
阿里巴巴程式碼規範
1、關於本規範
本規範均出自阿里巴巴程式碼規範以及本人日常過程中的積累。由於篇幅有限,本文不予列出阿里巴巴程式碼規範的所有,僅列出本人覺得對日常使用過程中幫助較大且又是大家容易忽略的問題。
阿里巴巴程式碼規範:http://pan.baidu.com/s/1slt3g0P
一、程式設計規約
(一) 命名規約
1、抽象類命名使用Abstract或Base開頭;異常類命名使用Exception結尾;測試類命名以它要測試的類的名稱開始,以Test結尾。
2、中括號是陣列型別的一部分,陣列定義如下:String[] args; 反例:請勿使用String args[]的方式來定義。
3、如果使用到了設計模式,建議在類名中體現出具體模式
正例:public class OrderFactory; public class LoginProxy; public class ResourceObserver;
4、各層命名規約:
A) Service/DAO層方法命名規約
1) 獲取單個物件的方法用get做字首。
2) 獲取多個物件的方法用list做字首。
3) 獲取統計值的方法用count做字首。
4) 插入的方法用save(推薦)或insert做字首。
5) 刪除的方法用remove(推薦)或delete做字首。
6) 修改的方法用update做字首。
B) 領域模型命名規約
1) 資料物件:xxxDO,xxx即為資料表名。
3) 展示物件:xxxVO,xxx一般為網頁名稱。
4) POJO是DO/DTO/BO/VO的統稱,禁止命名成xxxPOJO。
(二) 常量定義
1、long或者Long初始賦值時,必須使用大寫的L,不能是小寫的l,小寫容易跟數字1混淆,造成誤解。 說明:Long a = 2l; 寫的是數字的21,還是Long型的2?
(三) 格式規約
(四) OOP規約
1、所有的相同型別的包裝類物件之間值的比較,全部使用equals方法比較。 說明:對於Integer var=?在-128至127之間的賦值,Integer物件是在IntegerCache.cache產生,會複用已有物件,這個區間內的Integer值可以直接使用==進行判斷,但是這個區間之外的所有資料,都會在堆上產生,並不會複用已有物件,這是一個大坑,推薦使用equals方法進行判斷。
2、構造方法裡面禁止加入任何業務邏輯,如果有初始化邏輯,請放在init方法中。
3、POJO類必須寫toString方法。使用IDE的中工具:source> generate toString時,如果繼承了另一個POJO類,注意在前面加一下super.toString。
4、當一個類有多個構造方法,或者多個同名方法,這些方法應該按順序放置在一起,便於閱讀。
5、類內方法定義順序依次是:公有方法或保護方法 > 私有方法 > getter/setter方法。
說明:公有方法是類的呼叫者和維護者最關心的方法,首屏展示最好;保護方法雖然只是子類關心,也可能是“模板設計模式”下的核心方法;而私有方法外部一般不需要特別關心,是一個黑盒實現;因為方法資訊價值較低,所有Service和DAO的getter/setter方法放在類體最後。
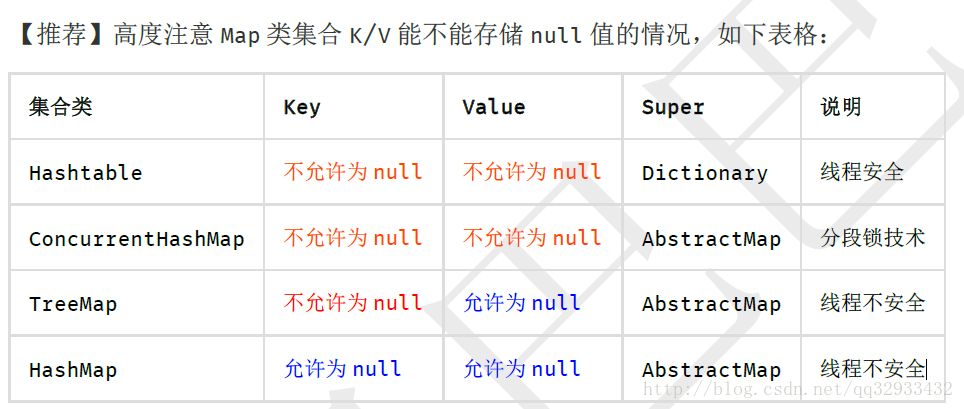
(五) 集合處理
1、關於hashCode和equals的處理,遵循如下規則:
1) 只要重寫equals,就必須重寫hashCode。
2) 因為Set儲存的是不重複的物件,依據hashCode和equals進行判斷,所以Set儲存的物件必須重寫這兩個方法。
3) 如果自定義物件做為Map的鍵,那麼必須重寫hashCode和equals。
正例:String重寫了hashCode和equals方法,所以我們可以非常愉快地使用String物件作為key來使用。
2、ArrayList的subList結果不可強轉成ArrayList,否則會丟擲ClassCastException
3、在subList場景中,高度注意對原集合元素個數的修改,會導致子列表的遍歷、增加、刪除均產生ConcurrentModificationException 異常。
