
Kears入門之基礎篇
本文轉載自http://www.cnblogs.com/lc1217/p/7132364.html
1.關於Keras
1)簡介
Keras是由純python編寫的基於theano/tensorflow的深度學習框架。
Keras是一個高層神經網路API,支援快速實驗,能夠把你的idea迅速轉換為結果,如果有如下需求,可以優先選擇Keras:
a)簡易和快速的原型設計(keras具有高度模組化,極簡,和可擴充特性)
b)支援CNN和RNN,或二者的結合
c)無縫CPU和GPU切換
2)設計原則
a)使用者友好:Keras是為人類而不是天頂星人設計的API。使用者的使用體驗始終是我們考慮的首要和中心內容。Keras遵循減少認知困難的最佳實踐:Keras提供一致而簡潔的API, 能夠極大減少一般應用下使用者的工作量,同時,Keras提供清晰和具有實踐意義的bug反饋。
b)模組性:模型可理解為一個層的序列或資料的運算圖,完全可配置的模組可以用最少的代價自由組合在一起。具體而言,網路層、損失函式、優化器、初始化策略、啟用函式、正則化方法都是獨立的模組,你可以使用它們來構建自己的模型。
c)易擴充套件性:新增新模組超級容易,只需要仿照現有的模組編寫新的類或函式即可。建立新模組的便利性使得Keras更適合於先進的研究工作。
d)與Python協作:Keras沒有單獨的模型配置檔案型別(作為對比,caffe有),模型由python程式碼描述,使其更緊湊和更易debug,並提供了擴充套件的便利性。
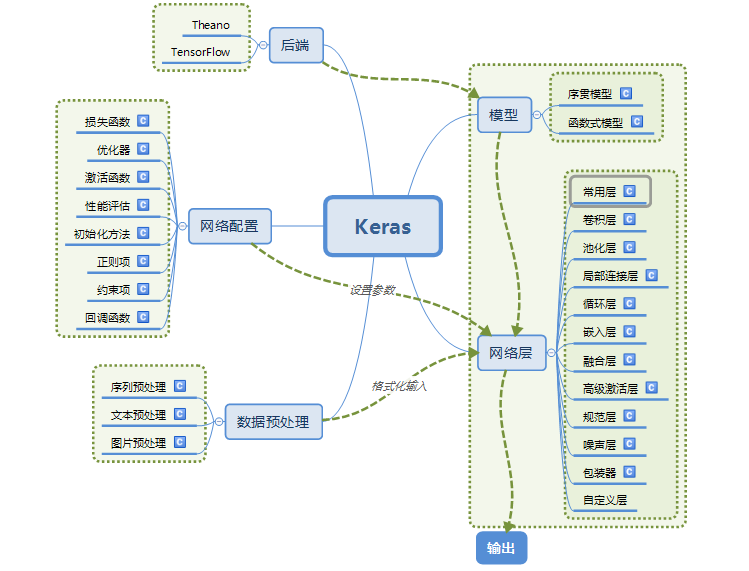
2.Keras的模組結構
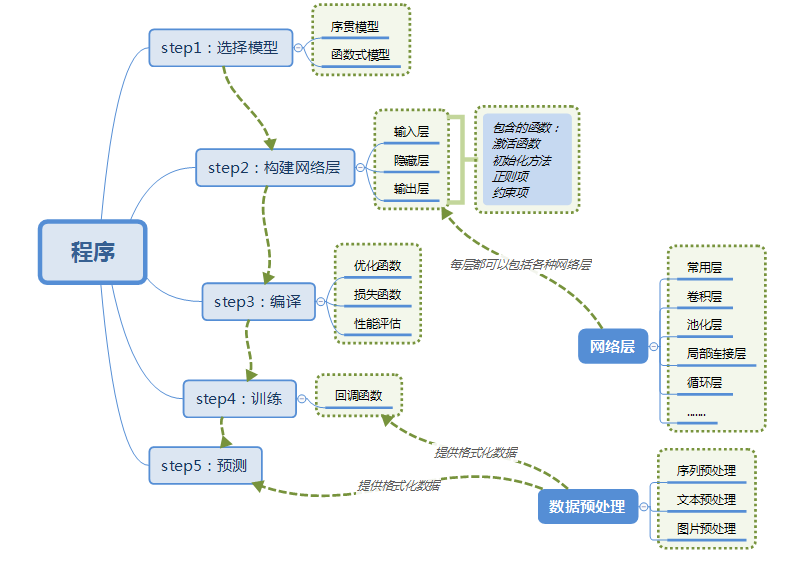
3.使用Keras搭建一個神經網路
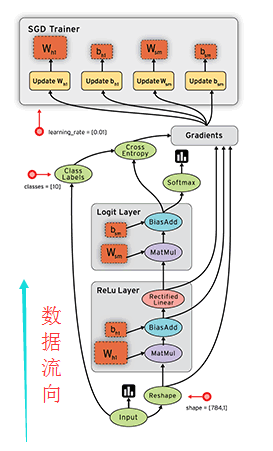
4.主要概念
1)符號計算
Keras的底層庫使用Theano或TensorFlow,這兩個庫也稱為Keras的後端。無論是Theano還是TensorFlow,都是一個“符號式”的庫。符號計算首先定義各種變數,然後建立一個“計算圖”,計算圖規定了各個變數之間的計算關係。
符號計算也叫資料流圖,其過程如下(gif圖不好開啟,所以用了靜態圖,資料是按圖中黑色帶箭頭的線流動的):
2)張量
張量(tensor),可以看作是向量、矩陣的自然推廣,用來表示廣泛的資料型別。張量的階數也叫維度。
0階張量,即標量,是一個數。
1階張量,即向量,一組有序排列的數
2階張量,即矩陣,一組向量有序的排列起來
3階張量,即立方體,一組矩陣上下排列起來
4階張量......
依次類推
重點:關於維度的理解
假如有一個10長度的列表,那麼我們橫向看有10個數字,也可以叫做10維度,縱向看只能看到1個數字,那麼就叫1維度。注意這個區別有助於理解Keras或者神經網路中計算時出現的維度問題。
