
Airflow Python工作流引擎的重要概念介紹
1、Airflow簡介
Airflow是一個以程式設計方式創作,安排和監控工作流程的平臺。
當工作流被定義為程式碼時,它們變得更易於維護,可版本化,可測試和協作。
使用Airflow將工作流作為任務的有向非迴圈圖(DAG)。 Airflow排程程式在遵循指定的依賴項的同時在一組worker上執行您的任務。 豐富的命令列實用程式可以輕鬆地在DAG上執行復雜的手術。 豐富的使用者介面使您可以輕鬆地視覺化生產中執行的管道,監控進度以及在需要時解決問題。
Airflow的英文官網:
https://airflow.apache.org/project.html
Airflow是由Airbnb開源的一款工具,目前在github上已經近一萬顆星,從該專案的github地址可獲取原始碼和很多示例檔案:
https://github.com/apache/incubator-airflow
https://github.com/apache/incubator-airflow/tree/master/airflow/example_dags
設計原則
-
動態:Airflow配置為程式碼(Python),允許動態生成pipeline。 這允許編寫動態例項化的pipelines程式碼。
-
可擴充套件:輕鬆定義自己的opertators,執行程式並擴充套件庫,使其符合適合您環境的抽象級別。
-
優雅:Airflow精益而明確。 使用強大的Jinja模板引擎將引數化指令碼內置於Airflow的核心。
-
可擴充套件:Airflow具有模組化體系結構,並使用訊息佇列來協調任意數量的工作者。 Airflow已準備好擴充套件到無限遠。
在查閱國內使用airflow的相關資料時,看到大部分網友是拿來作為代替crontab的一個高階定時任務管理工具使用,考慮到airflow的排程管理特性,確實也很擅長於做這些。不過airflow的核心價值應該是在於它是一個有向非迴圈的組織結構。在我們有一些比較複雜的後臺工作任務需要進行自動化地處理時,airflow是一個非常好用的任務工作流編排和管理的工具。
2、快速開始
mkdir -p ~/airflow export AIRFLOW_HOME=~/airflow export SLUGIFY_USES_TEXT_UNIDECODE=yes pip install apache-airflow # initialize the database airflow initdb # start the web server, default port is 8080 airflow webserver -p 8080 # start the scheduler airflow scheduler
通過瀏覽器訪問以下地址:
http://localhost:8080
Airflow服務的配置檔案為airflow.cfg,可以通過UI介面配置相關引數。
預設情況下,airflow使用一個sqlite資料庫和SequentialExecutor執行器,這種使用方式時將僅支援按順序得執行任務,只用於學習和實驗用途。
我們先看兩個演示的任務例項:
# run your first task instance
airflow run example_bash_operator runme_0 2018-09-06
# run a backfill over 2 days
airflow backfill example_bash_operator -s 2018-09-06 -e 2018-09-07如果需要部署一個用於生產的環境,則按下面兩個連結中的資訊,安裝其他型別的資料庫並對配置檔案進行變更。
https://airflow.apache.org/installation.html
https://airflow.apache.org/howto/initialize-database.html
3、定義一個DAG
人們有時會將DAG定義檔案視為可以進行實際資料處理的地方 - 事實並非如此! 該指令碼的目的是定義DAG物件。 它需要快速評估(秒級,而不是幾分鐘),因為排程程式將定期執行它以反映出變更(如果有的話)。Airflow 只是一個Python指令碼,用來定義了Airflow DAG物件。
下面是一個airflow pipeline的示例:
https://raw.githubusercontent.com/apache/incubator-airflow/master/airflow/example_dags/tutorial.py
# -*- coding: utf-8 -*-
#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
"""
### Tutorial Documentation
Documentation that goes along with the Airflow tutorial located
[here](https://airflow.incubator.apache.org/tutorial.html)
"""
# 匯入依賴庫
import airflow
from airflow import DAG
# 匯入特定的執行器
from airflow.operators.bash_operator import BashOperator
from datetime import timedelta
# these args will get passed on to each operator
# you can override them on a per-task basis during operator initialization
# 顯式地將一組引數傳遞給每個任務的建構函式作為預設引數
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': airflow.utils.dates.days_ago(2),
'email': ['[email protected]'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
# 'queue': 'bash_queue',
# 'pool': 'backfill',
# 'priority_weight': 10,
# 'end_date': datetime(2016, 1, 1),
# 'wait_for_downstream': False,
# 'dag': dag,
# 'adhoc':False,
# 'sla': timedelta(hours=2),
# 'execution_timeout': timedelta(seconds=300),
# 'on_failure_callback': some_function,
# 'on_success_callback': some_other_function,
# 'on_retry_callback': another_function,
# 'trigger_rule': u'all_success'
}
# 我們需要一個DAG物件來嵌入我們的任務。 這裡我們需要傳遞一個定義dag_id的字串,它用作DAG的唯一識別符號。 我們還傳遞我們剛剛定義的預設引數字典,併為DAG定義1天的schedule_interval。
dag = DAG(
'tutorial',
default_args=default_args,
description='A simple tutorial DAG',
schedule_interval=timedelta(days=1))
# 生成任務。 從operator例項化的物件稱為構造器。 第一個引數task_id充當任務的唯一識別符號。任務必須包含或繼承引數task_id和owner,否則Airflow將引發異常。
# t1, t2 and t3 are examples of tasks created by instantiating operators
t1 = BashOperator(
task_id='print_date',
bash_command='date',
dag=dag)
t1.doc_md = """\
#### Task Documentation
You can document your task using the attributes `doc_md` (markdown),
`doc` (plain text), `doc_rst`, `doc_json`, `doc_yaml` which gets
rendered in the UI's Task Instance Details page.

