
Linux 桌面玩家指南:06. 優雅地使用命令列及 Bash 指令碼程式語言中的美學與哲學
特別說明:要在我的隨筆後寫評論的小夥伴們請注意了,我的部落格開啟了 MathJax 數學公式支援,MathJax 使用
$標記數學公式的開始和結束。如果某條評論中出現了兩個$,MathJax 會將兩個$之間的內容按照數學公式進行排版,從而導致評論區格式混亂。如果大家的評論中用到了$,但是又不是為了使用數學公式,就請使用\$轉義一下,謝謝。
想從頭閱讀該系列嗎?下面是傳送門:
前言
雖然我們玩的是 Linux 桌面系統,但是很多時候我們仍然離不開命令列。有時候,是因為某些工具只有命令列版本,要解決某些問題必須使用命令列,特別是對於我們程式猿和系統管理員來說更是這樣。有時候,是因為使用命令列解決問題確實比使用圖形介面更加高效。還有些時候,為了自動化、批量化執行程式,我們也不得不使用命令列。得益於 Unix 系統的傳統,在命令列中使用管道和檔案重定向以及 Shell 指令碼語言作為粘合劑,可以將許多簡單的工具組合到一起完成更加複雜的任務。總之,Linux 系統中的命令列是相當舒服和優雅的。
我這裡使用的終端程式就是 Gnome 3 桌面自帶的 gnome-terminal,而我使用的 Shell 就是 Bash。網上有很多人推崇 Z Shell,但是我並沒有改弦易轍,而是堅持使用 Bash。我認為,Bash 的功能也是很強大的,只是我自己水平有限,不能發揮出它全部的威力而已。關於高效使用命令列這個話題,在網上已經是老生常談了。我這裡主要的參考資料是 Bash 的官方文件,使用man bash即可以閱讀,當然也可以到 Bash 的官網上下載 pdf 版的文件,放到手機上有空的時候慢慢看。在本文中,也有不少我自己的觀點和體會,我會提到有些快捷鍵要熟記,有些則完全不需要記,畢竟我們的記憶力也是有限的,我還會提到一些助記的方法。所以,本文絕對不是照本宣科,值得大家擁有,請大家一定記得點贊。
四年前,我腦子一抽,寫了一篇 Bash 指令碼程式語言中的美學與哲學,還非常洋洋得意。現在回看起來,覺得還是幼稚了一些。但是我覺得我寫的這些也不是完全沒有幫助,相比於長達 171 頁的詳細的 Bash 官方文件,也許我對 Bash 指令碼程式語言的定位——面向字串的程式語言——更能讓大家理解記住並熟練使用命令列呢。
使用 tmux 複用控制檯視窗
高效使用命令列的首要原則就是要儘量避免干擾,什麼意思呢?就是說一但開啟了一個控制檯視窗,就儘量不要再在桌面上切換來切換去了,不要一會兒被別的視窗擋住控制檯,一會兒又讓別的視窗破壞了控制檯的背景,最好是把控制檯最大化或全屏,甚至連滑鼠都不要用。但是在實際工作中,我們又經常需要同時在多個控制檯視窗中進行工作,例如:在一個控制檯視窗中執行錄製螢幕的命令,在另外一個控制檯視窗中工作;或者在一個控制檯視窗中工作,在另外一個控制檯視窗中閱讀文件。如果既想在多個控制檯視窗中工作,又不想一大堆視窗擋來擋去、換來換去的話,就可以考慮試試 tmux 了。如下圖:

tmux 的功能很多,什麼 Session 啊、Atach 啊、Detach 啊等功能都非常強大。但是我們暫時不用去關心這些,只把重點放在它的控制檯視窗複用功能上就行了。tmux 中有 window 和 pane 的概念,tmux 可以建立多個 window,這些 window 是不會互相遮擋的,每次只顯示一個 window,其它的 window 會自動隱藏,可以使用快捷鍵在 window 之間切換。同時,可以把一個 window 切分成多個 pane,這些 pane 同時顯示在螢幕上,可以使用快捷鍵在 pane 之間切換。
tmux 的快捷鍵很多,要想全面瞭解 tmux 的最好辦法當然是使用man tmux命令閱讀 tmux 的文件。但是我們只需要記住少數幾個重要的快捷鍵就可以了,如下表:
| 快捷鍵 | 功能 |
|---|---|
| Ctrl+B c | 建立一個 window |
| Ctrl+B [n][p] | 切換到下一個視窗或上一個視窗 |
| Ctrl+B & | 關閉當前視窗 |
| Ctrl+B " | 將當前 window 或 pane 切分成兩個 pane,上下排列 |
| Ctrl+B % | 將當前 window 或 pane 切分成兩個 pane,左右排列 |
| Ctrl+B x | 關閉當前 pane |
| Ctrl+B [↑][↓][←][→] | 在 pane 之間移動 |
| Ctrl+[↑][↓][←][→] | 調整當前 pane 的大小,一次調整一格 |
| Alt+[↑][↓][←][→] | 調整當前 pane 的大小,一次調整五格 |
tmux 的快捷鍵比較特殊,除了調整 pane 大小的快捷鍵之外,其它的都是先按 Ctrl+B,再按一個字元。先按 Ctrl+B,再按 c,就會建立一個 window,這裡 c 就是 create window。先按 Ctrl+B,再按 n 或者 p,就可以在視窗之間切換,它們是 next window 和 previous window 的意思。關閉視窗是先按 Ctrl+B,再按 &,這個只能死記。先按 Ctrl+B,再按 " ,表示上下拆分視窗,可以想象成單引號和雙引號在鍵盤上是上下鋪關係。先按 Ctrl+B,再按 % 表示左右拆分視窗,大概是因為百分數都是左右書寫的吧。至於在 pane 之間移動和調整 pane 大小的方向鍵,就不用多說了吧。