3)資料格式(data_format)
目前主要有兩種方式來表示張量:
a) th模式或channels_first模式,Theano和caffe使用此模式。
b)tf模式或channels_last模式,TensorFlow使用此模式。
下面舉例說明兩種模式的區別:
對於100張RGB3通道的16×32(高為16寬為32)彩色圖,
th表示方式:(100,3,16,32)
tf表示方式:(100,16,32,3)
唯一的區別就是表示通道個數3的位置不一樣。
4)模型
Keras有兩種型別的模型,序貫模型(Sequential)和函式式模型(Model),函式式模型應用更為廣泛,序貫模型是函式式模型的一種特殊情況。
a)序貫模型(Sequential):單輸入單輸出,一條路通到底,層與層之間只有相鄰關係,沒有跨層連線。這種模型編譯速度快,操作也比較簡單
b)函式式模型(Model):多輸入多輸出,層與層之間任意連線。這種模型編譯速度慢。
5.第一個示例
這裡也採用介紹神經網路時常用的一個例子:手寫數字的識別。
在寫程式碼之前,基於這個例子介紹一些概念,方便大家理解。
PS:可能是版本差異的問題,官網中的引數和示例中的引數是不一樣的,官網中給出的引數少,並且有些引數支援,有些不支援。所以此例子去掉了不支援的引數,並且只介紹本例中用到的引數。
1)Dense(500,input_shape=(784,))
a)Dense層屬於網路層-->常用層中的一個層
b) 500表示輸出的維度,完整的輸出表示:(*,500):即輸出任意個500維的資料流。但是在引數中只寫維度就可以了,比較具體輸出多少個是有輸入確定的。換個說法,Dense的輸出其實是個N×500的矩陣。
c)input_shape(784,) 表示輸入維度是784(28×28,後面具體介紹為什麼),完整的輸入表示:(*,784):即輸入N個784維度的資料
2)Activation('tanh')
a)Activation:啟用層
b)'tanh' :啟用函式
3)Dropout(0.5)
在訓練過程中每次更新引數時隨機斷開一定百分比(rate)的輸入神經元,防止過擬合。
4)資料集
資料集包括60000張28×28的訓練集和10000張28×28的測試集及其對應的目標數字。如果完全按照上述資料格式表述,以tensorflow作為後端應該是(60000,28,28,3),因為示例中採用了mnist.load_data()獲取資料集,所以已經判斷使用了tensorflow作為後端,因此資料集就變成了(60000,28,28),那麼input_shape(784,)應該是input_shape(28,28,)才對,但是在這個示例中這麼寫是不對的,需要轉換成(60000,784),才可以。為什麼需要轉換呢?
