
KafkaStream-高級別API
使用Streams DSL構建一個處理器拓撲,開發者可以使用KStreamBuilder類,它是TopologyBuilder的擴充套件。在Kafka原始碼的streams/examples包中有一個簡單的例子。另外本節剩餘的部分將通過一些程式碼來展示使用Streams DSL建立拓撲的關鍵的步驟。但是我們推薦開發者閱讀更詳細完整的原始碼。
1.1 Duality of Streams and Tables(流和表的對偶性)
我們討論Kafka Streams聚合等概念之前,我們必須首先介紹表,和最重要的表和流之間的關係:所謂的流表對偶性。本質上,這種二元性意味著一個流可以被視為一個表,反之亦然。例如,Kafka的日誌壓縮功能也利用了對偶性。
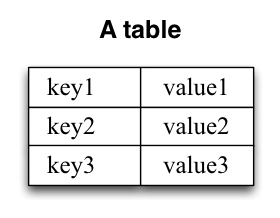
表的格式是一個簡單的key-value對的集合,也稱為map或關係陣列。看起來像這樣:
流表二元性描述了流和表之間的緊密關係。
流作為表:一個流可以認為是一個表的變更日誌,其中在流中的每個的資料記錄捕獲表的狀態變化。因此,流其實是一個偽裝的表,並且可以通過從開始到結束重放變更日誌來很容地重構“真實”表。同樣,在更多類比中,在流中聚合資料記錄 - 例如根據使用者的訪問事件統計總量。- 將返回一個表。(這裡的key和value分別是使用者和其對應的網頁遊覽量。)
表作為流:表可以認為是在流中的每個key的最新value的一個時間點的快照(流的資料記錄是key-value對)。因此,表也可以認為是偽裝的流,它可以通過對錶中每個key-value進行迭代而容易的轉換成“真實”流。
讓我們用一個例子來說明這一點,假設有一張表,用於跟蹤使用者的總遊覽量(下圖第一列)。隨著時間的推移,每當處理新的網頁遊覽時,相應的更新表的狀態。這裡,不同時間點之間狀態的改變 - 以及表的不同的更新- 表示為變更日誌流(第二列)。
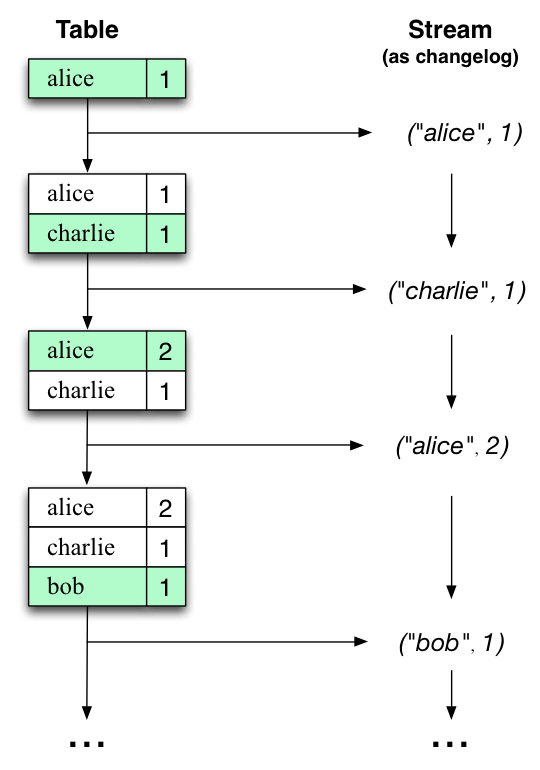
有趣的是,由於流表的對偶性,同一個流可以用來重建原始表(第三列):
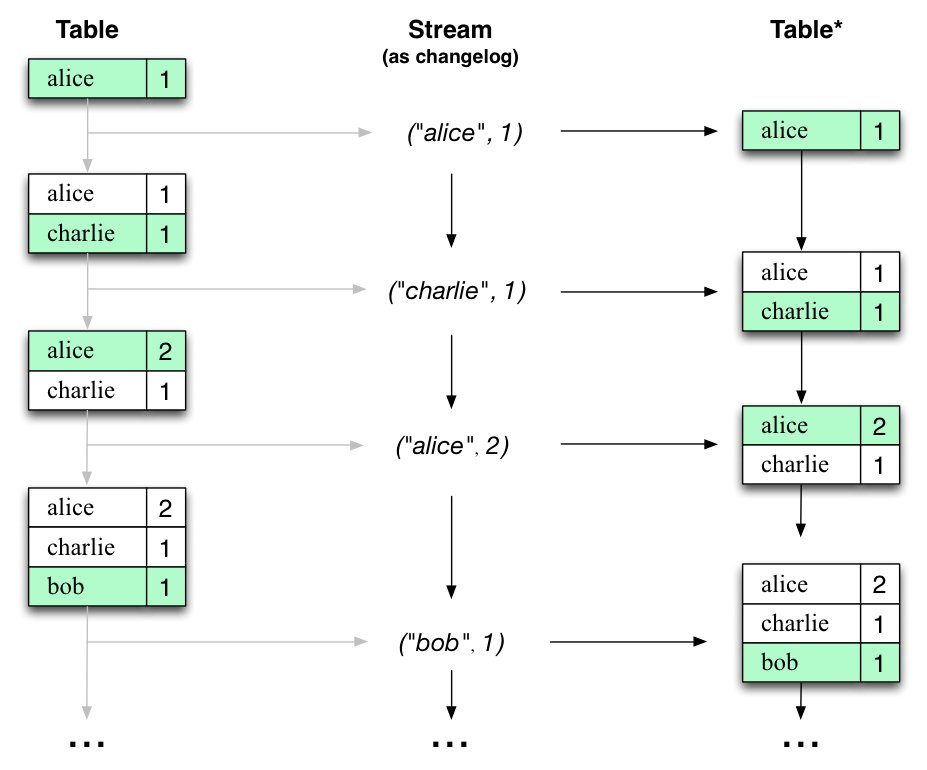
例如,使用相同的機制,通過變更日誌捕獲(CDC)複製資料庫,並在Kafka Streams中,在機器之間複製其所謂的狀態儲存,以實現容錯。
流表的對偶性是一個重要的概念,Kafka Streams通過KStream,KTable,和GlobalKTable介面模型。我們將在下面的章節中描述。
1.2 KStream, KTable, GlobalKTable
DSL有3個主要的抽象概念。KStream是一個訊息流抽象,其中每個資料記錄代表在無界資料集裡的自包含資料。KTable是一個變更日誌流的抽象,其中每個資料記錄代表一個更新。更確切的說,資料記錄中的value是相同記錄key的最後一條的更新(如果key存在,如果key還不存在,則更新將被認為是建立)。類似於Ktable,GlobalKTable也是一個變更日誌流的抽象。其中每個資料記錄代表一個更新。但是,不同於KTable,它是完全的複製每個KafkaStreams例項。同樣,GlobalKTable也提供了通過key查詢當前資料值的能力(通過join操作)。為了說明KStreams和KTables/ GlobalKTables之間的區別,讓我們想想一下兩個資料記錄傳送到流中:
("alice", 1) --> ("alice", 3)
假設流處理應用程式是求總和,如果這個是KStream,它將返回4。如果是KTable或GlobalKTable,將返回的是3,因為最後的記錄被認為是一個更新動作。
建立源流
錄流(KStreams)或變更日誌流(KTable或GlobalkTable)可以從一個或多個Kafka主題建立源流,(而KTable和GlobalKTable,只能從單個主題建立源流)。
KStreamBuilder builder = new KStreamBuilder();
KStream<String, GenericRecord> source1 = builder.stream("topic1", "topic2");
KTable<String, GenericRecord> source2 = builder.table("topic3", "stateStoreName");