4、使用工具類Arrays.asList()把陣列轉換成集合時,不能使用其修改集合相關的方法,它的add/remove/clear方法會丟擲UnsupportedOperationException異常。
5、使用entrySet遍歷Map類集合KV,而不是keySet方式進行遍歷。 說明:keySet其實是遍歷了2次,一次是轉為Iterator物件,另一次是從hashMap中取出key所對應的value。而entrySet只是遍歷了一次就把key和value都放到了entry中,效率更高。如果是JDK8,使用Map.foreach方法。
7、利用Set元素唯一的特性,可以快速對一個集合進行去重操作,避免使用List的contains方法進行遍歷、對比、去重操作。
(六) 併發處理
(七) 控制語句
1、在一個switch塊內,每個case要麼通過break/return等來終止,要麼註釋說明程式將繼續執行到哪一個case為止;在一個switch塊內,都必須包含一個default語句並且放在最後,即使它什麼程式碼也沒有。
2、推薦儘量少用else, if-else的方式可以改寫成:
if(condition){
…
return obj;
}
// 接著寫else的業務邏輯程式碼;
說明:如果非得使用if()…else if()…else…方式表達邏輯,【強制】請勿超過3層,超過請使用狀態設計模式。
正例:邏輯上超過3層的if-else程式碼可以使用衛語句,或者狀態模式來實現。
3、除常用方法(如getXxx/isXxx)等外,不要在條件判斷中執行其它複雜的語句,將複雜邏輯判斷的結果賦值給一個有意義的布林變數名,以提高可讀性。
正例:
//虛擬碼如下
boolean existed = (file.open(fileName, “w”) != null) && (…) || (…);
if (existed) {
…
}
反例:
if ((file.open(fileName, “w”) != null) && (…) || (…)) {
…
}
4、迴圈體中的語句要考量效能,以下操作儘量移至迴圈體外處理,如定義物件、變數、獲取資料庫連線,進行不必要的try-catch操作(這個try-catch是否可以移至迴圈體外)。
(八) 註釋規約
1、類、類屬性、類方法的註釋必須使用Javadoc規範,使用/*內容/格式,不得使用//xxx方式。
2、所有的抽象方法(包括介面中的方法)必須要用Javadoc註釋、除了返回值、引數、異常說明外,還必須指出該方法做什麼事情,實現什麼功能。
3、方法內部單行註釋,在被註釋語句上方另起一行,使用//註釋。方法內部多行註釋使用/* */註釋,注意與程式碼對齊。
(九) 其它
1、在使用正則表示式時,利用好其預編譯功能,可以有效加快正則匹配速度。 說明:不要在方法體內定義:Pattern pattern = Pattern.compile(規則);
2、後臺輸送給頁面的變數必須加$!{var}——中間的感嘆號。
3、注意 Math.random() 這個方法返回是double型別,注意取值的範圍 0≤x<1(能夠取到零值,注意除零異常),如果想獲取整數型別的隨機數,不要將x放大10的若干倍然後取整,直接使用Random物件的nextInt或者nextLong方法。
4、獲取當前毫秒數System.currentTimeMillis(); 而不是new Date().getTime(); 說明:如果想獲取更加精確的納秒級時間值,用System.nanoTime()。在JDK8中,針對統計時間等場景,推薦使用Instant類。
二、異常日誌
(一) 異常處理
1、對大段程式碼進行try-catch,這是不負責任的表現。catch時請分清穩定程式碼和非穩定程式碼,穩定程式碼指的是無論如何不會出錯的程式碼。對於非穩定程式碼的catch儘可能進行區分異常型別,再做對應的異常處理。
2、finally塊必須對資源物件、流物件進行關閉,有異常也要做try-catch。 說明:如果JDK7,可以使用try-with-resources方式。
3、定義時區分unchecked / checked 異常,避免直接使用RuntimeException丟擲,更不允許丟擲Exception或者Throwable,應使用有業務含義的自定義異常。推薦業界已定義過的自定義異常,如:DAOException / ServiceException等。