在命令列中快速移動游標
在命令列中輸入命令時,經常要在命令列中移動游標。這個很簡單嘛,使用左右方向鍵就可以了,但是有時候我們輸入了很長一串命令,卻突然要修改這個命令最開頭的內容,如果使用向左的方向鍵一個字元一個字元地把游標移到命令的開頭,是否太慢了呢?有時我們需要直接在命令的開頭和結尾之間切換,有時又需要能夠一個單詞一個單詞地移動游標,在命令列中,其實這都不是事兒。如下圖:

這幾種移動方式都是有快捷鍵的。其實一個字元一個字元地移動游標也有快捷鍵 Ctrl+B 和 Ctrl+F,但是這兩個快捷鍵我們不需要記,有什麼能比左右方向鍵更方便的呢?我們真正要記的是下面這幾個:
| 快捷鍵 | 功能 |
|---|---|
| Ctrl + A | 將游標移動到命令列的開頭 |
| Ctrl + E | 將游標移動到命令列的結尾 |
| Alt + B | 將游標向左移動一個單詞 |
| Alt + F | 將游標向右移動一個單詞 |
這幾個快捷鍵太好記了,A 代表 ahead,E 代表 end,B 代表 back,F 代表 forward。為什麼按單詞移動游標的快捷鍵都是以 Alt 開頭呢?那是因為按字元移動游標的快捷鍵把 Ctrl 佔用了。但是按字元移動游標的快捷鍵我們用不到啊,因為我們有左右方向鍵啊。
在命令列中快速刪除文字
對輸入的內容進行修改也是我們經常要乾的事情,對命令列進行修改就涉及到先刪除一部分內容,再輸入新內容。我們碰到的情況是有時候只需要修改個別字元,有時候需要修改個別單詞,而有時候,輸入了半天的很長的一段命令,我們說不要就全都不要了,要整行刪除。常用的刪除鍵當然是 BackSpace 和 Delete 啦,不過一次刪除一個字元,還是太慢了些。要在命令列中快速刪除文字,請熟記以下幾個快捷鍵吧:
| 快捷鍵 | 功能 |
|---|---|
| Ctrl + U | 刪除從游標到行首的所有內容,如果游標在行尾,自然就整行都刪除了啊 |
| Ctrl + K | 刪除從游標到行尾的所有內容,如果游標在行首,自然也是整行都刪除了啊 |
| Ctrl + W | 刪除游標前的一個單詞 |
| Alt + D | 刪除游標後的一個單詞 |
| Ctrl + Y | 將剛刪除的內容貼上到游標處,有時候刪錯了可以用這個快捷鍵恢復刪除的內容 |
效果請看下圖:

這幾個快捷鍵也是蠻好記的,U 代表 undo,K 代表 kill,W 代表 word,D 代表 delete, Y 代表 yank。其中比較奇怪的是 Alt+D 又是以 Alt 開頭的,那是因為 Ctrl+D 又被佔用了。Ctrl+D 有兩個意思,一是在編輯命令列的時候它代表刪除一個字元,當然,這個快捷鍵其實我們用不到,因為 BackSpace 和 Delete 方便多了;二是在某些程式從 stdin 讀取資料的時候,Ctrl+D 代表 EOF,這個我們偶爾會用到。
快速檢視和搜尋歷史命令
對於曾經執行過的命令,除非特別短,我們一般不會重複輸入,從歷史記錄中找出來用自然要快得多。我們用得最多的就是 ↑ 和 ↓,特別是不久前才剛剛輸入過的命令,使用 ↑ 向上翻幾行就找到了,按一下 Enter 就執行,多舒服。但是有時候,明明記得是不久前才用過的命令,但是向上翻了半天也沒找到,怎麼辦?那隻好使用history命令來檢視所有的歷史記錄了。歷史記錄又特別長,怎麼辦?可以使用 history | less和history | grep '...'。除此之外,還有終極大殺招,那就是按 Ctrl+R 從歷史記錄中進行搜尋。按了 Ctrl+R 之後,每輸入一個字元,都會和歷史記錄中進行增量匹配,輸入得越多,匹配越精確。當然,有時候含有相同搜尋字串的命令特別多,怎麼辦?繼續按 Ctrl+R,就會繼續搜尋下一條匹配的歷史記錄。如下圖:

這裡,需要記住的命令和快捷鍵如下表:
| 命令或快捷鍵 | 功能 |
|---|---|
| history | 檢視歷史記錄 |
| history | less | 分頁檢視歷史記錄 |
| history | grep '...' | 在歷史記錄中搜索匹配的命令,並顯示 |
| Ctrl + R | 逆向搜尋歷史記錄,和輸入的字元進行增量匹配 |
| Esc | 停止搜尋歷史記錄,並將當前匹配的結果放到當前輸入的命令列上 |
| Enter | 停止搜尋歷史記錄,並將當前匹配的結果立即執行 |
| Ctrl + G | 停止搜尋歷史記錄,並放棄當前匹配的結果 |
| Alt + > | 將歷史記錄中的位置標記移動到歷史記錄的尾部 |