GlobalKTable<String, GenericRecord> source2 = builder.globalTable("topic4", "globalStoreName");
1.3 Windowing a stream(視窗流)
流處理器可能需要將資料記錄劃分為時間段。即,通過時間視窗。通常用於連線和聚合操作等。Kafka Streams當前定義了一下的型別視窗:
- 跳躍時間視窗是基於時間間隔的視窗。此模式固定大小,(可能)重疊的視窗。通過2個屬性來定義跳躍視窗:視窗的大小和其前進間隔(又叫“跳躍”)。前進間隔是根據前一個視窗來指定向前移動多少。例如,你可以配置一個跳躍視窗,大小為5分鐘,前進間隔是1分鐘。由於跳躍視窗可以重疊。因此資料記錄可以屬於多於一個這樣的視窗。
- 滾動時間視窗是跳躍時間視窗的特殊情況,並且像後者一樣,也是基於時間間隔。其模型固定大小,非重疊,無間隔視窗。滾動視窗是通過單個屬性來定義的:視窗的大小。滾動視窗等於其前進間隔的跳躍視窗大小。由於滾動視窗不會重疊,資料記錄僅屬於一個且僅有一個視窗。
- 滑動視窗模式是基於時間軸的連續滑動的固定大小的視窗。如果它們的時間戳的差在視窗大小內,則兩個資料記錄包含在同一個視窗中。因此,滑動視窗不和epoch對準,而是與資料時間戳對準。在Kafka Streams中,滑動視窗僅用於join操作,並且可通過JoinWindows類指定。
- 會話視窗(Session windows)是基於key事件聚合成會話。會話表示一個活動期間,由不活動間隔分割定義的。在任何現有會話的不活動間隔內處理的任何事件都將合併到現有的會話中。如果事件在會話間隔之外,那麼將建立新的會話。會話視窗獨立的跟蹤的key(即,不同key的視窗通常開始和結束時間不同)和它們大小的變化(即使相同的key的視窗大小通常都不同)。因為這樣session視窗不能被預先計算,而是從資料記錄的時間戳分析獲取的。
在Kafka Streams DLS中,開發者可以指定保留視窗的週期。允許保留舊的視窗段一段時間。為了等待晚到的記錄(時間戳落在視窗間隔內的)。如果記錄過了保留週期之後到達,則不能處理,並將該其刪除。
在實時資料流中,晚到的記錄始終是可能的。這取決於如何有效的處理延遲記錄。利用處理時間,語義是何時處理資料,這意味著延遲記錄的概念不適用這個,因為根據定義,沒有記錄會晚到。因此,晚到的記錄實際上可以被認為是事件時間或嚥下時間(ingestion-time)。在這兩種情況下,Kafka Streams能正常處理晚到的訊息。
Join multiple streams(連線多個流)
join(連線,加入)操作基於其資料記錄的key來合併兩個流,併產生一個新的流。在記錄流上通常需要在視窗的基礎上執行連線,否則為了執行連線必須保持記錄的數量可以無限增長。在Kafka Streams中,可以執行以下連線操作:
- KStream對Kstreams連線始終基於視窗,否則記憶體和狀態需要計算加入的無限增長大小。這裡,從流中新接收的記錄與指定視窗間隔內的其他流的記錄相連線,為每個匹配生成一個結果(基於使用者提供的ValueJoiner)。新KStream例項表示從此操作者返回join流的結果。
- KTable對KTable連線連線操作設計和關係型資料庫中連線操作一致。這裡,兩個變更日誌流首先是本地狀態儲存。當從流中接收新的記錄時,它與其他流的狀態倉庫相結合,為每個匹配對生成一個結果(基於使用者提供的ValueJoiner)。新KTable例項表示連線流的結果,它也代表表的變更日誌流,從此操作人返回。
- KStream對KTable連線允許當你從另一個記錄流(KStream)接受到新記錄時,針對變更日誌劉(KTabloe)執行表查詢。例如,用最新的使用者個人資訊(KTable)來填充豐富使用者的活動流(KStream)。只有從記錄流接受的記錄觸發連線並通過ValueJoiner生成結果,反之(即,從變更日誌流接收的記錄將只更新狀態倉庫)。新的KStream表示該操作者返回的接入結果流。