"""
dag.doc_md = __doc__
t2 = BashOperator(
task_id='sleep',
depends_on_past=False,
bash_command='sleep 5',
dag=dag)
# Airflow充分利用了Jinja Templating的強大功能,並提供了一組內建引數和巨集。 Airflow還支援自定義引數、巨集和模板的鉤子。下面的示例使用到了最常見的模板變數:{{ ds}}(今天的“日期戳”)
templated_command = """
{% for i in range(5) %}
echo "{{ ds }}"
echo "{{ macros.ds_add(ds, 7)}}"
echo "{{ params.my_param }}"
{% endfor %}
"""
t3 = BashOperator(
task_id='templated',
depends_on_past=False,
bash_command=templated_command,
params={'my_param': 'Parameter I passed in'},
dag=dag)
# 配置任務之間的依賴關係,使得任務t2和t3依賴於t1
t2.set_upstream(t1)
t3.set_upstream(t1)Airflow所支援的更多變理和巨集:https://airflow.apache.org/code.html#macros
4、測試
將指令碼檔案放在指定路徑下,執行一次,如果沒有報錯,說明指令碼檔案中不存在語法錯誤。
python ~/airflow/dags/tutorial.py命令列元資料驗證
# print the list of active DAGsairflow list_dags# prints the list of tasks the "tutorial" dag_idairflow list_tasks tutorial# prints the hierarchy of tasks in the tutorial DAGairflow list_tasks tutorial --tree
## Testing
# testing print_date
airflow test tutorial print_date 2018-09-06
# testing sleep
airflow test tutorial sleep 2018-09-06
# testing templated
airflow test tutorial templated 2018-09-06
## Backfill
# optional, start a web server in debug mode in the background
airflow webserver --debug &
# start your backfill on a date range
airflow backfill tutorial -s 2018-09-06 -e 2018-09-075、重要概念
5.1 DAGs
DAG不關心其組成任務的作用; 它的工作是確保一批任務可以在正確的時間或正確的順序發生,或可以正確處理任何意外的問題。
DAG在標準Python檔案中定義,這些檔案放在Airflow的DAG_FOLDER中。 Airflow將執行每個檔案中的程式碼以動態構建DAG物件。 您可以擁有任意數量的DAG,每個DAG都描述任意數量的任務。 通常,每個應該對應於單個邏輯工作流。
搜尋DAG時,Airflow將僅考慮字串“airflow”和“DAG”都出現在.py檔案內容中的檔案。
Scope
全域性DAG和本地DAG
Airflow將載入它可以從DAG檔案匯入的任何DAG物件。 重要的是,這意味著DAG必須出現在globals()中。
以下兩個DAG,將只會載入dag_1; 另一個只出現在本地範圍內。
dag_1 = DAG('this_dag_will_be_discovered')
def my_function():
dag_2 = DAG('but_this_dag_will_not')
my_function()有時這可以很好地利用。 例如,SubDagOperator的常見模式是定義函式內的子標記,以便Airflow不會嘗試將其作為獨立的DAG載入。
Default Arguments
如果將default_args字典傳遞給DAG,它將把它們應用於任何operator。 這使得很容易將公共引數應用於許多operator而無需多次的輸入。
default_args = {
'start_date': datetime(2016, 1, 1),
'owner': 'Airflow'}
dag = DAG('my_dag', default_args=default_args)
op = DummyOperator(task_id='dummy', dag=dag)
print(op.owner) # AirflowContext Manager
DAG可用作上下文管理器,以自動將新operator分配給該DAG。
5.2 Operators
雖然DAG描述瞭如何執行工作流,但是由operator確定實際完成的工作。