這裡需要注意的是,當我們在歷史記錄中搜索的時候,是有位置標記的,Ctrl+R 是指從當前位置開始,逆向搜尋,R 代表的是 reverse,每搜尋一條記錄,位置標記都會向歷史記錄的頭部移動,下次搜尋又從這裡開始繼續向頭部搜尋。所以,我們一定要記住快捷鍵 Alt+>,它可以把歷史記錄的位置標記還原。另外需要注意的是停止搜尋歷史記錄的快捷鍵有三個,如果按 Enter 鍵,匹配的命令就立即執行了,如果你還想有修改這條命令的機會的話,一定不要按 Enter,而要按 Esc。如果什麼都不想要,就按 Ctrl+G,它會還你一個空白的命令列。
快速引用和修飾歷史命令
除了檢視和搜尋歷史記錄,我們還可以以更靈活的方式引用歷史記錄中的命令。常見的簡單的例子有!!代表引用上一條命令,!$代表引用上一條命令的最後一個引數,^oldstring^newstring^代表將上一條命令中的 oldstring 替換成 newstring。這些操作是我們平時使用命令列的時候的一些常用技巧,其實它們的本質,是由 history 庫提供的 history expansion 功能。Bash 使用了 history 庫,所以也能使用這些功能。其完整的文件可以檢視man history手冊頁。知道了 history expansion 的理論,我們還可以做一些更加複雜的操作,如下圖:

引用和修飾歷史命令的完整格式是這樣的:
![!|[?]string|[-]number]:[n|x-y|^|$|*|n*|%]:[h|t|r|e|p|s|g]可以看到,一個對歷史命令的引用被 : 分為了三個部分,第一個部分決定了引用哪一條歷史命令;第二部分決定了選取該歷史命令中的第幾個單詞,單詞是從0開始編號的,也就是說第0個單詞代表命令本身,第1個到最後一個單詞代表命令的引數;第三部分決定了對選取的單詞如何修飾。下面我列出完整表格:
表格一、引用哪一條歷史命令:
| 操作符 | 功能 |
|---|---|
| ! | 所有對歷史命令的引用都以 ! 開始,除了 ^oldstring^newstring^ 形式的快速替換 |
| !n | 引用第 n 條歷史命令 |
| !-n | 引用倒數第 n 條歷史命令 |
| !! | 引用上一條命令,等於 !-1 |
| !string | 逆向搜尋歷史記錄,第一條以 string 開頭的命令 |
| !?string[?] | 逆向搜尋歷史記錄,第一條包含 string 的命令 |
| ^oldstring^newstring^ | 對上一條命令進行快速替換,將 oldstring 替換為 newstring |
| !# | 引用當前輸入的命令 |
表格二、選取哪一個單詞:
| 操作符 | 功能 |
|---|---|
| 0 | 第0個單詞,在 shell 中就是命令本身 |
| n | 第n個單詞 |
| ^ | 第1個單詞,使用 ^ 時可以省略前面的冒號 |
| $ | 最後一個單詞,使用 $ 時可以省略前面的冒號 |
| % | 和 ?string? 匹配的單詞,可以省略前面的冒號 |
| x-y | 從第 x 個單詞到第 y 個單詞,-y 代表 0-y |
| * | 除第 0 個單詞外的所有單詞,等於 1-$ |
| x* | 從第 x 個單詞到最後一個單詞,等於 x-$,可以省略前面的冒號 |
| x- | 從第 x 個單詞到倒數第二個單詞 |
表格三、對選取的單詞做什麼修飾:
| 操作符 | 功能 |
|---|---|
| h | 選取路徑開頭,不要檔名 |
| t | 選取路徑結尾,只要檔名 |
| r | 選取檔名,不要副檔名 |
| e | 選取副檔名,不要檔名 |
| s/oldstring/newstring/ | 將 oldstring 替換為 newstring |
| g | 全域性替換,和 s 配合使用 |
| p | 只打印修飾後的命令,不執行 |
這幾個命令其實挺好記的,h 代表 head,只要路徑開頭不要檔名,t 代表 tail,只要路徑結尾的檔名,r 代表 realname,只要檔名不要副檔名,e 代表 extension,只要副檔名不要檔名,s 代表 substitute,執行替換功能,g 代表 global,全域性替換,p 代表 print,只打印不執行。有時候光使用 :p 還不夠,我們還可以把這個經過引用修飾後的命令直接在當前命令列上展開而不立即執行,它的快捷鍵是:
| 操作符 | 功能 |
|---|---|
| Ctrl + Alt + E | 在當前命令列上展開歷史命令引用,展開後不立即執行,可以修改,按 Enter 後才會執行 |
| Alt + ^ | 和上面的功能一樣 |
這兩個快捷鍵,記住一個就行。這樣,當我們對歷史命令的引用修飾完成後,可以先展開來看一看,如果正確再執行。眼見為實嘛,反正我是每次都展開看看才放心。
使用 Tab 鍵進行補全
在使用命令列的時候,可以使用 Tab 鍵對命令和檔名進行補全。一般如果你輸入一條命令的前面幾個字元後,按 Tab 鍵兩次,將會提示所有可用的命令。輸入命令後,在輸入引數的位置,如果輸入了一個檔名的前幾個字元,按 Tab 鍵,Shell 會查詢當前目錄下的檔案,對檔名進行補全。或者在輸入引數的位置直接按兩次 Tab 鍵,將提示所有可用的檔名。效果如下:

快速切換當前目錄
