
如何設計一個高併發系統
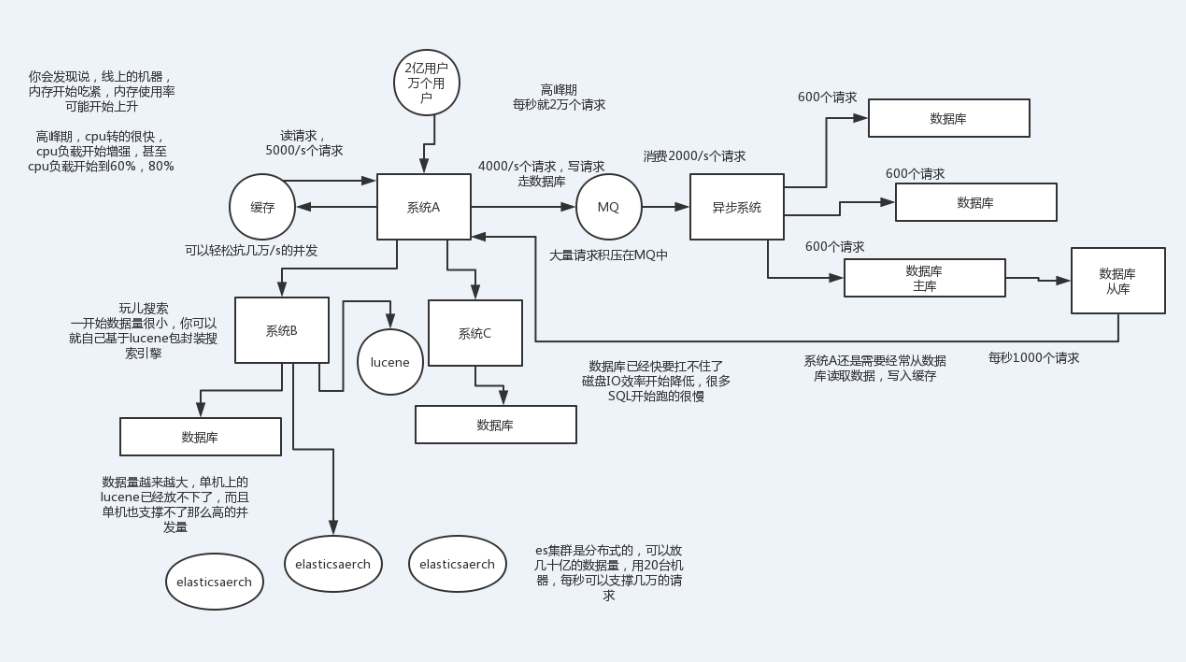
系統拆分,將一個系統拆分為多個子系統,用dubbo來搞。然後每個系統連一個數據庫,這樣本來就一個庫,現在多個數據庫,不也可以抗高併發麼。
快取,必須得用快取。大部分的高併發場景,都是讀多寫少,那你完全可以在資料庫和快取裡都寫一份,然後讀的時候大量走快取不就得了。畢竟人家redis輕輕鬆鬆單機幾萬的併發啊。沒問題的。所以你可以考慮考慮你的專案裡,那些承載主要請求的讀場景,怎麼用快取來抗高併發。
MQ,必須得用MQ。可能你還是會出現高併發寫的場景,比如說一個業務操作裡要頻繁搞資料庫幾十次,增刪改增刪改。那高併發絕對搞掛你的系統,你要是用redis來承載寫那肯定不行,人家是快取,資料隨時就被LRU了,資料格式還無比簡單,沒有事務支援。所以該用mysql還得用mysql啊。那你咋辦?用MQ吧,大量的寫請求灌入MQ裡,排隊慢慢玩兒,後邊系統消費後慢慢寫,控制在mysql承載範圍之內。所以你得考慮考慮你的專案裡,那些承載複雜寫業務邏輯的場景裡,如何用MQ來非同步寫,提升併發性。MQ單機抗幾萬併發也是ok的。
分庫分表,可能到了最後資料庫層面還是免不了抗高併發的要求,好吧,那麼就將一個數據庫拆分為多個庫,多個庫來抗更高的併發;然後將一個表拆分為多個表,每個表的資料量保持少一點,提高sql跑的效能。
讀寫分離,這個就是說大部分時候資料庫可能也是讀多寫少,沒必要所有請求都集中在一個庫上吧,可以搞個主從架構,主庫寫入,從庫讀取,搞一個讀寫分離。讀流量太多的時候,還可以加更多的從庫。
Elasticsearch,可以考慮用es。es是分散式的,可以隨便擴容,分散式天然就可以支撐高併發,因為動不動就可以擴容加機器來抗更高的併發。那麼一些比較簡單的查詢、統計類的操作,可以考慮用es來承載,還有一些全文搜尋類的操作,也可以考慮用es來承載。
轉自:中華石杉Java工程師面試突擊