operator描述工作流中的單個任務。 operators通常(但並非總是)是原子的,這意味著他們可以獨立執行,而不需要與任何其他operators共享資源。 DAG將確保operators以正確的順序執行; 除了這些依賴項之外,operators通常獨立執行。 實際上,它們可能在兩臺完全不同的機器上執行。
這是一個微妙但非常重要的一點:通常,如果兩個operators需要共享資訊,如檔名或少量資料,您應該考慮將它們組合到一個運算子中。 如果無法絕對避免,Airflow確實也提供了operators交叉通訊的功能,稱為XCom,本文件的其他部分對此進行了描述。
Airflow為許多常見任務提供operator支援,包括:
-
BashOperator - executes a bash command
-
PythonOperator - calls an arbitrary Python function
-
EmailOperator - sends an email
-
SimpleHttpOperator - sends an HTTP request
-
MySqlOperator, SqliteOperator, PostgresOperator, MsSqlOperator, OracleOperator, JdbcOperator, etc. - executes a SQL command
-
Sensor - waits for a certain time, file, database row, S3 key, etc…
除了這些基本構建塊之外,還有許多特定的operators:
DockerOperator, HiveOperator, S3FileTransformOperator, PrestoToMysqlOperator, SlackOperator
airflow/contrib/目錄則包含了更多由社群構建的operators。 這些operators並不總是像主發行版中那樣完整或經過良好測試,但允許使用者更輕鬆地向平臺新增新功能。
Airflow operator的使用方法參見:https://airflow.apache.org/howto/operator.html
DAG Assignment
operator不必立即分配給DAG(之前的dag是必需引數)。 但是,一旦將operator分配給DAG,就無法轉移或取消分配。 在建立operator時,通過延遲賦值或甚至從其他operator推導,可以顯式地完成DAG分配。
dag = DAG('my_dag', start_date=datetime(2016, 1, 1))
# sets the DAG explicitlyexplicit_op = DummyOperator(task_id='op1', dag=dag)
# deferred DAG assignmentdeferred_op = DummyOperator(task_id='op2')deferred_op.dag = dag
# inferred DAG assignment (linked operators must be in the same DAG)inferred_op = DummyOperator(task_id='op3')inferred_op.set_upstream(deferred_op)Bitshift Composition 位移組合結構
傳統上,使用set_upstream()和set_downstream()方法設定operators之間的依賴關係。 在Airflow 1.8中,這可以通過Python bitshift操作符">>"和"<<"來完成。
例如,以下四個語句在功能上都是等效的:
op1 >> op2
op1.set_downstream(op2)
op2 << op1
op2.set_upstream(op1)當使用bitshift組合運算子時,關係設定在bitshift運算子指向的方向上。 例如,op1 >> op2表示op1先執行,op2執行第二。 可以組成多個運算子 - 請記住,鏈從左到右執行,並且始終返回最右邊的物件。 例如:
op1 >> op2 >> op3 << op4上面這行配置的效果相當於下面的依賴關係設定:
op1.set_downstream(op2)
op2.set_downstream(op3)
op3.set_upstream(op4)bitshift操作符同樣也能使用於DAGs,例如:
dag >> op1 >> op2相當於:
op1.dag = dag
op1.set_downstream(op2)通過使用bitshift操作符,我們可以把下面多個operators打包成為一個簡單的pipeline:
with DAG('my_dag', start_date=datetime(2016, 1, 1)) as dag:
(
DummyOperator(task_id='dummy_1')
>> BashOperator(
task_id='bash_1',
bash_command='echo "HELLO!"')
>> PythonOperator(
task_id='python_1',
python_callable=lambda: print("GOODBYE!"))