在使用命令列時,可以使用cd命令切換當前目錄,但是,如果每次都輸入一個超長的目錄名,則會嚴重影響效率,特別是在多個目錄之間快速切換的時候。例如,在我前面幾篇中,經常需要進入/usr/share/backgrounds/contest目錄和/etc/fonts/conf.d目錄檢視配置檔案,也會進入/usr/src/linux-source-4.15.0目錄檢視核心原始碼,這些目錄名都比較長,如果每次都自己輸入,效率低不說,還容易出錯。這時,可以通過 Bash 提供的pushd命令和popd命令維護一個目錄堆疊,並使用dirs命令檢視目錄堆疊,使用pushd命令在目錄之間切換。效果如下圖:
這三個命令的具體引數如下:
1、dirs——顯示當前目錄棧中的所有記錄(不帶引數的dirs命令顯示當前目錄棧中的記錄)
格式:dirs [-clpv] [+n] [-n]
選項
-c 刪除目錄棧中的所有記錄
-l 以完整格式顯示
-p 一個目錄一行的方式顯示
-v 每行一個目錄來顯示目錄棧的內容,每個目錄前加上的編號
+N 顯示從左到右的第n個目錄,數字從0開始
-N 顯示從右到左的第n個日錄,數字從0開始2、pushd——pushd命令常用於將目錄加入到棧中,加入記錄到目錄棧頂部,並切換到該目錄;若pushd命令不加任何引數,則會將位於記錄棧最上面的2個目錄對換位置
格式:pushd [目錄 | -N | +N] [-n]
選項
目錄 將該目錄加入到棧頂,並執行"cd 目錄",切換到該目錄
+N 將第N個目錄移至棧頂(從左邊數起,數字從0開始)
-N 將第N個目錄移至棧頂(從右邊數起,數字從0開始)
-n 將目錄入棧時,不切換目錄3、popd——popd用於刪除目錄棧中的記錄;如果popd命令不加任何引數,則會先刪除目錄棧最上面的記錄,然後切換到刪除過後的目錄棧中的最上面的目錄
格式:popd [-N | +N] [-n]
選項
+N 將第N個目錄刪除(從左邊數起,數字從0開始)
-N 將第N個目錄刪除(從右邊數起,數字從0開始)
-n 將目錄出棧時,不切換目錄Bash 指令碼程式語言的本質:一切都是字串
下面,我將探討 Bash 指令碼語言中的美學與哲學。 這不是一篇 Bash 指令碼程式設計的教程,但是卻能讓人更加深入地瞭解 Bash 指令碼程式設計,更加快速地學習 Bash 指令碼程式設計。 閱讀以下內容,不需要你有 Bash 程式設計的經驗,但一定要和我一樣熱衷於探索各種程式語言的本質,感悟它們的魅力。
我們平時喜歡對程式語言進行分類,把程式語言分為面向過程的程式語言、面向物件的程式語言、函數語言程式設計語言等等。在我心中,我認為 Bash 就是一個面向字串的程式語言。Bash 指令碼語言的本質:一切皆是字串。 Bash 指令碼語言的一切哲學都圍繞著字串:它們從哪裡來?到哪裡去?使命是什麼? Bash 指令碼語言的一切美學都源自字串: 由鍵盤上幾乎所有的符號 “$ ~ ! # & ( ) [ ] { } | > < - . , ; * @ ' " ` \ ^” 排列組合而成的極富視覺衝擊力的、功能極其複雜的字串。
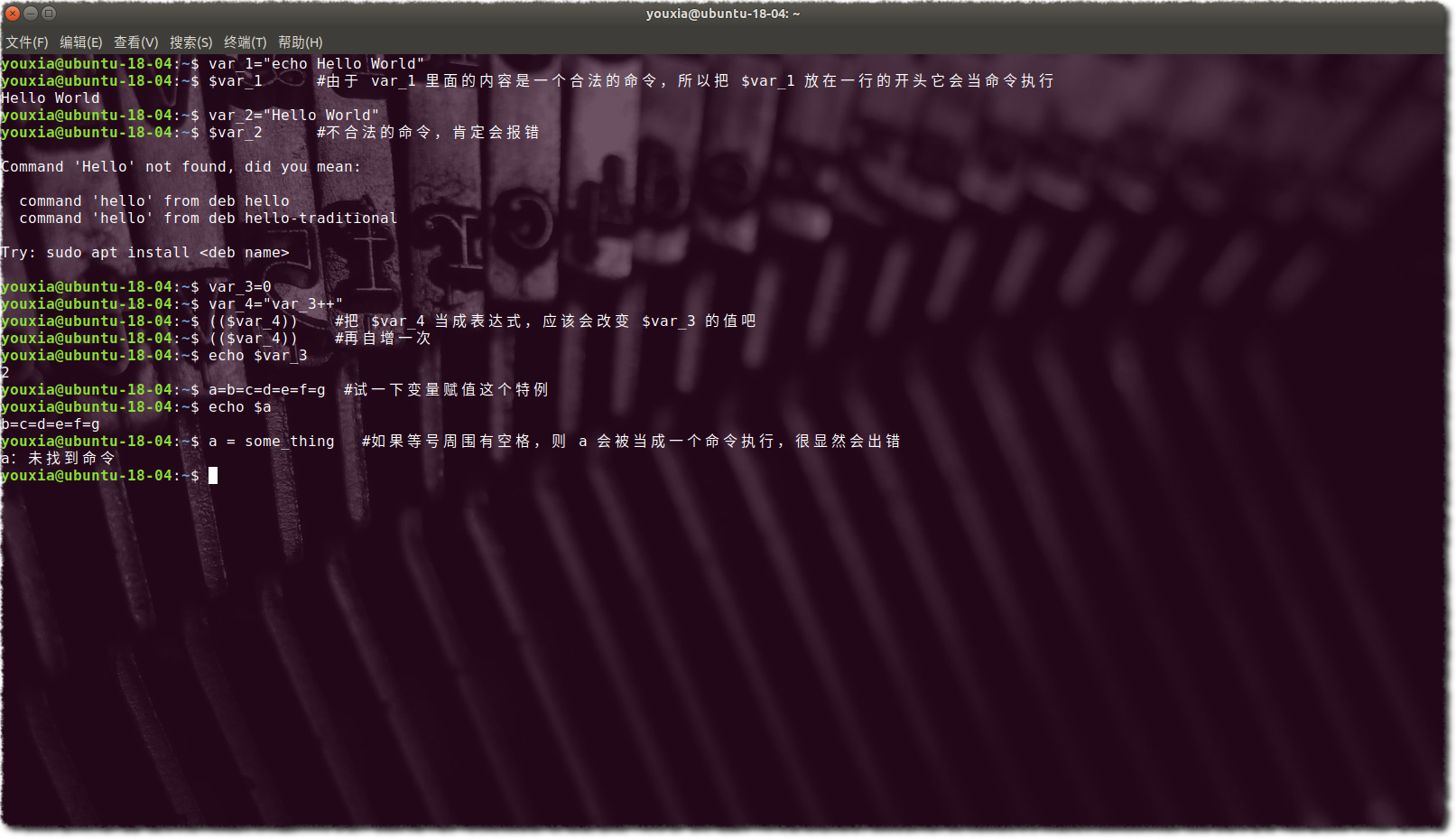
Bash 是一個 Shell,Shell 出現的初衷是為了將系統中的各種工具粘合在一起,所以它最根本的功能是呼叫各種命令。而命令以及命令的引數都是由字串組成的,所以 Bash 指令碼語言最終進化成一個面向字串的語言。 Bash 語言的本質就是:一切都是字串。 看看下圖中的這些變數:
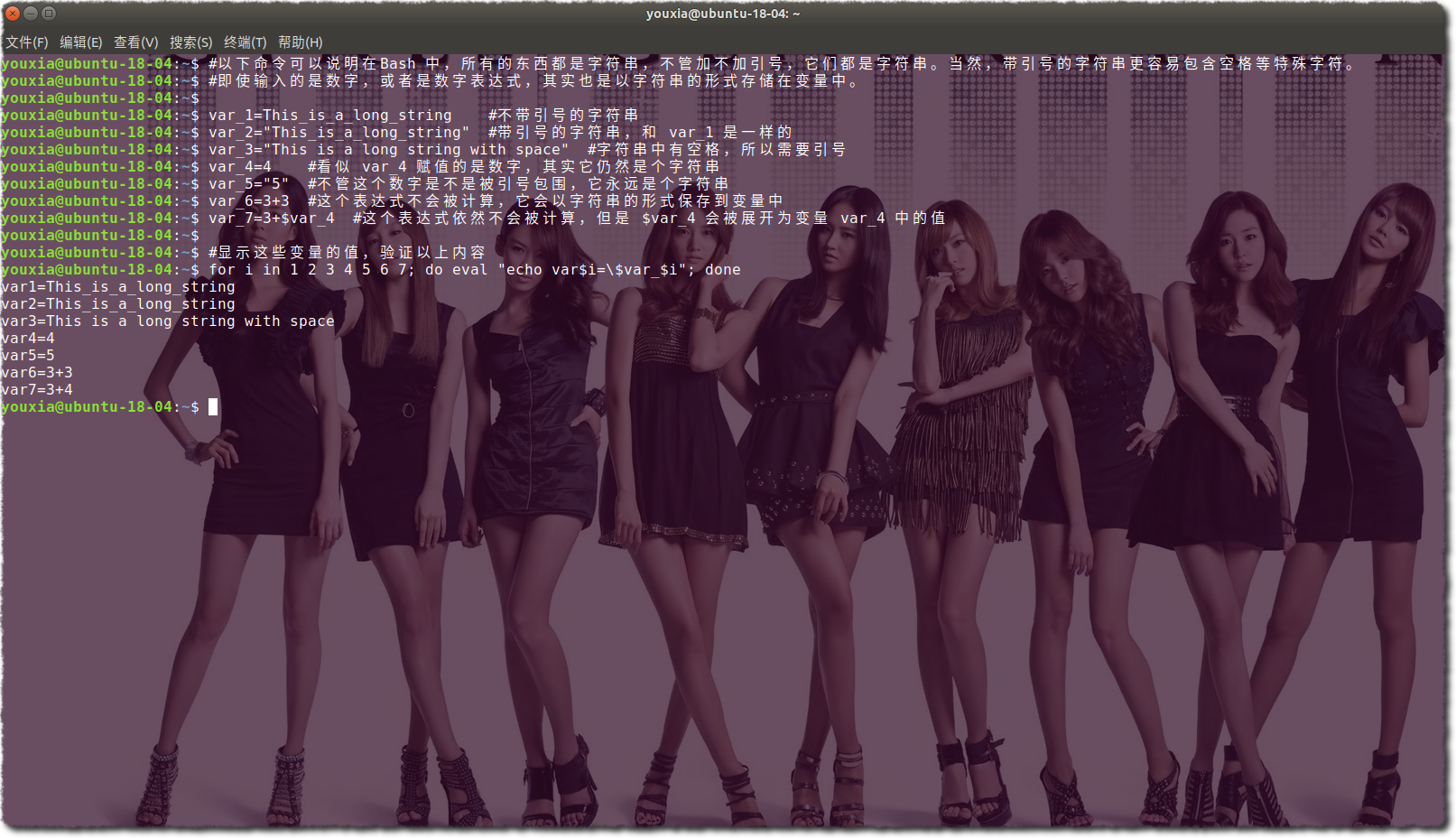
上圖是我在互動式的 Bash 命令列中做的一些演示。在上圖中,我對變數分別賦值,不管等號右邊是一個不帶引號的字串,還是帶有引號的字串,甚至數字,或者數學表示式,最終的結果,變數裡面儲存的都是字串。我使用一個 for 迴圈顯示所有的變數,可以看到數學表示式也只是以字串的形式儲存,沒有被求值。
Bash 指令碼程式語言中的引號、元字元和反斜槓
如果一切都是沒有特殊功能的平凡的字串,那就無法構成一門程式語言。在 Bash 中,有很多符號具有特殊含義,如$符號被用於字串展開,&符號用於讓命令在後臺執行, |用作管道,> <用於輸入輸出重定向等等。所以在 Bash 中,雖然同樣是字串,但是被引號包圍的字串和不被引號包圍的字串使用起來是不一樣的,被單引號包圍的字串和被雙引號包圍起來的字串也是不一樣的。
究竟帶引號的字串和不帶引號的字串使用起來有什麼不一樣呢?下圖是我構建的一些比較典型的例子:
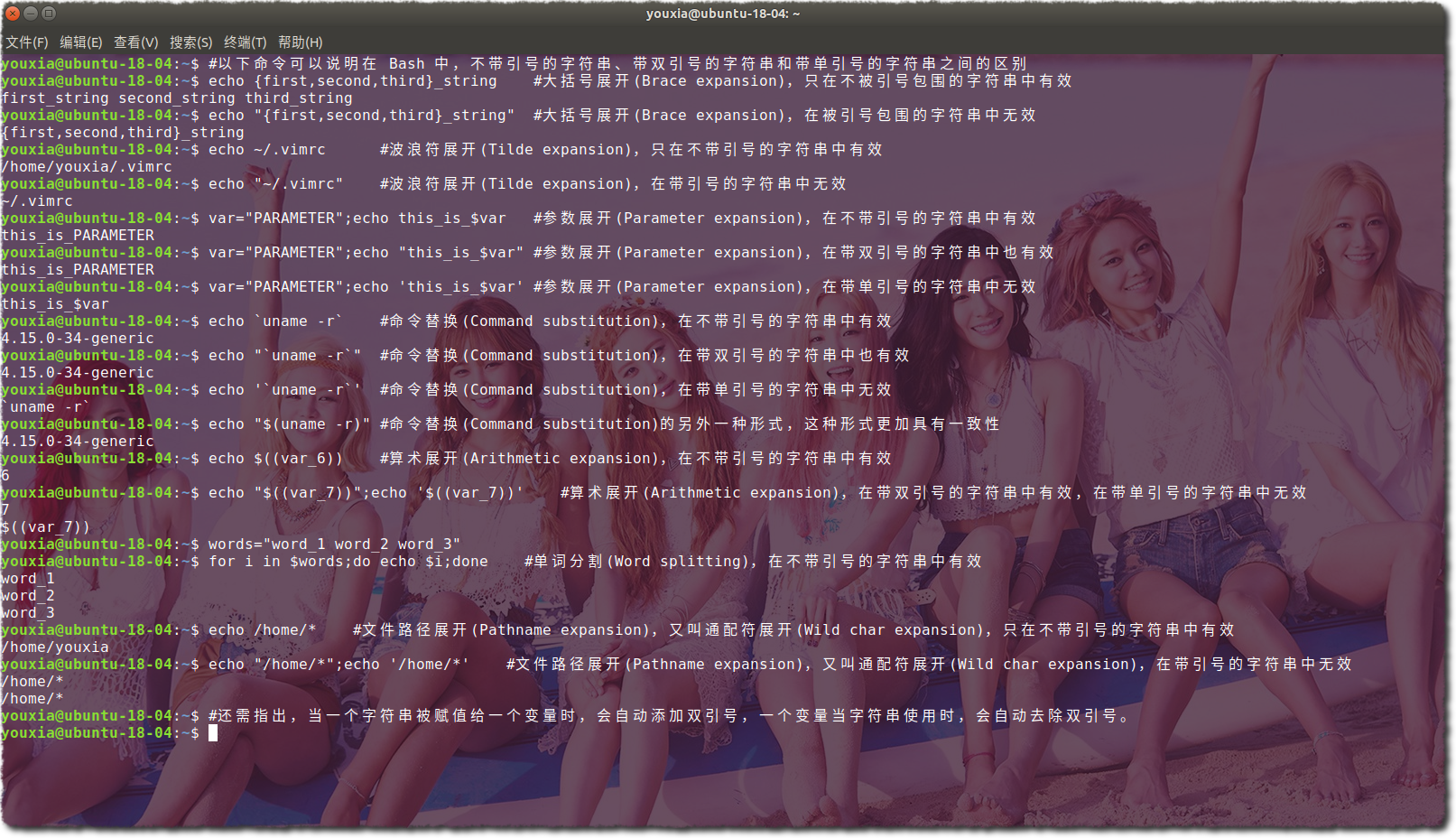
在上圖中,我展示了 Bash 中生成字串的 7 種方法:大括號展開、波浪符展開、引數展開、命令替換、算術展開、單詞分割和檔案路徑展開。還有歷史命令展開沒有在上圖展示,但是歷史命令展開在前面快速引用和修飾歷史命名那一節有展示,可以看到歷史命令展開都是使用!開頭的。在使用 Bash 指令碼程式設計的時候,瞭解以上 7 種字串生成的方式就夠了。在互動式使用 Bash 命令列的時候,才需要了解歷史命令展開,熟練使用歷史命令展開可以讓人事半功倍。