- KStream對GlobalKTable連線允許你基於從其他記錄流(KStream)接受到新記錄時,針對一個完整複製的變更日誌流(GlobalKTable)執行表查詢。連線GlobalKTable不需要重新分配輸入KStream,因為GlobalKTable的所有分割槽在每個KafkaStreams例項中都可用。與連線操作一起提供的KeyValueMapper應用到每個KStream記錄,提取用於查詢GlobalKTable的連線key,從而可以進行非記錄key連線。例如,用最新的使用者個人資訊(GlobalKTable)來豐富使用者活躍流(KStream)。只有從記錄流接收的記錄觸發連線併產生結果(通過ValueJoiner),反之亦然(即,從變更日誌流接收的記錄僅被用於更新狀態倉庫)。新的KStream例項代表從該操作者返回的連線結果流。
根據運算元,支援以下連線操作:內部連線,外部連線和左連線。類似於關係型資料庫。
1.4 聚合流
聚合操作採用一個輸入流,並通過將多個輸入記錄合併成單個輸出記錄來產生一個新的流。計算數量或總數的例子,記錄流上通常需要在視窗基礎上執行聚合,否則為了執行聚合操作必須保持記錄數可以無限地增長。
在Kafka Streams DSL中,聚合操作的輸入流可以是KStream或KTable,但是輸出流將始終是KTable,允許Kafka Streams在生成或發出之後,最後抵達的記錄更新聚合的值。當這種晚到到達的記錄發生,聚合KStream或KTtable只是發出一個新的聚合值。由於輸出是KTable,所以在後續的處理步驟中,具有key的舊值將被新值覆蓋。
1.5 轉換流
除了join(連線)和聚合操作之外,KStream和KTable各自提供其他的轉換操作。這些操作每一個都可以生成一個或多個KStream和Ktable物件,並可以轉換成一個或多個連線的處理器到底層處理器拓撲中。所有這些轉換方法可以連結在一起構成一個複雜的處理器拓撲。由於KSteram和KTable是強型別的,所有轉換操作都被定義為泛型,使用者可以在其中指定輸出和輸出資料的型別。
這些轉換中,filter,map,myValues等是無狀態操作,可應用於KStream和KTable,使用者通常可以自定義函式作為引數傳遞給這些函式,如Predicate的filter,MapValueMapper的map等:
// written in Java 8+, using lambda expressions
KStream<String, GenericRecord> mapped = source1.mapValue(record -> record.get("category"));
無狀態轉換,不需要處理任何狀態。因此在實現上它們不需要流處理器的狀態倉庫。另一方面,有狀態的轉換,則需要狀態倉庫。例如,在連線和聚合操作中,使用視窗狀態來儲存所有目前為止在定義視窗邊界內的所有接收的記錄。然後,操作員可以訪問這些儲存的記錄,並基於它們進行計算。
//writteninJava8+, using lambda expressions
KTable<Windowed<String>, Long> counts = source1.groupByKey().aggregate(() ->0L,//initial value
(aggKey, value, aggregate) ->aggregate +1L,//aggregating value
TimeWindows.of("counts",5000L).advanceBy(1000L),//intervalsinmilliseconds
Serdes.Long()//serdeforaggregated value
); KStream<String, String> joined = source1.leftJoin(source2,(record1, record2) ->record1.get("user") +"-"+ record2.get("region");
);1.6 將流寫回kafka
在處理結束後,開發者可以通過KStream.to和KTable.to將最終的結果流(連續不斷的)寫回Kafka主題。
joined.to("topic4");
如果已經通過上面的to方法寫入到一個主題中,但是如果你還需要繼續讀取和處理這些訊息,可以從輸出主題構建一個新流,Kafka Streams提供了一個便利的方法,through:
// equivalent to
//
// joined.to("topic4");
// materialized = builder.stream("topic4");
