
django框架--路由系統
目錄
一、路由系統理解
系統功能:根據使用者訪問的不同url,執行對應的檢視函式。
web伺服器可以根據使用者訪問的url地址的不同,返回相應的html頁面,而html的頁面渲染由檢視函式處理,這就需要有一個模組負責分析使用者訪問的url地址,並根據預先定義的對映規則,將請求分發到不同的檢視函式中進一步處理,負責這個工作的模組就是web框架中的路由系統。路由系統的工作總結起來就是:制定路由規則,分析url,分發請求到響應檢視函式中。
路由系統的路由功能基於路由表,路由表是預先定義好的url和檢視函式的對映記錄,換句話說,可以理解成將url和檢視函式做了繫結,對映關係有點類似一個python字典:
url_to_view_dic = {
'路徑1': view_func_1,
'路徑2': view_func_2,
'路徑n': view_func_n,
...
}路由表的建立是控制層面,需要在實際業務啟動前就準備完畢,即:先有路由,後有業務。 一旦路由準備完畢,業務的轉發將會完全遵從路由表的指導:
去往路徑1的request --> 被路由器分發到view_func_1函式處理 去往路徑2的request --> 被路由器分發到view_func_2函式處理 去往路徑n的request --> 被路由器分發到view_func_n函式處理 ...
二、路由系統功能劃分
路由系統的本質功能是:指路,針對一次路由請求,返回下一跳轉發地址。 任何路由系統都將涵蓋至少如下兩個核心功能:
路由器的核心功能:(非常重要!!!!) 1、建立路由表(控制層面) ----> 使用者定義 2、路由分發(轉發層面) ----> django框架自動處理
三、路由表建立
建立工具
django框架中的工具:re_path和path
所有的web請求都將以django專案目錄下的urls.py檔案作為路由分發主入口,所以如果要完成最簡單的路由功能,只需要在此檔案中預先配置好路由表即可。re_path是django v1的工具,path是django v2
# 專案urls.py檔案, 目前兩種工具可以任選使用
re_path(r'home/', views.index)
path('articles/<int:id>', views.show_article) 路由的匹配順序是自上而下,一旦匹配即執行對應檢視函式,便不再繼續匹配。 所以路由表條目的順序很重要,有嚴格要求的路徑應該放前面,寬鬆要求甚至可以聚合的路徑應該放後面。匹配成功後的檢視函式以如下形式執行:
# 執行介面: view_func(request, *args, **kw)
# 引數是固定的request物件以及由re_path或path捕獲的無名分組/有名分組引數
views.index(request)
views.show_article(request, id)如下是一張簡單的路由表配置:
# urls.py檔案
urlpatterns = [
# 自帶後臺管理頁面路由
path('admin/', admin.site.urls),
# 新增
re_path(r'^add/author/$', views.add_author),
re_path(r'^add/book/$', views.add_book),
# 刪除
re_path(r'delete/author/(\d+)', views.delete_author),
re_path(r'delete/book/(\d+)', views.delete_book),