)5.3 Tasks
一旦operator被例項化,它就被稱為“任務”。 例項化的過程中會呼叫抽象運算子時定義特定值,引數化後的任務便成為了DAG中的一個節點。
任務例項表示任務的特定執行時,其特徵在於dag、任務和時間點的組合。 任務例項也有一個執行狀態,可以是“執行”、“成功”、“失敗”、“跳過”、“重試”等。
Workflows
您現在熟悉了Airflow的核心構建模組。 有些概念可能聽起來非常相似,但詞彙表可以概念化如下:
-
DAG: 描述工作應該發生的順序
-
Operator: 作為執行某些工作的模板的類
-
Task: operator的引數化例項
-
Task Instance: task的執行時例項
-
已經被分配了DAG
- 具有與DAG的特定執行相關聯的狀態
通過組合DAG、Operators來建立TaskInstances,您可以構建出複雜的工作流程。
6、附加功能
除了核心Airflow物件之外,還有許多更復雜的功能可以實現限制同時訪問資源、交叉通訊、條件執行等行為。
6.1 Hooks
鉤子是外部平臺和資料庫的介面,如Hive,S3,MySQL,Postgres,HDFS和Pig。 Hooks儘可能實現通用介面,並充當operator的構建塊。 他們使用airflow.models.Connection模型來獲取主機名和身份驗證資訊。 鉤子將身份驗證程式碼和資訊儲存在pipeline之外,集中在元資料資料庫中。
鉤子在Python指令碼,Airflow airflow.operators.PythonOperator以及iPython或Jupyter Notebook等互動式環境中使用它們也非常有用。
6.2 Pools
當有太多程序同時需要執行時,某些系統可能會被淹沒。 Airflow pools可用於限制任意任務集上的併發執行。 要以在UI(選單 - >管理 - >pools)中管理pools列表,通過為pools命名併為其分配多個worker slots。 然後在建立任務時(即例項化operators),可以通過使用pools引數將task與現有pools之一相關聯。
aggregate_db_message_job = BashOperator(
task_id='aggregate_db_message_job',
execution_timeout=timedelta(hours=3),
pool='ep_data_pipeline_db_msg_agg',
bash_command=aggregate_db_message_job_cmd,
dag=dag)aggregate_db_message_job.set_upstream(wait_for_empty_queue)pool引數可以與priority_weight結合使用,以定義佇列中的優先順序,以及在pool中開啟的slot時首先執行哪些任務。 預設的priority_weight是1,可以使用任何數字。 在對佇列進行排序以評估接下來應該執行哪個任務時,我們使用priority_weight,與來自此任務下游任務的所有priority_weight值相加。 您可以使用它來執行特定的重要任務,並相應地優先處理該任務的整個路徑。
當slot被填滿時,任務將照常安排。 達到容量後,可執行的任務將排隊,其狀態將在UI中顯示。 當插槽空閒時,排隊的任務將根據priority_weight(任務及其後代)開始執行。
請注意,預設情況下,任務不會分配給任何池,並且它們的執行的並行性僅限於執行程式的設定。
6.3 Connections
外部系統的連線資訊儲存在Airflow元資料資料庫中並在UI中進行管理(選單 - >管理 - >連線)。在那裡定義了conn_id,並附加了主機名/登入/密碼/schema資訊。 Airflow pipelines可以簡單地引用集中配置管理中的conn_id,而無需在任何地方硬編碼任何此類資訊。
可以定義具有相同conn_id的許多連線,並且在這種情況下,並且當hooks使用來自BaseHook的get_connection方法時,Airflow將隨機選擇一個連線,允許提供一些基本的負載平衡和容錯。
Airflow還能夠通過作業系統中的環境變數引用連線資訊。 但它只支援URI格式。 如果您需要為連線指定extra內容,請使用Web UI。
如果在Airflow元資料資料庫和環境變數中都定義了具有相同conn_id的連線,則Airflow將僅引用環境變數中的連線(例如,給定conn_id postgres_master,Airflow將首先在環境變數中搜索AIRFLOW_CONN_POSTGRES_MASTER並直接引用它)。
任何鉤子都有一個預設的conn_id,其中使用該鉤子的operators不需要顯式提供conn_id。 例如,PostgresHook的預設conn_id是postgres_default。
更多的關於Connections的使用方法請參照:https://airflow.apache.org/howto/manage-connections.html
6.4 Queues
