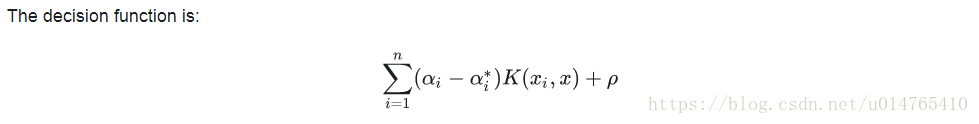sklearn(十四):Support Vector Machines
SVM可以用於classification,regression,outlier detection。
SVM優缺點
SVM的優點:
- SVM在高維資料上也非常有效。
- 當n_features > n_samples,SVM依然有效。
- SVM的決策函式只由支援向量機決定,因此,SVM無需儲存所有的training data,從這一點來講,SVM的空間複雜度較低。
- SVM能夠利用kernel trick,將決策函式從linear model變為non-linear model,擬合更復雜的資料。 SVM缺點:
- 當n_features > n_samples,為防止SVM overfitting,需要對loss function 新增正則項。
- SVM只能預測樣本label,而不能給出概率估計。如果要進行概率估計,需要利用cross-validation,在額外的test set上進行。在binary classification中,用Platting scaling進行概率校驗。需要注意的是,在large dataset中,Platting scaling in cross-validation計算量非常大,且利用predict_score和predict_proba得出的label可能不一致,此外,Platting scaling本身也存在一些理論上的問題,所以,在使用SVM時不建議啟用概率校驗(即最好將probability parameter set to False,使用decision function而不是predict_proba去預測樣本label)。
Recap:classifier的概率校驗有兩種方法:Platting scaling,non-parameter isotonic regression。Platting scaling應用於calibration curve為logistic regression,且用於校驗的dataset較少。non-param isotonic regression用於calibration curve不為logistic regression,校驗dataset較多的情況。 note that:SVM calibration curve shape is sigmoid。
Unbalanced problem
對於dataset中各個class樣本量不均衡的情況,可以通過SVM function中的class_weight parameter調整各個label樣本的權重,其權重將是parameter C multiply class_weight。 除可調整class weight以外,還可以通過parameter sample_weight調整sample weight,所得sample權重為parameter C multiply sample_weight。
Classification
sklearn.svm.SVC(C=1.0, kernel=’rbf’, degree=3, gamma=’auto_deprecated’, coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape=’ovr’, random_state=None)
#degress:polynomial 的引數
#gamma:一些kernel的引數
#coef0:polynomial和sigmoid kernel中的常數項
#shrinking:???
#probability:是否求待測樣本predict_proba
#cache_size:kernel cache
#decision_fucntion_shape:{ovr:one vs rest,ovo:one vs one}
#C:誤差函式的係數
sklearn.svm.NuSVC(nu=0.5, kernel=’rbf’, degree=3, gamma=’auto_deprecated’, coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape=’ovr’, random_state=None)
#nu:用於控制“支援向量機”的數量
sklearn.svm.LinearSVC(penalty=’l2’, loss=’squared_hinge’, dual=True, tol=0.0001, C=1.0, multi_class=’ovr’, fit_intercept=True, intercept_scaling=1, class_weight=None, verbose=0, random_state=None, max_iter=1000)
#dual:決定演算法是解決primal problem,還是解決dual problem。當n_samples > n_features,better set dual=False。
Regression
sklearn.svm.SVR(kernel=’rbf’, degree=3, gamma=’auto_deprecated’, coef0=0.0, tol=0.001, C=1.0, epsilon=0.1, shrinking=True, cache_size=200, verbose=False, max_iter=-1)
#epsilon:Epsilon in the epsilon-SVR model. It specifies the epsilon-tube within which no penalty is associated in the training loss function with points predicted within a distance epsilon from the actual value.
sklearn.svm.NuSVR(nu=0.5, C=1.0, kernel=’rbf’, degree=3, gamma=’auto_deprecated’, coef0=0.0, shrinking=True, tol=0.001, cache_size=200, verbose=False, max_iter=-1)
#nu:控制“支援向量機”的個數???
sklearn.svm.LinearSVR(epsilon=0.0, tol=0.0001, C=1.0, loss=’epsilon_insensitive’, fit_intercept=True, intercept_scaling=1.0, dual=True, verbose=0, random_state=None, max_iter=1000)
[待更新]:shrinking parameter [待更新]:nu
Density estimation, novelty detection
OneClassSVM可以用於outlier detection。但是它對outlier很敏感,因此,outlier detection效果並不好。
Tips on Pratical Use
- avoiding data copy
- 對於SVC,NuSVC,SVR,NuSVR,kernel cache的大小對執行時間有很大影響,因此,如果RAM充足的話,儘量將Kernel cache設定為>200(default value)的值。
- 引數C的值越大,正則化效果越弱。如果trianing data本身有很多噪音,應該將C調小一點,以加強正則化效果。
- SVM對於data的scale很敏感,因此,在擬合模型之前,應該先將data的值縮放到[0,1]或[-1,1]。
- 如果training data各個類別樣本數量嚴重失衡,應該將引數class_weight=‘balanced’,並試用不同的懲罰引數C。
kernel functions
各個SVM function中的kernel引數,可以接受3中形式的kernel: 1、系統自帶的kernel,有4中{linear,polynomial,RBF,sigmoid} 2、使用者自定義kernel function,賦值給kernel parameter,該kernel function必須返回一個kernel matrix。
>>> import numpy as np
>>> from sklearn import svm
>>> def my_kernel(X, Y):
... return np.dot(X, Y.T)
...
>>> clf = svm.SVC(kernel=my_kernel)
3、將引數kernel=‘precomputed’,並將Gram matrix(執行kernel trick後的feature matrix)傳入SVM function的fit method。
>>> import numpy as np
>>> from sklearn import svm
>>> X = np.array([[0, 0], [1, 1]])
>>> y = [0, 1]
>>> clf = svm.SVC(kernel='precomputed')
>>> # linear kernel computation
>>> gram = np.dot(X, X.T)
>>> clf.fit(gram, y)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto_deprecated',
kernel='precomputed', max_iter=-1, probability=False,
random_state=None, shrinking=True, tol=0.001, verbose=False)
>>> # predict on training examples
>>> clf.predict(gram)
array([0, 1])
Mathematical Formulation
SVC

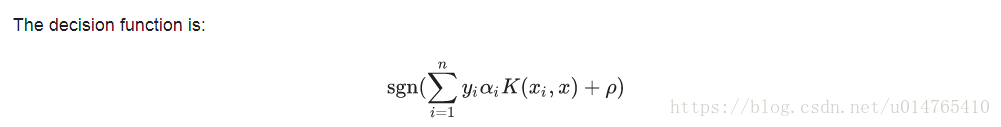
NuSVC
NuSVC is a reparameterization of the C-SVC and therefore mathematically equivalent。NuSVC的一個重要特徵是:他可以控制“支援向量機”的個數。
SVR