在上面的圖片中可以看到,有一些展開方式在被雙引號包圍的字串中是不起作用的,如大括號展開、波浪符展開、單詞分割、檔案路徑展開,而只有引數展開、命令替換和算術展開是起作用的。從圖片中還可以看出,字串中的引數展開、命令替換和算術展開都是由$符號引導,命令替換還可以由` 引導。所以,可以進一步總結為,在雙引號包圍的字串中,只有$ \ `這三個字元具有特殊含義。
如果想讓任何一個字元都不具有特殊含義,可以使用單引號將字串包圍,例如使用正則表示式的時候。還有就是在使用 sed、awk 等工具的時候,由於 sed 和 awk 自己執行的命令中往往包含有很多特殊字元,所以它們的命令最好用單引號包圍。 例如使用 awk 命令顯示/etc/passwd檔案中的每個使用者的使用者名稱和全名,可以使用這個命令awk -e '{print $1,$5}',其中,傳遞給 awk 的命令用單引號包圍,說明 bash 不執行其中的任何替換或展開。
另外一個特殊的字元是\,它也是引用的一種。它可以解除緊跟在它後面的一個特殊字元的特殊含義(引用)。之所以需要\的存在,是因為在 Bash 中,有些字元稱為元字元,這些字元一旦出現,就會將一個字串分割為多個子串。如果需要在一個字串中包含這些元字元本身,就必須對它們進行引用。如下圖:

最常見的元字元就是空格。 從上面幾張圖片可以看出,如果要將一個含有空格的字串賦值給一個變數,要麼把這個字串用雙引號包圍,要麼使用\對空格進行引用。 從上圖中可以看出,Bash 中只有9個元字元,它們分別是| & ( ) ; < > space tab,而在其它程式語言中經常出現的元字元. { } [ ]以及作為數學運算的加減乘除,在 Bash 中都不是元字元。
字串從哪裡來,到哪裡去
介紹完字串、介紹完引用和元字元,下一個目標就是來探討這一個哲學問題:字串從哪裡來、到哪裡去?通過該哲學問題的探討,可以推匯出 Bash 指令碼語言的整個語法。字串從哪裡來?很顯然,其中一個很直接的來源就是我們從鍵盤上敲上去的。除此之外,就是我前面提到的七八九種字串展開的方法了。
字串展開的流程如下:
1.先用元字元將一個字串分割為多個子串;
2.如果字串是用來給變數賦值,則不管它是否被雙引號包圍,都認為它被雙引號包圍;
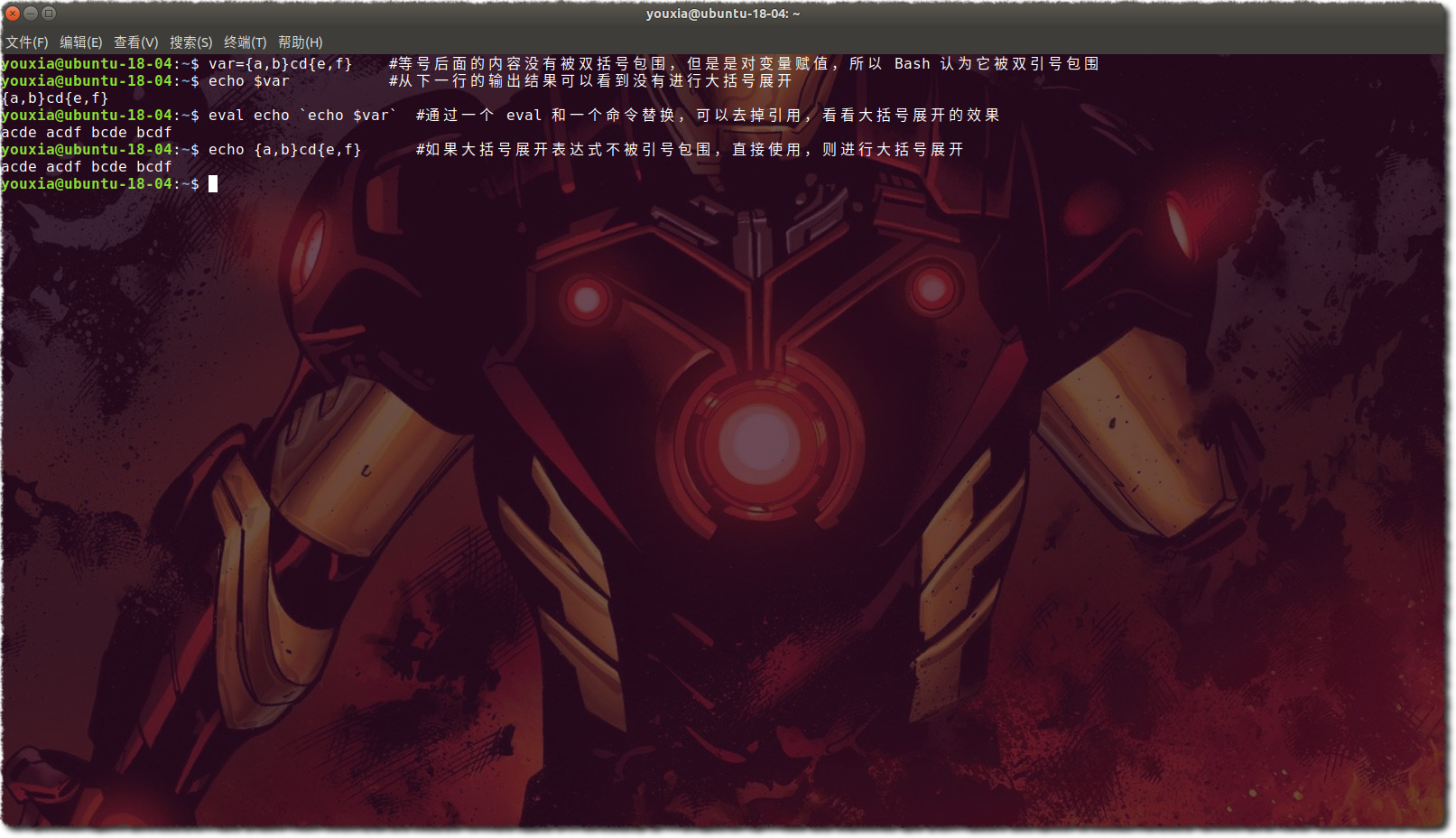
3.如果字串不被單引號和雙引號包圍,則進行大括號展開,即將 {a,b}c 展開為 ab ac;
以上三個流程可以通過下圖證明:
4.如果字串不被單引號或雙引號包圍,則進行波浪符展開,即將 ~/ 展開為使用者的主目錄,將 ~+/ 展開為當前工作目錄(PWD),將 ~-/ 展開為上一個工作目錄(OLDPWD);
5.如果字串不被單引號包圍,則進行引數和變數展開;這一類的展開全都以$開頭,這是整個 Bash 字串展開中最複雜的,其中包括使用者定義的變數,包括所有的環境變數,以上兩種展開方式都是$後跟變數名,還包括位置變數$1 $2 ... $9,其它特殊變數:[email protected] $* $# $- $! $0 $? $_,甚至還有陣列:${var[i]}, 還可以在展開的過程中對字串進行各種複雜的操作,如:${parameter:-word} ${parameter:=word} ${parameter:+word} ${parameter:?word} ${parameter:offset} ${parameter:offset:length} ${!prefix*} ${[email protected]} ${name[@]} ${!name[*]} ${#parameter} ${parameter#word} ${parameter##word} ${parameter%word} ${parameter%%word} ${parameter/pattern/string} ${parameter^pattern} ${parameter^^pattern} ${parameter,pattern} ${parameter,,pattern};
6.如果字串不被單引號包圍,則進行命令替換;命令替換有兩種格式,一種是 $(...),一種是 `...`;也就是將命令的輸出作為字串的內容;
7.如果字串不被單引號包圍,則進行算術展開;算術展開的格式為 $((...));
8.如果字串不被單引號或雙引號包圍,則進行單詞分割;
9.如果字串不被單引號或雙引號包圍,則進行檔案路徑展開;
10.以上流程全部完成後,最後去掉字串外面的引號(如果有的話)。以上流程只按以上順序進行一遍。不會在變數展開後再進行大括號展開,更不會在第 10 步去除引用後執行前面的任何一步。如果需要將流程再走一遍,請使用 eval。
探討完了字串從哪裡來,下面來看看字串到哪裡去。也就是怎麼使用這些字串。使用字串有以下幾種方式:
1.把它當命令執行;這是 Bash 中的最根本的用法,畢竟 Shell 的存在就是為了粘合各種命令。如果一個字串出現在本該命令出現的地方(一行的開頭,或者關鍵字 then、do 等的後面),它將會被當成命令執行,如果它不是個合法的命令,就會報錯;