KStream materialized = joined.through("topic4");
1.7 應用程式的配置和執行
除了定義的topology,開發者還將需要在執行它之前在StreamsConfig配置他們的應用程式,Kafka Stream配置的完整列表可以在這裡找到。
Kafka Streams中指定配置和生產者、消費者客戶端類似,通常,你建立一個java.util.Properties,設定必要的引數,並通過Properties例項構建一個StreamsConfig例項。
import java.util.Properties;
import org.apache.kafka.streams.StreamsConfig;
Properties settings =newProperties();
// Set a few key parameters
settings.put(StreamsConfig.APPLICATION_ID_CONFIG,"my-first-streams-application");
settings.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,"kafka-broker1:9092");
settings.put(StreamsConfig.ZOOKEEPER_CONNECT_CONFIG,"zookeeper1:2181");
// Any further settings
settings.put(... , ...); // Create an instance of StreamsConfig from the Properties instance
StreamsConfig config =newStreamsConfig(settings);
除了Kafka Streams自己配置引數,你也可以為Kafka內部的消費者和生產者指定引數。根據你應用的需要。類似於Streams設定,你可以通過StreamsConfig設定任何消費者和/或生產者配置。請注意,一些消費者和生產者配置引數使用相同的引數名。例如,用於配置TCP緩衝的send.buffer.bytes或receive.buffer.bytes。用於控制客戶端請求重試的request.timeout.ms和retry.backoff.ms。如果需要為消費者和生產者設定不同的值,可以使用consumer.或producer.作為引數名稱的字首。
Properties settings =newProperties();
// Example ofa"normal"settingforKafka Streams
settings.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,"kafka-broker-01:9092");
// Customize the Kafka consumer settingsstreamsSettings.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG,60000);
// Customizeacommon client settingforboth consumerandproducer
settings.put(CommonClientConfigs.RETRY_BACKOFF_MS_CONFIG,100L);
// Customize differentvaluesforconsumerandproducer
settings.put("consumer."+ ConsumerConfig.RECEIVE_BUFFER_CONFIG,1024*1024);
settings.put("producer."+ ProducerConfig.RECEIVE_BUFFER_CONFIG,64*1024);
// Alternatively, you can usesettings.put(StreamsConfig.consumerPrefix(ConsumerConfig.RECEIVE_BUFFER_CONFIG),1024*1024);
settings.put(StremasConfig.producerConfig(ProducerConfig.RECEIVE_BUFFER_CONFIG),64*1024);
