
Flume 原始碼解析:HDFS Sink
Apache Flume 資料流程的最後一部分是 Sink,它會將上游抽取並轉換好的資料輸送到外部儲存中去,如本地檔案、HDFS、ElasticSearch 等。本文將通過分析原始碼來展現 HDFS Sink 的工作流程。
Sink 元件的生命週期
在上一篇文章中, 我們瞭解到 Flume 元件都會實現 LifecycleAware 介面,並由 LifecycleSupervisor 例項管理和監控。不過,Sink 元件並不直接由它管理,而且被包裝在了 SinkRunner 和 SinkProcessor 這兩個類中。Flume 支援三種 Sink 處理器,該處理器會將 Channel 和 Sink 以不同的方式連線起來。這裡我們只討論 DefaultSinkProcessor
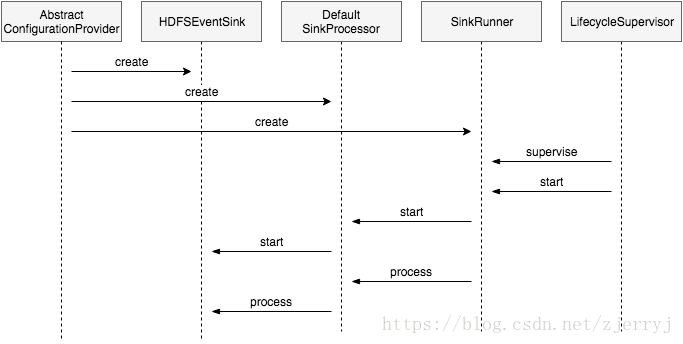
HDFS Sink 模組中的類
HDFS Sink 模組的原始碼在 flume-hdfs-sink 子目錄中,主要由以下幾個類組成:

HDFSEventSink 類實現了生命週期的各個方法,包括 configure、start、process、stop 等。它啟動後會維護一組 BucketWriter 例項,每個例項對應一個 HDFS 輸出檔案路徑,上游的訊息會傳遞給它,並寫入 HDFS。通過不同的 HDFSWriter 實現,它可以將資料寫入文字檔案、壓縮檔案、或是 SequenceFile
配置與啟動
Flume 配置檔案載入時,會例項化各個元件,並呼叫它們的 configure 方法,其中就包括 Sink 元件。在 HDFSEventSink#configure 方法中,程式會讀取配置檔案中以 hdfs. 為開頭的專案,為其提供預設值,並做基本的引數校驗。如,batchSize 必須大於零,fileType 指定為 CompressedStream 時 codeC 引數也必須指定等等。同時,程式還會初始化一個 SinkCounter,用於統計執行過程中的各項指標。
public void configure(Context context) {
filePath = Preconditions. HDFSEventSink#start 方法中會建立兩個執行緒池:callTimeoutPool 執行緒池會在 BucketWriter#callWithTimeout 方法中使用,用來限定 HDFS 遠端呼叫的請求時間,如 FileSystem#create 或 FSDataOutputStream#hflush 都有可能超時;timedRollerPool 則用於對檔案進行滾動,前提是使用者配置了 rollInterval 選項,我們將在下一節詳細說明。
public void start() {
callTimeoutPool = Executors.newFixedThreadPool(threadsPoolSize,
new ThreadFactoryBuilder().setNameFormat(timeoutName).build());
timedRollerPool = Executors.newScheduledThreadPool(rollTimerPoolSize,
new ThreadFactoryBuilder().setNameFormat(rollerName).build());
}
處理資料
process 方法包含了 HDFS Sink 的主要邏輯,也就是從上游的 Channel 中獲取資料,並寫入指定的 HDFS 檔案,流程圖如下:
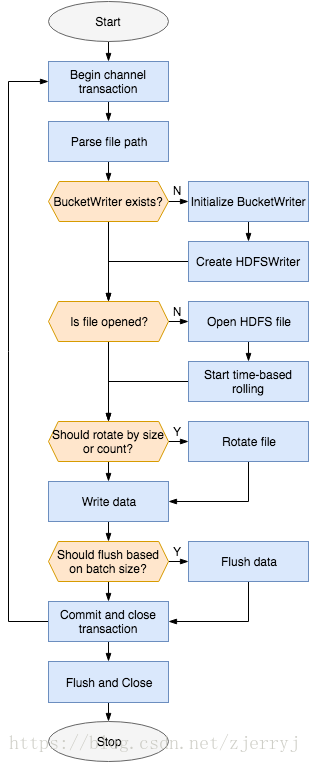
Channel 事務
處理邏輯的外層是一個 Channel 事務,並提供了異常處理。以 Kafka Channel 為例:事務開始時,程式會從 Kafka 中讀取資料,但不會立刻提交變動後的偏移量。只有當這些訊息被成功寫入 HDFS 檔案之後,偏移量才會提交給 Kafka,下次迴圈將從新的偏移量開始消費。
Channel channel = getChannel();
Transaction transaction = channel.getTransaction();
transaction.begin()
try {
event = channel.take();
bucketWriter.append(event);
transaction.commit()
} catch (Throwable th) {
transaction.rollback();
throw new EventDeliveryException(th);
} finally {
transaction.close();
}
查詢或建立 BucketWriter
BucketWriter 例項和 HDFS 檔案一一對應,檔案路徑是通過配置生成的,例如:
a1.sinks.access_log.hdfs.path = /user/flume/access_log/dt=%Y%m%d
a1.sinks.access_log.hdfs.filePrefix = events.%[localhost]
a1.sinks.access_log.hdfs.inUsePrefix = .