2.把它當成表示式;Bash 中本沒有表示式,但是有了 ((...)) 和 [[...]],就有了表示式;((...)) 可以把它裡面的字串當成算術表示式,而 [[...]] 會把它裡面的字串當邏輯表示式,僅此兩個特例;
3.給變數賦值;這也是一個特例,有點破壞 Bash 程式語言語法哲學的完整性。為什麼這麼說呢?因為=即不是一個元字元,也不允許兩邊有空格,而且只有第 1 個等號會被當成賦值運算子。
下面圖片為以上觀點給出證據:
再加上一點點的定義,就可以推匯出整個 Bash 指令碼語言的語法了
前面我已經展示了我對字串從哪裡來、到哪裡去這個問題的理解。關於字串的去向,除了兩個表示式和一個為變數賦值這三個特例,剩下的就只有當命令來執行了。在前面,我提到了元字元和引用的概念,這裡,還得再增加一點點定義:
定義1:控制操作符(Control Operator) 前面提到元字元是為了把一個字串分割為多個子串,而控制操作符就是為了把一系列的字串分割成多個命令。舉例說明,在 Bash中,一個字串 cat /etc/passwd 就是一個命令,第一個單詞 cat 是命令,第 2 個單詞 /etc/passwd 是命令的引數,而字串 cat /etc/passwd | grep youxia 就是兩個命令,這兩個命令分別是 cat 和 grep,它們之間通過|分割,所以這裡的|是控制操作符。熟悉 Shell 的朋友肯定知道|代表的是管道,所以它的作用是:1.把一個字串分割為兩個命令,2.將第一個命令的輸出作為第二個命令的輸入。在 Bash 中,總共只有 10 個控制操作符,它們分別是|| & && | ; ;; () |& <newline>。只要看到這些控制操作符,就可以認為它前面的字串是一個完整的命令。
定義2:關鍵字(Reserved Words) 我沒有將其翻譯成保留字,很顯然,作為程式語言來說,它們應該叫做關鍵字。一門程式語言肯定必須得提供選擇、迴圈等流程控制語句,還得提供定義函式的功能。這些功能只能通過關鍵字實現。在 Bash 中,只有 22 個關鍵字,它們是“! case coproc do done elif else esac fi for function if in select then until while { } time [[ ]]”。這其中有不少的特別之處,比如“! { } [[ ]]”等符號都是關鍵字,也就是說它們當關鍵字使用時相當於一個單詞,也就是說它們和別的單詞必須以元字元分開(否則無法成為獨立的單詞)。這也是為什麼在 Bash 中使用“! { } [[ ]]”時經常要在它們周圍留空格的原因。(再一次證明=是一個很變態的特例,因為它既不是元字元,也不是控制操作符,更加不是關鍵字,它到底是什麼?)
下面開始推導 Bash 指令碼語言的語法:
推導1:簡單命令(Simple command) 就是一條簡單的命令,它可以是一個以上述控制操作符結尾的字串。比如單獨放在一行的 uname -r 命令(單獨放在一行的命令其實是以<newline>結尾,<newline>是控制操作符),或者雖然不單獨放在一行,但是以;或&結尾,比如 uname -r; who; pwd; gvim& 其中每一個命令都是一個簡單命令(當然,這四個命令放在一起的這行程式碼不叫簡單命令),;就是簡單地分割命令,而&還有讓命令在後臺執行的功能。這裡比較特殊的是雙分號;;,它只用在 case 語句中。
推導2:管道(Pipe Line) 管道是 Shell 中的精髓,就是讓前一個命令的輸出成為後一個命令的輸入。管道的完整語法是這樣 [time [-p]] [ ! ] command1 | command2 或這樣 [time [-p]] [ ! ] command1 |& command2 的。其中 time 關鍵字和 ! 關鍵字都是可選的(使用[...]指出哪些部分是可選的),time 關鍵字可以計算命令執行的時間,而 ! 關鍵字是將命令的返回狀態取反。看清楚 ! 關鍵字周圍的空格哦。如果使用|,就是把第一個命令的標準輸出作為第二個命令的標準輸入,如果使用|&,則將第一個命令的標準輸出和標準錯誤輸出都當成第二個命令的輸入。
推導3:命令序列(List) 如果多個簡單命令或多個管道放在一起,它們之間以; & <newline> || &&等控制操作符分開,就稱之為一個命令序列。關於||和&&,熟悉 C、C++、Java 等程式語言的朋友們肯定也不會陌生,它們遵循同樣的短路求值的思想。比如 command1 || command2 只有當 command1 執行不成功的時候才執行 command2,而 command1 && command2 只有當 command1 執行成功的時候才執行 command2。
