
基於Jsoup的網路爬蟲的使用以及網頁分析的基本方法
阿新 • • 發佈:2018-12-13
至於網路爬蟲是什麼我在此就不再多做介紹,本篇部落格主要講解
- Jsoup的實現原理以及使用
- 如何通過對網頁分析實現爬蟲
- 通過一個例項具體演示以上介紹的方法
Jsoup是什麼?
官方對它的解釋是:一個HTML解析器。
它可以從URL、檔案、字串中提取並解析HTML,通過DOM遍歷或CSS選擇器查詢並提取資料,也可以修改HTML各個元素的各種屬性。
Jsoup的幾個重要方法:
- attr(String attributeKey):獲取當前標籤attributeKey屬性中的內容
- attr(String attributeKey,String attributeValue):將當前標籤的attributeKey屬性內容替換成attributeValue。
- child(int index):獲取當前標籤的第index個子標籤
- children():獲取當前標籤的全部子標籤
- getAllElements():獲取當前Dom樹的全部標籤
我們通過抓取CSDN部落格的頁面內容,實際演示一下Jsoup的使用
我們首先建立一個基於Gradle或者Maven的Java專案(當然不用它們直接導jar包也可以),我這裡是用的Gradle。
1、選擇用Gradle建立專案
這裡隨便填
剩下兩步預設就好。
然後我們匯入Jsoup的依賴
Gradle:
compile group: 'org.jsoup', name: 'jsoup', version: '1.11.3'
Maven :
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.3</version>
</dependency>
此工具類可以獲取網頁的全部標籤元素
public class JsoupUtil { /** * 獲取網頁的全部標籤元素 * @param url 網頁的Url * @return 網頁的全部標籤元素 */ public static Elements doConnect(String url){ Connection.Response rs=null; try { rs = Jsoup.connect(url).execute(); } catch (IOException e) { e.printStackTrace(); System.out.println("連線超時"); } return Jsoup.parse(rs.body()).getAllElements(); } }
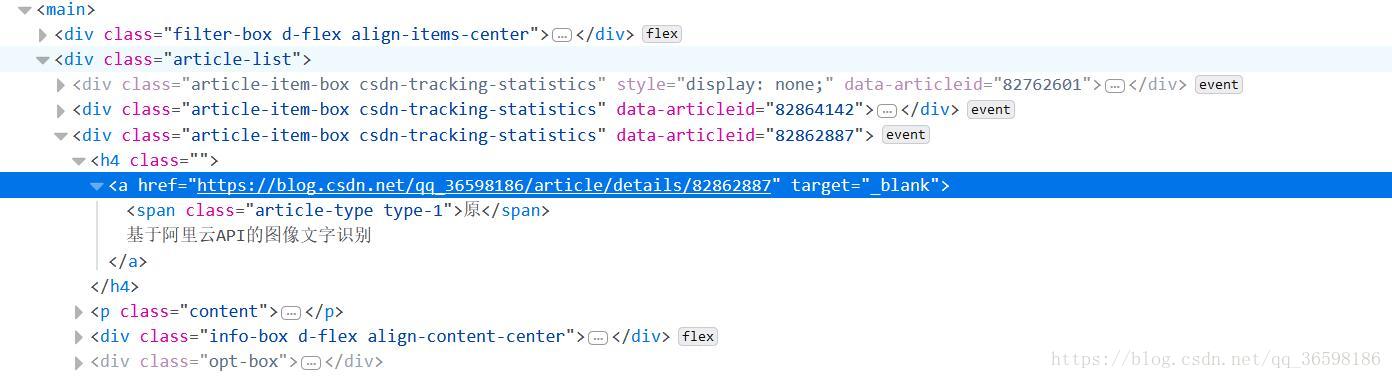
分析網頁得知,
1、所有含有博文連結的標籤class為"article-item-box csdn-tracking-statistics"
2、它的子標籤(<h4>)的子標籤<a>中屬性("href")為指向博文的連結,文章名為其文字內容。
那麼寫出程式碼(注意導包時Element的包不要導錯,它所在的包為org.jsoup.nodes.Element)
public class Main {
List<Blog> blogs=new ArrayList<>(); //儲存獲取到的url及其文章名稱
public void getBlog(){
Elements elements=JsoupUtil.doConnect("https://blog.csdn.net/qq_36598186");
for (Element element:elements){
if (element.attr("class").equals("article-item-box csdn-tracking-statistics")){ //獲取class屬性為article...的標籤
System.out.println(element.child(0).child(0).attr("href")); //輸出當前標籤子標籤的子標籤的href屬性值
System.out.println(element.child(0).child(0).text()); //輸出當前標籤子標籤的子標籤的文字內容
Blog blog=new Blog(element.child(0).child(0).text(),element.child(0).child(0).attr("href"));
blogs.add(blog);
}
}
}
class Blog{
String name; //文章名
String url; //文章url
public Blog(String name, String url) {
this.name = name;
this.url = url;
}
}
public static void main(String args[]){
new Main().getBlog();
}
}
我們如果想獲取每一個文章的內容,該怎麼辦呢?