你可以在應用程式程式碼中的任何地方使用Kafka Streams,常見的是在應用程式的main()方法中使用。
首先,先建立一個KafkaStreams例項,其中建構函式的第一個引數用於定義一個topology builder(Streams DSL的KStreamBuilder,或Processor API的TopologyBuilder)。第二個引數是上面提到的StreamsConfig的例項。
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.KStreamBuilder;
import org.apache.kafka.streams.processor.TopologyBuilder;
// Use the builders to define the actual processing topology, e.g. to specify
// from which input topics to read, which stream operations (filter, map, etc.)
// should be called, and so on.
KStreamBuilder builder = ...;// when using the Kafka Streams DSL
//
// OR
//
TopologyBuilder builder = ...;// when using the Processor API
// Use the configuration to tell your application where the Kafka cluster is,
// which serializers/deserializers to use by default, to specify security settings,
// and so on.
StreamsConfig config = ...; KafkaStreams streams =newKafkaStreams(builder, config);
在這點上,內部結果已經初始化,但是處理還沒有開始。你必須通過呼叫start()方法啟動kafka Streams執行緒:
// Start the Kafka Streams instancestreams.start();
捕獲任何意外的異常,設定java.lang.Thread.UncaughtExceptionHandler。每當流執行緒由於意外終止時,將呼叫此處理程式。
streams.setUncaughtExceptionHandler(new Thread.UncaughtExceptionHandler() {
publicuncaughtException(Thread t, throwable e) {
// here you should examine the exception and perform an appropriate action!
});close()方法結束程式。
// Stop the Kafka Streams instancestreams.close();
現在,執行你的應用程式,像其他的Java應用程式一樣(Kafka Sterams沒有任何特殊的要求)。同樣,你也可以打包成jar,通過以下方式執行:
# Start the application in class `com.example.MyStreamsApp`# from the fat jar named `path-to-app-fatjar.jar`.
$ java -cp path-to-app-fatjar.jar com.example.MyStreamsApp
當應用程式例項開始執行時,定義的處理器拓撲將被初始化成1個或多個流任務,可以由例項內的流執行緒並行的執行。如果處理器拓撲定義了狀態倉庫,則這些狀態倉庫在初始化流任務期間(重新)構建。這一點要理解,當如上所訴的啟動你的應用程式時,實際上Kafka Streams認為你釋出了一個例項。現實場景中,更常見的是你的應用程式有多個例項並行執行(如,其他的JVM中或別的機器上)。在這種情況下,Kafka Streams會將任務從現有的例項中分配給剛剛啟動的新例項。有關詳細的資訊,請參閱流分割槽和任務和執行緒模型。