是這個操作需要滿足原子性,完整性,一致性和永續性。kafka在支援事務性的同時也保證了系統性能,這體現在它簡單但是高效的設計和實現上面。下面分析kafka實現事務的原理。在下面第一張圖片中,左下角表示事務日誌,系統存在一個事務鎖,在某一個事務開始之前需獲取這個鎖。左上角的T1,T2表示兩個topic,P1和P2表示兩個partition,也就是這個事務往兩個不同的topic和兩個不同的partition上面儲存資料。看圖片的右上角,第一行程式碼,首先告訴系統要開始一個事務,接著傳送訊息到broker相應topic和partition中,所有都正常且完成之後,提交這個事務。所有的這個過程都另外有相應的log。只有成功完成了這個事務之後,消費者才能消費這個事務所提交的訊息。
實現事務的回滾需要藉助changelogs的幫助,如下面第一張圖片所示。changelogs是儲存在相應的topic中。

對於第三點,需要實現,kafka消費者只讀取已經標記為“成功提交”的資料,這句話隱含了另外一層意思,訊息提交的狀態有多種,而成功提交只是其中之一。這裡的“提交”指的是producer向broker提交的訊息。那麼什麼才能算是成功提交了呢?訊息被partition的leader和其所有的follower成功記錄了,才能算是成功提交了。成功提交所帶來的好處就是不怕斷電不怕機器故障,也就是高容錯性。下面圖片展示了kafka如何解決消費者重複讀的問題。(1)訊息的消費,(2)訊息的處理,(3)把訊息的處理結果傳送到某一個topic中和(4)把偏移量的傳送某一個topic中,它們被放到一個事務中,當所有這些成功之後,才能算是成功。注意到,消費者的偏移量是使用一個producer傳送的,也就是把偏移量當成了一種訊息在kafka叢集中儲存起來。這樣的話,只要這個事務完成了,那麼偏移量也成功儲存了。
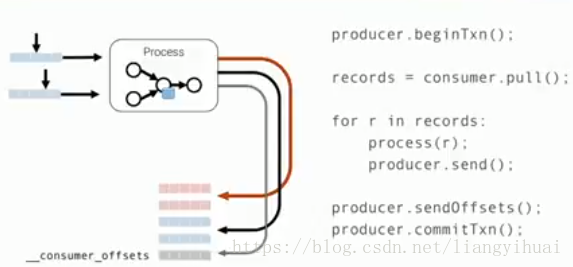
所以,對應下面第一張圖片,不僅僅有changelogs,還有__consumer_offsets
預設情況下kafka的事務是關閉的,通過配置檔案開啟,需要
transactional.id=“unique-id”, 要求enable.idempotence=true.
啟動exactly-once需要配置:processing.guarantee="exactly-once ", 預設是最少一次。
3. 髒資料
髒資料指的是producer把訊息資料提交到了broker中,但是它們沒有成功,此時這些資料依然存在broker中。為了避免讓消費者消費這些髒資料,kafka設定了訊息的隔離等級,可以通過配置檔案,指定只有成功提交的資料才能被消費。配置為isolation.level=“read_committed”。預設是read_uncommitted。
參考