使用CeleryExecutor時,可以指定傳送任務的celery佇列。 queue是BaseOperator的一個屬性,因此任何任務都可以分配給任何佇列。 環境的預設佇列在airflow.cfg的celery - > default_queue中定義。 這定義了未指定任務時分配給的佇列,以及Airflow工作程式在啟動時偵聽的佇列。
Workers可以監聽一個或多個任務佇列。 當工作程式啟動時(使用airflow worker命令),可以指定一組由逗號分隔的佇列名稱(例如,airflow worker -q spark)。 然後,該工作人員將僅接收連線到指定佇列的任務。
如果您需要專用的workers,從資源角度來看(例如,一個worker可以毫無問題地執行數千個任務)或者從環境角度(比如您希望worker從Spark群集中執行,這可能非常有用 本身,因為它需要一個非常具體的環境和安全許可權)。
6.5 XComs
XComs允許任務間交換訊息,允許更細微的控制形式和共享狀態。 該名稱是“cross-communication”的縮寫。 XComs主要由一個key, value和timestamp所定義,但也跟蹤建立XCom的task/DAG,以及何時應該可見的屬性。 任何可以被pickled的物件都可以用作XCom值,因此使用者應該確保使用適當大小的物件。
XComs支援“推”(傳送)或“拉”(接收)的方式處理訊息。 當任務推送XCom時,它通常可用於其他任務。 任務可以通過呼叫xcom_push()方法隨時推送XComs。 此外,如果任務返回一個值(來自其Operator的execute()方法,或者來自PythonOperator的python_callable函式),則會自動推送包含該值的XCom。
Tasks可以呼叫xcom_pull()來檢索XComs,可選地根據key、source task_ids和source dag_id等條件應用過濾器。 預設情況下,xcom_pull()會過濾出從執行函式返回時被自動賦予XCom的鍵(與手動推送的XCom相反)。
如果為task_ids傳遞xcom_pull單個字串,則返回該任務的最新XCom值; 如果傳遞了task_ids列表,則返回相應的XCom值列表。
# inside a PythonOperator called 'pushing_task'def push_function():
return value
# inside another PythonOperator where provide_context=Truedef pull_function(**context):
value = context['task_instance'].xcom_pull(task_ids='pushing_task')也可以直接在模板中pull XCom,這是一個示例:
SELECT * FROM {{ task_instance.xcom_pull(task_ids='foo', key='table_name') }}請注意,XCom與變數類似,但專門用於任務間通訊而非全域性設定。
6.6 Variables
變數是將任意內容或配置作為一個key/value簡單鍵值儲存的通用方法。 可以從UI(管理 - >變數),程式碼或CLI列出,建立,更新和刪除變數。 此外,json配置檔案可以通過UI批量上傳。 雖然pipeline程式碼定義和大多數常量和變數應該在程式碼中定義並存儲在原始碼控制中,但是通過UI可以訪問和修改某些變數或配置項會很有用。
from airflow.models import Variable
foo = Variable.get("foo")
bar = Variable.get("bar", deserialize_json=True)第二個呼叫假設是json內容,並將其反序列化為bar。 請注意,Variable是sqlalchemy模型,可以這樣使用。
你可以在jinja模板中按下面方法引用變數:
echo {{ var.value.<variable_name> }}或者如果需要從變數反序列化json物件:
echo {{ var.json.<variable_name> }}7.7 Branching
有時您需要一個工作流分支,或者只根據任意條件走下某條路徑,這通常與上游任務中發生的事情有關。 一種方法是使用BranchPythonOperator。
BranchPythonOperator與PythonOperator非常相似,只是它需要一個返回task_id的python_callable。 返回task_id,並跳過所有其他路徑。 Python函式返回的task_id必須直接引用BranchPythonOperator任務下游的任務。
請注意,在BranchPythonOperator的下游任務中使用depends_on_past = True,這在邏輯上是不合理的,因為skipped狀態將總是
因為他們過去的successes而造成task的堵塞。
如果你想跳過一些任務,請記住你不能有一個空路徑,如果是這樣,那就做一個虛設任務。
像這樣,跳過虛擬任務“branch_false”
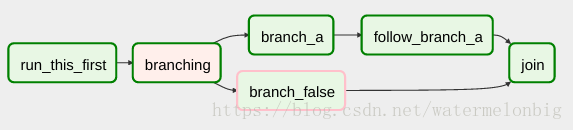
6.8 SubDAGs
SubDAG非常適合重複模式。 在使用Airflow時,定義一個返回DAG物件的函式是一個很好的設計模式。