# 修改
re_path(r'edit/author/(\d+)', views.edit_author),
re_path(r'edit/book/(\d+)', views.edit_book),
]特別注意1,django路由系統只會針對url進行匹配,並不會再額外考慮method或者其他request中的屬性,這也意味著僅僅只需考慮url即可。(當然,我覺得後續如有需要,可以增加匹配因子,以便做到更精準的匹配)
特別注意2,在瀏覽器中訪問某一個url,如果路徑結尾沒有新增/,在django框架中會被自動新增結尾的/。在路由表中,匹配路徑的時候要關注/,即:re_path(r'home/'),換句話說,可以認為在django的環境下,路徑pathinfo是必須有後導/的。
二級路由
二級路由的意思就是把專案urls檔案中的路由整理劃分,分佈到各自的應用目錄urls檔案中,以此實現:
1、降低專案urls路由檔案中路由數量,由各自應用urls路由檔案承擔
2、解耦整個專案的路由表,出現路由問題的時候可以單獨在二級路由表中處理
3、多級路由以樹形結構執行查詢,在路由數量很大的時候,可以比單路由表有更快的查詢速度
用include實現二級路由表,二級路由會將在一級路由匹配到的url截斷後再發送給子路由表繼續匹配。以如下一級路由表為例,如果伺服器收到一個http://www.xxx.com:8080/game/user/add/?name=a&pswd=b的請求,首先會匹配一級路由表中的game/並將截斷後的user/add/傳送到二級路由表繼續匹配。
re_path(r'game/', include('game_app.urls')),
re_path(r'chat/', include('chat_app.urls')),
re_path(r'vidio/', include('vidio_app,urls'),路由別名
因為路由url會被頻繁引用,所以會帶來修改時工作量過大的問題,解決辦法是啟用一個別名來代替url原始url,在所有引用的地方使用別名,這樣原始url不論如何修改,都會被正確指向。當然,這個前提是,別名不能發生修改,否則同樣要變動所有引用此別名的地方,所以別名的定義非常重要。此外,路由別名的作用域是全域性,它是一個全域性變數,這也意味著使用路由別名也有重名覆蓋的風險。
使用路由別名的目的是獲取原始url,如果原url有動態部分,需要在解析的時候傳入對應引數來明確動態部分。
路由別名重名覆蓋風險的解決方法:
1、在全域性urls中定義每一個二級路由的namespace
2、在每一個二級路由urls中定義app_name
3、在別名定義的時候加上區分字首如:app01-home, app02-home
別名的使用場景:
# 在模板中使用:
{% url '別名' *args, **kw %}
# 在檢視函式中使用:
reverse('別名', *args, **kw)動態路由及重定向
動態路由
所謂的動態路由,其實就是聚合大量同類的url,並用re規則執行匹配並獲取動態資料部分。
# re_path:
re_path(r'articles/(?P<id>\d+)'), show_article) ---> show_article(request, id=id)
# path:
path('articles/<int:id>', show_article) ---> show_article(request, id=id)重定向
return redirect(某一個具體網址,可來自於反向解析的結果)
四、自定義錯誤頁面
固定流程如下:
settings.py中DEBUG改為False,ALLOWD_HOSTS改為['*']
templates中新建對應的404.html, 500.html等
urls中定義:
handler404 = views.page_not_found
handler500 = views.server_errorviews中配置對應函式:
def page_not_found(request):
return render(request, '404.html')
def server_error(request):
return render(request, '500.html')五、圖示路由系統在框架中的定位
每次請求到伺服器,執行路由的流程圖
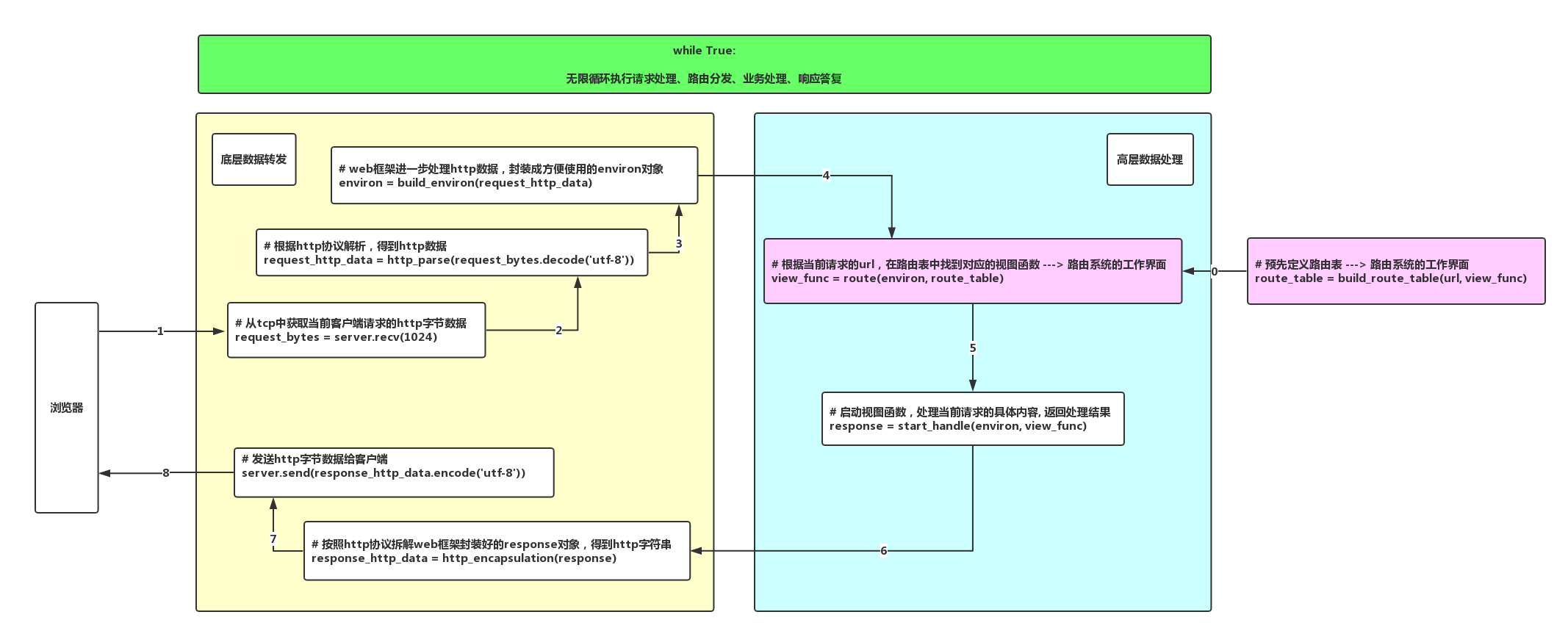
虛擬碼實現以上圖示
# 啟動路由分發過程
def route(environ, route_table):
url = environ.url
view_func = None
# 遍歷路由表
for map in route_table:
if url == map[0]:
view_func= map[1]
break
return view_func
# 執行檢視函式處理過程
def start_handle(environ, view_func):
if view_func:
return view_func(environ)
else:
return page_not_found(environ)
# web伺服器主迴圈
def run():
# 迴圈處理每一次的請求
while True:
# 從tcp中獲取當前客戶端請求的http位元組資料
request_bytes = server.recv(1024)
# 根據http協議解析,得到http資料
request_http_data = http_parse(request_bytes.decode('utf-8'))
# web框架進一步處理http資料,封裝成方便使用的environ物件
environ = build_environ(request_http_data)
# 根據當前請求的url,在路由表中找到對應的檢視函式 ---> 路由系統的工作介面
view_func = route(environ, route_table)
# 啟動檢視函式,處理當前請求的具體內容, 返回處理結果
response = start_handle(environ, view_func)
# 按照http協議拆解web框架封裝好的response物件,得到http字串
response_http_data = http_encapsulation(response)
# 傳送http位元組資料給客戶端
server.send(response_http_data.encode('utf-8'))
if __name__ == '__main__':
run()
六、路由系統的進階想法
進階考慮:
路由器收到請求request後,轉發到後端另一臺機器上執行,然後使用協程非同步,處理其他的reqeust請求。如果請求得到的響應,再切換回協程,然後執行響應。這樣可以實現入口伺服器作為所有請求的承接者,然後轉發到對應的後面不同業務伺服器處理各自的業務,可以把業務分離到不同的機器上,而且此時入口伺服器也可以處理併發請求。
即:多個伺服器上均部署django,多臺伺服器之間的django可以相互通訊,這樣可以實現一個類似伺服器叢集的效果,可以完成負載均衡和備份的效果。