a1.sinks.access_log.hdfs.inUseSuffix = .tmp
a1.sinks.access_log.hdfs.rollInterval = 300
a1.sinks.access_log.hdfs.fileType = CompressedStream
a1.sinks.access_log.hdfs.codeC = lzop
以上配置生成的臨時檔案和目標檔案路徑為:
/user/flume/access_log/dt=20180925/.events.hostname1.1537848761307.lzo.tmp
/user/flume/access_log/dt=20180925/events.hostname1.1537848761307.lzo
%{...}:使用訊息中的頭資訊進行替換;%[...]:目前僅支援%[localhost]、%[ip]、以及%[fqdn];%x:日期佔位符,通過頭資訊中的timestamp來生成,或者使用useLocalTimeStamp配置項。
檔案的前後綴則是在 BucketWriter#open 方法中追加的。程式碼中的 counter 是當前檔案的建立時間戳,lzo 則是當前壓縮格式的預設檔案字尾。
String fullFileName = fileName + "." + counter;
fullFileName += fileSuffix;
fullFileName += codeC.getDefaultExtension();
bucketPath = filePath + "/" + inUsePrefix + fullFileName + inUseSuffix;
targetPath = filePath + "/" + fullFileName;
如果指定路徑沒有對應的 BucketWriter 例項,程式會建立一個,並根據 fileType 配置項來生成對應的 HDFSWriter 例項。Flume 支援的三種類型是:HDFSSequenceFile、HDFSDataStream、以及 HDFSCompressedDataStream,寫入 HDFS 的動作是由這些類中的程式碼完成的。
bucketWriter = sfWriters.get(lookupPath);
if (bucketWriter == null) {
hdfsWriter = writerFactory.getWriter(fileType);
bucketWriter = new BucketWriter(hdfsWriter);
sfWriters.put(lookupPath, bucketWriter);
}
寫入資料並重新整理
在寫入資料之前,BucketWriter 首先會檢查檔案是否已經開啟,如未開啟則會命關聯的 HDFSWriter 類開啟新的檔案,以 HDFSCompressedDataStream 為例:
public void open(String filePath, CompressionCodec codec) {
FileSystem hdfs = dstPath.getFileSystem(conf);
fsOut = hdfs.append(dstPath)
compressor = CodedPool.getCompressor(codec, conf);
cmpOut = codec.createOutputStream(fsOut, compressor);
serializer = EventSerializerFactory.getInstance(serializerType, cmpOut);
}
public void append(Event e) throws IO Exception {
serializer.write(event);
}
Flume 預設的 serializerType 配置是 TEXT,即使用 BodyTextEventSerializer 來序列化資料,不做加工,直接寫進輸出流:
public void write(Event e) throws IOException {
out.write(e.getBody());
if (appendNewline) {
out.write('\n');
}
}
當 BucketWriter 需要關閉或重開時會呼叫 HDFSWriter#sync 方法,進而執行序列化例項和輸出流例項上的 flush 方法:
public void sync() throws IOException {
serializer.flush();
compOut.finish();
fsOut.flush();
hflushOrSync(fsOut);
}
從 Hadoop 0.21.0 開始,Syncable#sync 拆分成了 hflush 和 hsync 兩個方法,前者只是將資料從客戶端的快取中刷新出去,後者則會保證資料已被寫入 HDFS 本地磁碟。為了相容新老 API,Flume 會通過 Java 反射機制來確定 hflush 是否存在,不存在則呼叫 sync 方法。上述程式碼中的 flushOrSync 正是做了這樣的判斷。
檔案滾動
HDFS Sink 支援三種滾動方式:按檔案大小、按訊息數量、以及按時間間隔。按大小和按數量的滾動是在 BucketWriter#shouldRotate 方法中判斷的,每次 append 時都會呼叫:
private boolean shouldRotate() {
boolean doRotate = false;
if ((rollCount > 0) && (rollCount <= eventCounter)) {
doRotate = true;
}
if ((rollSize > 0) && (rollSize <= processSize)) {
doRotate = true;
}
return doRotate;
}
按時間滾動則是使用了上文提到的 timedRollerPool 執行緒池,通過啟動一個定時執行緒來實現:
private void open() throws IOException, InterruptedException {
if (rollInterval > 0) {
Callable<Void> action = new Callable<Void>() {
public Void call() throws Exception {
close(true);
}
};
timedRollFuture = timedRollerPool.schedule(action, rollInterval);
}
}
關閉與停止
當 HDFSEventSink#close 被觸發時,它會遍歷所有的 BucketWriter 例項,呼叫它們的 close 方法,進而關閉下屬的 HDFSWriter。這個過程和 flush 類似,只是還會做一些額外操作,如關閉後的 BucketWriter 會將自身從 sfWriters 雜湊表中移除:
public synchronized void close(boolean callCloseCallback) {
writer.close();
timedRollFuture.cancel(false);
onCloseCallback.run(onCloseCallbackPath);
}
onCloseCallback 回撥函式是在 HDFSEventSink 初始化 BucketWriter 時傳入的:
WriterCallback closeCallback = new WriterCallback() {
public void run(String bucketPath) {
synchronized (sfWritersLock) {
sfWriters.remove(bucketPath);
}
}
}
bucketWriter = new BucketWriter(lookPath, closeCallback);
最後,HDFSEventSink 會關閉 callTimeoutPool 和 timedRollerPool 執行緒池,整個元件隨即停止。
ExecutorService[] toShutdown = { callTimeoutPool, timedRollerPool };
for (ExecutorService execService : toShutdown) {
execService.shutdown();
}