推導4:複合命令(Compound Commands) 如果將前面的簡單命令、管道或者命令序列以更復雜的方式組合在一起,就可以構成複合命令。在 Bash 中,有 4 種形式的複合命令,它們分別是 (list) 、 { list; } 、 ((expression)) 、 [[ expression ]] 。請注意第 2 種形式和第 4 種形式大括號和中括號周圍的空格,也請注意第 2 種形式中 list 後面的;,不過如果}另起一行,則不需要;,因為<newline>和;是起同樣作用的。在以上4種複合命令中, (list) 是在一個新的Shell中執行命令序列,這些命令的執行不會影響當前Shell的環境變數,而 { list; } 只是簡單地將命令序列分組。後面兩種表示式求值前面已經講過,這裡就不講了。後面可能會詳細列出邏輯表示式求值的選項。
上面的4步推導是一步更進一步的,是由簡單逐漸到複雜的,最簡單的命令可以組合成稍複雜的管道,再組合成更復雜的命令序列,最後組成最複雜的複合命令。
下面是 Bash 指令碼語言的流程控制語句,如下:
1. for name [ [ in [ word ... ] ] ; ] do list ; done ;
2. for (( expr1 ; expr2 ; expr3 )) ; do list ; done ;
3. select name [ in word ] ; do list ; done ;
4. case word in [ [(] pattern [ | pattern ] ... ) list ;; ] ... esac ;
5. if list; then list; [ elif list; then list; ] ... [ else list; ] fi ;
6. while list-1; do list-2; done ;
7. until list-1; do list-2; done 。
上面的公式大家看得懂吧,我相信大家肯定看得懂。其中的 [...] 代表的是可以有也可以真沒有的部分。在以上公式中,請注意第 2 個公式 for 迴圈中的雙括號,它執行的是其中的表示式的算術運算,這是和其它高階語言的 for 迴圈最像的,但是很遺憾,Bash 中的算術表示式目前只能計算整數。再請注意第 3 個公式,select 語法,和 for...in... 迴圈的語法比較類似,但是它可以在螢幕上顯示一個選單。如果我沒有記錯的話,Basic 語言中應該有這個功能。其它的控制結構在別的高階語言中都很常見,就不需要我在這裡囉嗦了。
最後,再來展示一下如何定義函式:
name () compound-command [redirection]
或者
function name [()] compound-command [redirection]
可以看出,如果有 function 關鍵字,則()是可選的,如果沒有 function 關鍵字,則()是必須的。這裡需要特別指出的是:函式體只要求是 compound-command,我前面總結過 compound-command 有四種形式,所以有時候定義一個函式並不會出現{ }哦。如下圖,這樣的函式也是合法的:

That's all。這就是 Bash 指令碼語言的全部語法。就這麼簡單。
好像忘了點什麼?對了,還有輸入輸出重定向沒有講。輸入輸出重定向是 Shell 中又一個偉大的發明,它的存在有著它獨特的哲學意義。這個請看下一節。
輸入輸出重定向
Unix 世界有一個偉大的哲學:一切皆是檔案。(這個扯得有點遠。) Unix 世界還有一個偉大的哲學:建立程序比較方便。(這個扯得也有點遠。)而且,每一個程序一建立,就會自動開啟三個檔案,它們分別是標準輸入、標準輸出、標準錯誤輸出,普通情況下,它們連線到使用者的控制檯。在 Shell 中,使用數字來標識一個開啟的檔案,稱為檔案描述符,而且數字 0、 1、 2 分別代表標準輸入、標準輸出和標準錯誤輸出。在 Shell 中,可以通過>、<將命令的輸入、輸出進行重定向。結合 exec 命令,可以非常方便地開啟和關閉檔案。需要注意的是,當檔案描述符出現在>、<右邊的時候,前面要使用&符號,這可能是為了和數學表示式中的大於和小於進行區別吧。使用&-可以關閉檔案描述符。
> < & 數字 exec -,這就是輸入輸出重定向的全部。下面的公式中,我使用 n 代表數字,如果是兩個不同的數字,則使用 n1、n2,使用 [...] 代表可選引數。輸入輸出重定向的語法如下:
[n]> file #重定向標準輸出(或 n)到file。
[n]>> file #重定向標準輸出(或 n)到file,追加到file末尾。
[n]< file #將file重定向到標準輸入(或 n)。
[n1]>&n2 #重定向標準輸出(或 n1)到n2。
2> file >&2 #重定向標準輸出和錯誤輸出到file。
| command #將標準輸出通過管道傳遞給command。
2>&1 | command #將標準輸出和錯誤輸出一起通過管道傳遞給command,等同於|&。請注意,數字和>、<符號之間是沒有空格的。結合 exec,可以非常方便地使用一個檔案描述符來開啟、關閉檔案,如下:
echo Hello >file1
exec 3<file1 4>file2 #開啟檔案
cat <&3 >&4 #重定向標準輸入到 3,標準輸出到 4,相當於讀取file1的內容然後寫入file2
exec 3<&- 4>&- #關閉檔案