右鍵文章內容檢視元素。
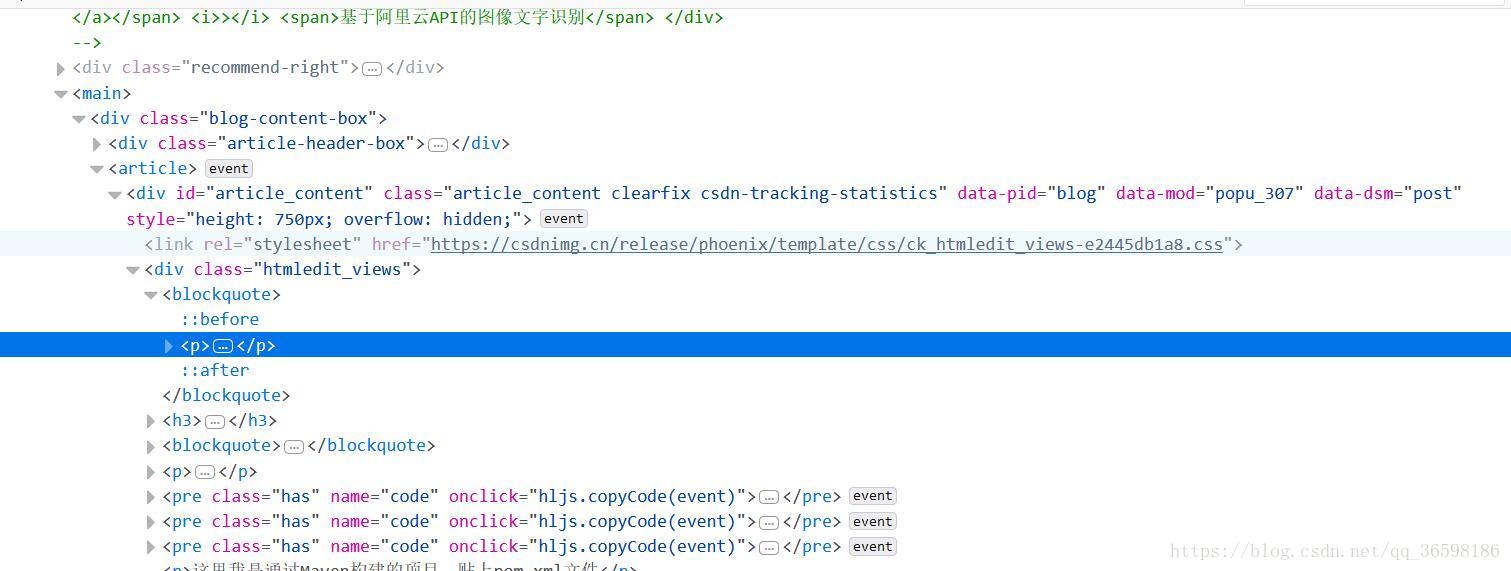
分析得知所有的內容都在class屬性為htmledit_views的標籤內
因為已經成功獲取到了我們所需的url,那麼我們只需在原來程式碼上稍作修改:
public class Main {
List<Blog> blogs=new ArrayList<>();
public void getBlog(){
Elements elements=JsoupUtil.doConnect("https://blog.csdn.net/qq_36598186");
for (Element element:elements){
if (element.attr("class").equals("article-item-box csdn-tracking-statistics")){
System.out.println(element.child(0).child(0).attr("href"));
System.out.println(element.child(0).child(0).text());
Blog blog=new Blog(element.child(0).child(0).text(),element.child(0).child(0).attr("href"));
blogs.add(blog);
}
}
blogs.remove(0); //這裡是因為發現一段被原網頁註釋掉的程式碼被解析成為了指向內容的url
for (Blog blog : blogs) {
Elements elements1=JsoupUtil.doConnect(blog.url);
for (Element element:elements1){
if (element.attr("class").equals("htmledit_views")){
System.out.println(element.text()); //獲取所有class屬性為htmledit_views的文字
}
}
}
}
class Blog{
String name;
String url;
public Blog(String name, String url) {
this.name = name;
this.url = url;
}
}
public static void main(String args[]){
new Main().getBlog();
}
}
大功告成!