Airbnb在載入資料時使用stage-check-exchange模式。 資料在臨時表中暫存,然後對該表執行資料質量檢查。 一旦檢查全部通過,分割槽就會移動到生產表中。
再舉一個例子,考慮以下DAG:
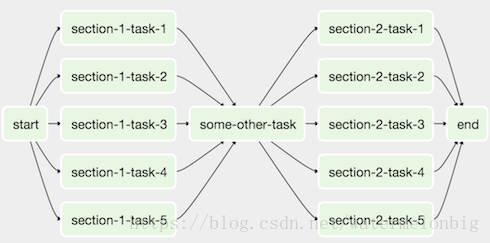
我們可以將所有並行task-* operators組合到一個SubDAG中,生成的DAG類似於以下內容:

請注意,SubDAG operators應包含返回DAG物件的工廠方法。 這將阻止SubDAG在main UI中被視為單獨的DAG。
例如:
#dags/subdag.py
from airflow.models import DAG
from airflow.operators.dummy_operator import DummyOperator
# Dag is returned by a factory method
def sub_dag(parent_dag_name, child_dag_name, start_date, schedule_interval):
dag = DAG(
'%s.%s' % (parent_dag_name, child_dag_name),
schedule_interval=schedule_interval,
start_date=start_date,
)
dummy_operator = DummyOperator(
task_id='dummy_task',
dag=dag,
)
return dag然後可以在主DAG檔案中引用此SubDAG:
# main_dag.pyfrom datetime import datetime, timedeltafrom airflow.models import DAGfrom airflow.operators.subdag_operator import SubDagOperatorfrom dags.subdag import sub_dag
PARENT_DAG_NAME = 'parent_dag'CHILD_DAG_NAME = 'child_dag'
main_dag = DAG(
dag_id=PARENT_DAG_NAME,
schedule_interval=timedelta(hours=1),
start_date=datetime(2016, 1, 1))
sub_dag = SubDagOperator(
subdag=sub_dag(PARENT_DAG_NAME, CHILD_DAG_NAME, main_dag.start_date,
main_dag.schedule_interval),
task_id=CHILD_DAG_NAME,
dag=main_dag,)您可以從主DAG的Graph檢視放大SubDagOperator,以顯示SubDAG中包含的任務:
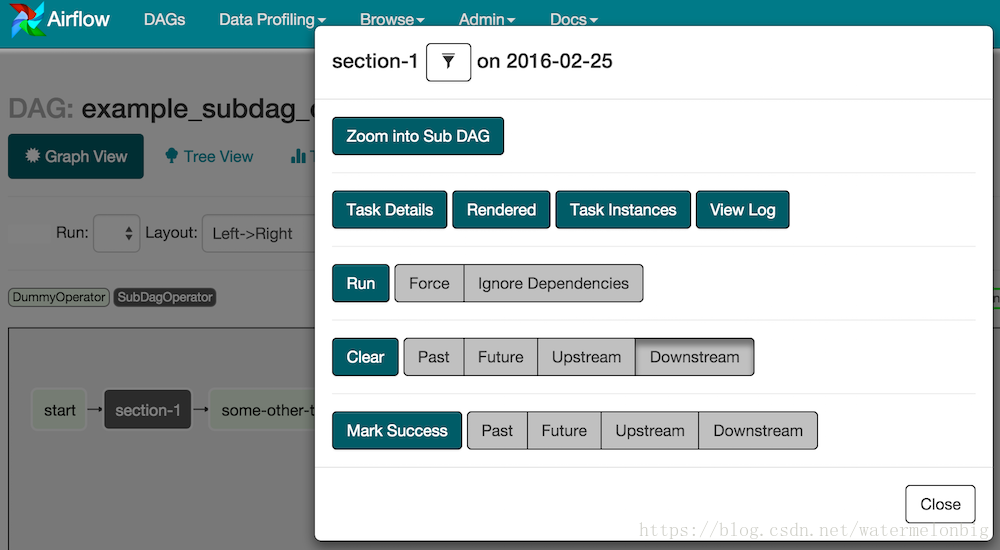
使用SubDAG時的一些其他提示:
- 按照慣例,SubDAG的dag_id應以其父級和點為字首。 和在parent.child中一樣。
- 通過將引數傳遞給SubDAG operator來共享主DAG和SubDAG之間的引數(如上所示)。
- SubDAG必須有一個計劃並啟用。 如果SubDAG的時間表設定為None或@once,SubDAG將成功完成而不做任何事情。
- 清除SubDagOperator也會清除其中的任務狀態。
- 在SubDagOperator上標記成功不會影響其中的任務狀態。
- 避免在SubDAG中的任務中使用depends_on_past=True,因為這可能會造成混淆。
- 可以為SubDAG指定執行程式。 如果要在程序中執行SubDAG並有效地將其並行性限制為1,則通常使用SequentialExecutor。 使用LocalExecutor可能會有問題,因為它可能會過度訂閱你的worker,在單個插槽中執行多個任務。
6.9 SLAs
服務級別協議或任務/DAG應該成功的時間可以在任務級別設定為timedelta。 如果此時一個或多個例項未成功,則會發送警報電子郵件,詳細說明錯過其SLA的任務列表。 該事件也記錄在資料庫中,並可在Web UI中瀏覽,其中可以分析和記錄事件。
6.10 Trigger Rules
雖然正常的工作流行為是在所有直接上游任務都成功時觸發任務,但Airflow允許更復雜的依賴項設定。
所有operators 都有一個trigger_rule引數,該引數定義生成的任務被觸發的規則。 trigger_rule的預設值是all_success,可以定義為“當所有直接上游任務都成功時觸發此任務”。 此處描述的所有其他規則都基於直接父任務,並且是在建立任務時可以傳遞給任何operator:
-
all_success: (default) 所有的父任務都成功。
-
all_failed: 所有的父任務或上游任務都失敗。
-
all_done: 所有的父任務都完成。
-
one_failed: 一旦至少一個父任務失敗了就會被觸發,它不會等待所有父任務完成。
-