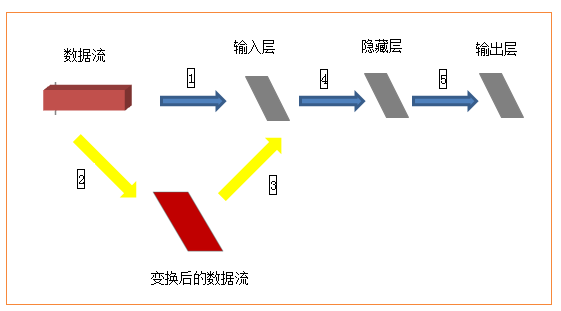
如上圖,訓練集(60000,28,28)作為輸入,就相當於一個立方體,而輸入層從當前角度看就是一個平面,立方體的資料流怎麼進入平面的輸入層進行計算呢?所以需要進行黃色箭頭所示的變換,然後才進入輸入層進行後續計算。至於從28*28變換成784之後輸入層如何處理,就不需要我們關心了。(喜歡鑽研的同學可以去研究下原始碼)。
並且,Keras中輸入多為(nb_samples, input_dim)的形式:即(樣本數量,輸入維度)。
5)示例程式碼
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from keras.optimizers import SGD
from keras.datasets import mnist
import numpy
'''
第一步:選擇模型
'''
model = Sequential()
'''
第二步:構建網路層
'''
model.add(Dense(500,input_shape=(784,))) # 輸入層,28*28=784
model.add(Activation('tanh')) # 啟用函式是tanh
model.add(Dropout(0.5)) # 採用50%的dropout
model.add(Dense(500)) # 隱藏層節點500個
model.add(Activation('tanh'))
model.add(Dropout(0.5))
model.add(Dense(10)) # 輸出結果是10個類別,所以維度是10
model.add(Activation('softmax')) # 最後一層用softmax作為啟用函式
'''
第三步:編譯
'''
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True) # 優化函式,設定學習率(lr)等引數
model.compile(loss='categorical_crossentropy', optimizer=sgd, class_mode='categorical') # 使用交叉熵作為loss函式
'''
第四步:訓練
.fit的一些引數
batch_size:對總的樣本數進行分組,每組包含的樣本數量
epochs :訓練次數
shuffle:是否把資料隨機打亂之後再進行訓練
validation_split:拿出百分之多少用來做交叉驗證
verbose:屏顯模式 0:不輸出 1:輸出進度 2:輸出每次的訓練結果
'''
(X_train, y_train), (X_test, y_test) = mnist.load_data() # 使用Keras自帶的mnist工具讀取資料(第一次需要聯網)
# 由於mist的輸入資料維度是(num, 28, 28),這裡需要把後面的維度直接拼起來變成784維
X_train = X_train.reshape(X_train.shape[0], X_train.shape[1] * X_train.shape[2])
X_test = X_test.reshape(X_test.shape[0], X_test.shape[1] * X_test.shape[2])
Y_train = (numpy.arange(10) == y_train[:, None]).astype(int)
Y_test = (numpy.arange(10) == y_test[:, None]).astype(int)
model.fit(X_train,Y_train,batch_size=200,epochs=50,shuffle=True,verbose=0,validation_split=0.3)
model.evaluate(X_test, Y_test, batch_size=200, verbose=0)
'''
第五步:輸出
'''
print("test set")
scores = model.evaluate(X_test,Y_test,batch_size=200,verbose=0)
print("")
print("The test loss is %f" % scores)
result = model.predict(X_test,batch_size=200,verbose=0)
result_max = numpy.argmax(result, axis = 1)
test_max = numpy.argmax(Y_test, axis = 1)
result_bool = numpy.equal(result_max, test_max)
true_num = numpy.sum(result_bool)
print("")
print("The accuracy of the model is %f" % (true_num/len(result_bool)))