cat file2
#顯示結果為 Hello
#還可以暫存和恢復檔案描述符,如下:
exec 5>&2 #把原來的標準錯誤輸出儲存到檔案描述符5上
exec 2> /tmp/$0.log #重定向標準錯誤輸出
...
exec 2>&5 #恢復標準錯誤輸出
exec 5>&- #關閉檔案描述符5,因為不需要了還可以將<>一起使用,表示開啟一個檔案進行讀寫。
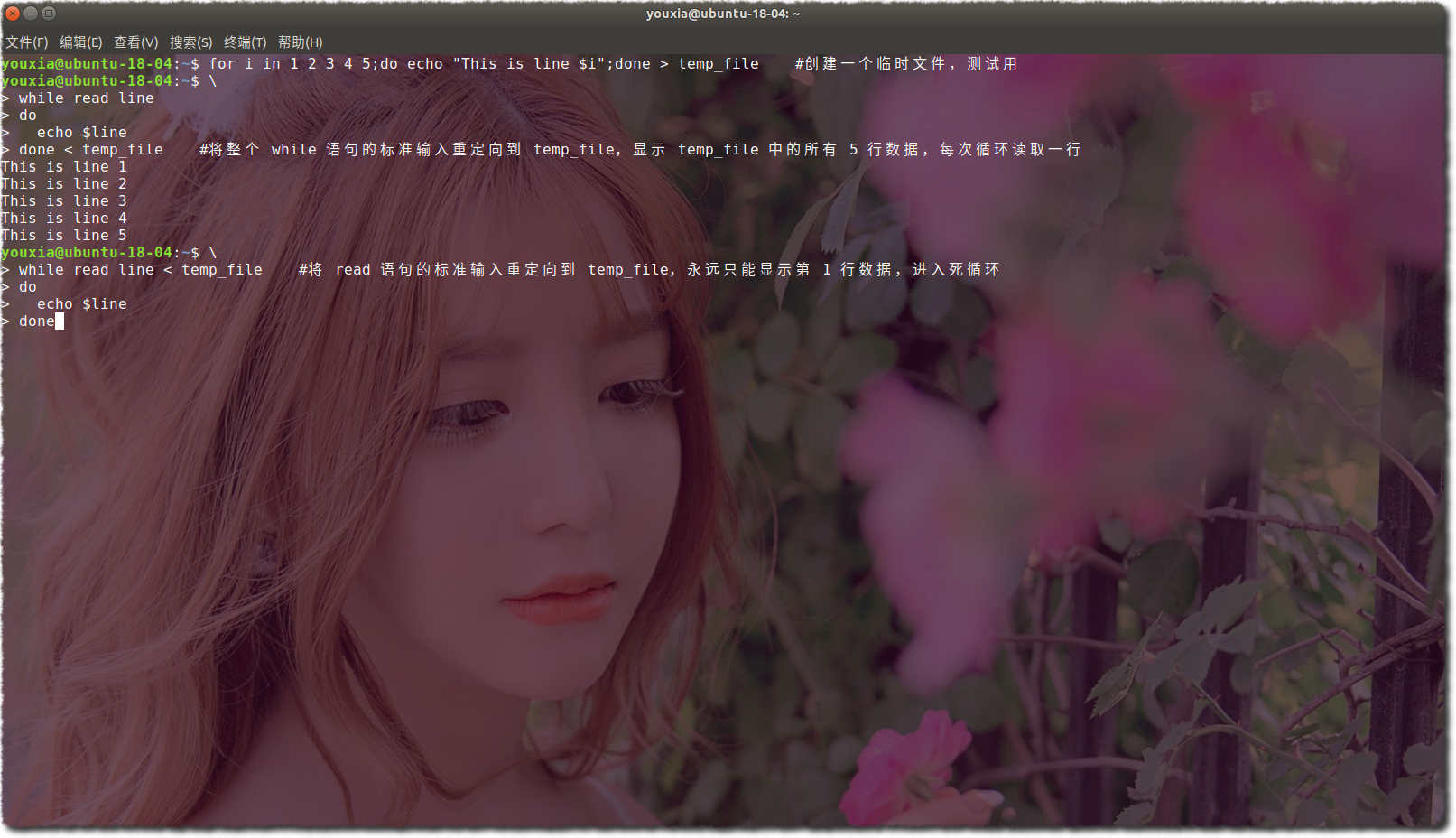
除了 exec,輸入輸出重定向和 read 命令配合也很好用,read 命令每次讀取檔案的一行。但是要注意的是,輸入輸出重定向放到 for、while 等迴圈的迴圈體和迴圈外,效果是不一樣的。如下圖:

另外,輸入輸出重定向符號>、<還可以和()一起使用,表示程序替換(Process substitution),如>(list)、<(list)。結合前面提到的<、>、(list)的含義,程序替換的作用是很容易猜到的哦。
Bash 指令碼語言的美學:大道至簡
如果你問我 Bash 指令碼語言哪裡美?我會回答:簡潔就是美。請看下面逐條論述:
1.使用了簡潔的抽象的符號。Bash 指令碼語言幾乎使用到了鍵盤上能夠找到的所有符號,$用作字串展開,|用作管道,<、>用作輸入輸出重定向,一點都不浪費;
2.只使用了 9 個元字元、10 個控制操作符和 22 個關鍵字,就構建了一個完整的、面向字串程式設計的語言;
3.概念上具有很好的一致性;例如 (list) 複合命令的功能是執行括號內的命令序列,而$用於引導字串展開,所以 $(list) 用於命令替換(所以我前面說$()形式的命令替換比`...`形式的命令替換更加具有一致性)。再例如 ((expresion)) 用於數學表示式求值,所以 $((expression)) 代表算術展開。再例如{}和,配合使用,且中間沒有空格時,代表大括號展開,但是當需要使用{ }來定義複合命令時,必須把{ }當關鍵字,它們和它裡面的內容必須以空格隔開,而且}和它前面的一條命令之間必須有一個;或者<newline>。這些概念上的一致性設計得非常精妙,使用起來自然而然可以讓人體會到一種美感;
4.完美解決了一個命令執行時的輸出和執行狀態的分離。有其它程式語言經歷的人也經常會遇到這樣的問題:當我們呼叫一個函式的時候,函式可能會產生兩個結果,一個是函式的返回值,一個是函式呼叫是否成功。在 C# 和 Java 等高階語言中,往往使用 try...catch 等捕獲異常的方式來判斷函式呼叫是否成功,但仍然有程式設計師讓函式返回 null 代表失敗,而 C 語言這種沒有異常機制的語言,實在是難以判斷一個函式的返回值究竟如何表示該函式呼叫是否成功(比如就有很多 API 讓函式返回 -1 代表失敗,而有的函式執行失敗是會設定 errno 全域性變數)。在 Bash 中,命令執行的狀態和命令的標準輸出區分很明確,如果你需要命令的標準輸出,使用命令替換來生成字串,如果你只需要命令的執行狀態,直接將命令寫在 if 語句之中即可,或者使用 $? 特殊變數來檢查上一條命令的執行狀態。如果不想在檢查命令執行狀態的時候讓命令的標準輸出影響使用者,可以把它重定向到 /dev/null,像這樣:
if cat /etc/passwd | grep youxia > /dev/null; then echo 'youxia is exist'; fi5.使用管道和輸入輸出重定向讓檔案的讀寫變得簡單。想一想在 C 語言中怎麼讀檔案吧,除了麻煩的 open、close 不說,每讀一個字串還得先準備一個 buffer,準備長了怕浪費空間,準備短了怕緩衝區溢位,虐心啦。使用 Bash,那真的是太方便了。
6.它還有邪惡的 eval 哦,eval 命令實在是太強大了,請看下圖,模擬指標進行查表:
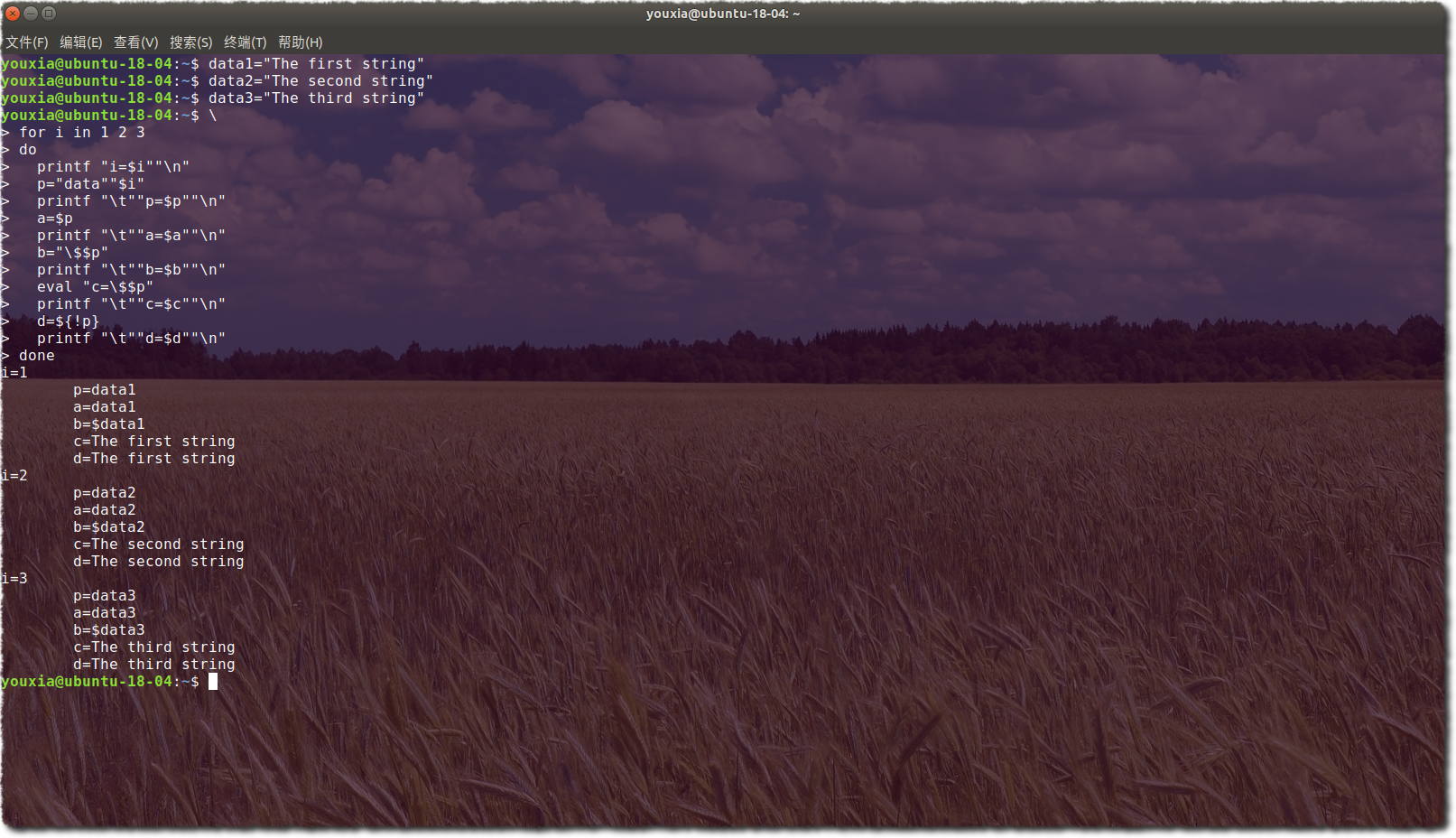
當然,自從 Bash 3 之後,Bash 本身就提供了間接引用的功能(使用“${!var}”)。
例外:
Bash 語言也並不是在所有的方面都是完美的,還存在幾個特別的例外,像前面說的=。除了=之外,()也有一個使用不一致的地方,那就是對陣列的初始化,例如 array=(a b c d e f) ,這和前面講的()用於在子 Shell 中執行命令序列還真的是不一致。
總結
以上內容是我的胡言亂語,因為以上內容即無法教會大家完整的 Bash 語法,也無法教會大家用 Bash 做任何一點有意義的工作。如果想用 Bash 乾點實事,建議大家閱讀 O'Reilly 出的《Shell指令碼學習指南》。
求打賞
我對這次寫的這個系列要求是非常高的:首先內容要有意義、夠充實,資訊量要足夠豐富;其次是每一個知識點要講透徹,不能模稜兩可含糊不清;最後是包含豐富的截圖,讓那些不想裝 Linux 系統的朋友們也可以領略到 Linux 桌面的風采。如果我的努力得到大家的認可,可以掃下面的二維碼打賞一下:

版權申明
該隨筆由京山遊俠在2018年10月04日釋出於部落格園,引用請註明出處,轉載或出版請聯絡博主。QQ郵箱:[email protected]