one_success: 一旦至少有一個父任務成功了就會被觸發,它不會等待所有父任務完成。
-
dummy: 依賴只是為了展示,任意觸發。
請注意,這些可以與depends_on_past(boolean)結合使用,當設定為True時,如果任務的先前計劃未成功,則不會觸發任務。
6.11 Latest Run Only
標準工作流行為涉及為特定日期/時間範圍內執行一系列任務。 但是,某些工作流執行的任務與執行時無關,但需要按計劃執行,就像標準的cron作業一樣。 在這些情況下,暫停期間錯過的回填或執行作業會浪費CPU週期。
對於這種情況,您可以使用LatestOnlyOperator跳過在DAG的最近計劃執行期間未執行的任務。 如果現在的時間不在其execution_time和下一個計劃的execution_time之間,則LatestOnlyOperator將跳過所有直接下游任務及其自身。
必須意識到跳過的任務和觸發器規則之間的相互作用。 跳過的任務將通過觸發器規則all_success和all_failed級聯,但不是all_done,one_failed,one_success和dummy。 如果您希望將LatestOnlyOperator與不級聯跳過的觸發器規則一起使用,則需要確保LatestOnlyOperator直接位於您要跳過的任務的上游。
例如,考慮以下dag:
#dags/latest_only_with_trigger.pyimport datetime as dt
from airflow.models import DAGfrom airflow.operators.dummy_operator import DummyOperatorfrom airflow.operators.latest_only_operator import LatestOnlyOperatorfrom airflow.utils.trigger_rule import TriggerRule
dag = DAG(
dag_id='latest_only_with_trigger',
schedule_interval=dt.timedelta(hours=4),
start_date=dt.datetime(2016, 9, 20),)
latest_only = LatestOnlyOperator(task_id='latest_only', dag=dag)
task1 = DummyOperator(task_id='task1', dag=dag)
task1.set_upstream(latest_only)
task2 = DummyOperator(task_id='task2', dag=dag)
task3 = DummyOperator(task_id='task3', dag=dag)
task3.set_upstream([task1, task2])
task4 = DummyOperator(task_id='task4', dag=dag,
trigger_rule=TriggerRule.ALL_DONE)
task4.set_upstream([task1, task2])-
在這個dag的情況下,對於除最新執行之外的所有執行,latest_only任務將顯示為跳過。
-
task1直接位於latest_only的下游,並且除了最新的之外將跳過所有執行。
-
task2完全獨立於latest_only,將在所有計劃的時間段內執行。
-
task3是task1和task2的下游,由於預設的trigger_rule是all_success,因此將從task1接收級聯跳過。
-
task4是task1和task2的下游,但由於其trigger_rule設定為all_done,因此一旦跳過task1(有效的完成狀態)並且task2成功,它將立即觸發。

6.12 Zombies & Undeads
任務例項也會死掉,這通常是正常生命週期的一部分,但有時會出乎意料。
Zombies殭屍任務的特點是沒有心跳(由job定期發出)和資料庫中的執行狀態。 當工作節點無法訪問資料庫,Airflow程序在外部被終止或者節點重新啟動時,它們可能會發生。 排程程式的程序會定期執行查殺殭屍任務。
Undead程序的特點是存在程序和匹配的心跳,但Airflow不知道此任務在資料庫中執行。 這種不匹配通常在資料庫狀態發生變化時發生,最有可能是通過刪除UI中“任務例項”檢視中的行。 任務會被指示驗證其作為例行心跳的一部分的狀態,並在確定它們處於這種“undead”狀態時終止自己。
6.13 Cluster Policy
在您的本地airflow配置檔案中可以定義一個policy函式,該函式根據其他任務或DAG屬性改變任務屬性。 它接收單個引數作為對任務物件的引用,並期望改變其屬性。
例如,此函式可以在使用特定運算子時應用特定佇列屬性,或強制執行任務超時策略,確保沒有任務執行超過48小時。 以下是airflow_settings.py中的內容示例:
def policy(task):
if task.__class__.__name__ == 'HivePartitionSensor':
task.queue = "sensor_queue"