(二) 日誌規約
1、對trace/debug/info級別的日誌輸出,必須使用條件輸出形式或者使用佔位符的方式。 說明:logger.debug(“Processing trade with id: ” + id + ” symbol: ” + symbol); 如果日誌級別是warn,上述日誌不會列印,但是會執行字串拼接操作,如果symbol是物件,會執行toString()方法,浪費了系統資源,執行了上述操作,最終日誌卻沒有列印。 正例:(條件)
if (logger.isDebugEnabled()) {
logger.debug(“Processing trade with id: ” + id + ” symbol: ” + symbol);
}
正例:(佔位符)
logger.debug(“Processing trade with id: {} symbol : {} “, id, symbol);
2、避免重複列印日誌,浪費磁碟空間,務必在log4j.xml中設定additivity=false。 正例:
三、MySQL規約
(一) 建表規約
(二) 索引規約
1、業務上具有唯一特性的欄位,即使是組合欄位,也必須建成唯一索引。 說明:不要以為唯一索引影響了insert速度,這個速度損耗可以忽略,但提高查詢速度是明顯的;另外,即使在應用層做了非常完善的校驗和控制,只要沒有唯一索引,根據墨菲定律,必然有髒資料產生。
2、在varchar欄位上建立索引時,必須指定索引長度,沒必要對全欄位建立索引,根據實際文字區分度決定索引長度。
(三) SQL規約
1、不要使用count(列名)或count(常量)來替代count(),count()就是SQL92定義的標準統計行數的語法,跟資料庫無關,跟NULL和非NULL無關。 說明:count(*)會統計值為NULL的行,而count(列名)不會統計此列為NULL值的行。
2、count(distinct col) 計算該列除NULL之外的不重複數量。注意 count(distinct col1, col2) 如果其中一列全為NULL,那麼即使另一列有不同的值,也返回為0。
3、當某一列的值全是NULL時,count(col)的返回結果為0,但sum(col)的返回結果為NULL,因此使用sum()時需注意NPE問題。
正例:可以使用如下方式來避免sum的NPE問題:SELECT IF(ISNULL(SUM(g)),0,SUM(g)) FROM table;
4、使用ISNULL()來判斷是否為NULL值。注意:NULL與任何值的直接比較都為NULL。 說明:
1) NULL<>NULL的返回結果是NULL,而不是false。
2) NULL=NULL的返回結果是NULL,而不是true。
3) NULL<>1的返回結果是NULL,而不是true。
(四) ORM規約
(三) 伺服器規約
1、高併發伺服器建議調小TCP協議的time_wait超時時間。 說明:作業系統預設240秒後,才會關閉處於time_wait狀態的連線,在高併發訪問下,伺服器端會因為處於time_wait的連線數太多,可能無法建立新的連線,所以需要在伺服器上調小此等待值。 正例:在linux伺服器上請通過變更/etc/sysctl.conf檔案去修改該預設值(秒): net.ipv4.tcp_fin_timeout = 30
2、調大伺服器所支援的最大檔案控制代碼數(File Descriptor,簡寫為fd)。 說明:主流作業系統的設計是將TCP/UDP連線採用與檔案一樣的方式去管理,即一個連線對應於一個fd。主流的linux伺服器預設所支援最大fd數量為1024,當併發連線數很大時很容易因為fd不足而出現“open too many files”錯誤,導致新的連線無法建立。 建議將linux伺服器所支援的最大控制代碼數調高數倍(與伺服器的記憶體數量相關)。
3、給JVM設定-XX:+HeapDumpOnOutOfMemoryError引數,讓JVM碰到OOM場景時輸出dump資訊。 說明:OOM的發生是有概率的,甚至有規律地相隔數月才出現一例,出現時的現場資訊對查錯非常有價值。