if task.timeout > timedelta(hours=48):
task.timeout = timedelta(hours=48)6.14 文件和註釋
可以在Web介面中顯示的dag和任務物件中新增文件或註釋(dag為“Graph View”,任務為“Task Details”)。 Airflow提供了一組特殊的任務屬性,用於呈現更為豐富的內容:

請注意,對於dags,doc_md是可使用的唯一註釋屬性。
如果您的任務是從配置檔案動態構建的,則此功能特別有用,它允許您公開Airflow中相關任務的配置資訊。
"""
### My great DAG
"""
dag = DAG('my_dag', default_args=default_args)
dag.doc_md = __doc__
t = BashOperator("foo", dag=dag)
t.doc_md = """\
#Title"
Here's a [url](www.airbnb.com)
"""此內容將分別在“圖表檢視”和“任務詳細資訊”頁面中被煊染為markdown格式。
6.15 Jinja Templating
Airflow充分利用了Jinja Templating的強大功能,這可以成為與巨集結合使用的強大工具。
例如,假設您希望使用BashOperator將執行日期作為環境變數傳遞給Bash指令碼。
# The execution date as YYYY-MM-DD
date = "{{ ds }}"
t = BashOperator(
task_id='test_env',
bash_command='/tmp/test.sh ',
dag=dag,
env={'EXECUTION_DATE': date})這裡,{{ds}}是一個巨集,並且由於BashOperator的env引數是使用Jinja模板化的,因此執行日期將作為Bash指令碼中名為EXECUTION_DATE的環境變數提供。
您可以將Jinja模板與文件中標記為“templated”的每個引數一起使用。 模板替換髮生在呼叫operator的pre_execute函式之前。
6.6 Packaged dags
雖然通常會在單個.py檔案中指定dags,但有時可能需要將dag及其依賴項打包組合在一起。
例如,您可能希望將多個dag組合在一起以將它們一起管理版本,或者您可能需要一個額外的模組,預設情況下在您執行airflow的系統上不可用。 為此,您可以建立一個zip檔案,其中包含zip檔案根目錄中的dag,並在目錄中解壓縮額外的模組。
例如,您可以建立一個如下所示的zip檔案:
my_dag1.py
my_dag2.py
package1/__init__.py
package1/functions.pyAirflow將掃描zip檔案並嘗試載入my_dag1.py和my_dag2.py。 它不會進入子目錄,因為它們被認為是潛在的包。
如果您想將模組依賴項新增到DAG,您基本上也會這樣做,但是更多的是使用virtualenv和pip。
virtualenv zip_dag
source zip_dag/bin/activate
mkdir zip_dag_contents
cd zip_dag_contents
pip install --install-option="--install-lib=$PWD" my_useful_package
cp ~/my_dag.py .
zip -r zip_dag.zip *注1:zip檔案將插入模組搜尋列表(sys.path)的開頭,因此它將可用於駐留在同一直譯器中的任何其他程式碼。
注2:打包的dags不能與開啟pickling時一起使用。
注3:打包的dag不能包含動態庫(例如libz.so),如果模組需要這些庫,則需要在系統上使用這些庫。 換句話說,只能打包純python模組。
參考資料:
https://airflow.apache.org/concepts.html
系統研究Airbnb開源專案airflow http://www.cnblogs.com/harrychinese/p/airflow.html
Airflow使用入門指南 https://blog.csdn.net/qazplm12_3/article/details/53065654
Airflow實戰 http://ju.outofmemory.cn/entry/245373
一個非常好用的data pipeline管理工具 airflow https://www.jianshu.com/p/59d69981658a
使用 Airflow 替代你的 crontab https://www.juhe.cn/news/index/id/2365
生產環境使用airflow https://www.douban.com/note/620024057/
Airflow 中的技巧和陷阱 https://segmentfault.com/a/1190000005078547
airflow 簡明指南 https://www.v2ex.com/t/331460
airflow探索篇 https://segmentfault.com/a/1190000012803744