
Python環境下使用OpenStreetMap下載的.osm資料
引言
最近在專案中需要使用地理空間資訊來輔助進行聚類工作,除了常規的經緯度資訊之外,還需要更重要的地理層級資訊,如對於“都江堰”來進行查詢,期望獲得“都江堰,成都,中國”這樣一個完整的地理層級關係。因此,在這兩天筆者便研究了一下如何獲得這樣的資訊。
使用geopy包來實現
工程中用的是Python2,而在python中也確實有現有的包可以實現這樣的功能,比如一個常用的包是geopy。
其使用方法如下:
# -*- coding: utf-8 -*-
from geopy.geocoders import Nominatim
geolocator = Nominatim( 程式輸出:
都江堰市, 都江堰市 / Dujiangyan, 成都市 / Chengdu, 四川省, 中國
可以看到,確實輸出了一串地理層級資訊,而且其中也確實包含了我們想要的正確的結果,但是結構非常的不標準,這樣的結構在之後的操作中,想要處理成方便程式使用的形式是有些困難的,因為有很多地名會輸出各種意想不到的結果的形式。
還有一點問題是,這個包是通過線上查詢來返回結果的,而每次返回所需的時間大約是數秒級別的,如果是單次的查詢,那麼這個時間是完全可以接受的,而若大批量的查詢,特別是需要實時效果的話,這種方法就難以獲得理想的效果了。
而在嘗試過幾個包之後,發現這個包的效果其實已經相對較好了。在以前曾經用過谷歌的地理資訊查詢服務,但是谷歌提供的介面目前開始收費了,所以筆者又把目光放向了開源的OpenStreetMap。
下載OpenStreetMap的地圖包
OpenStreetMap是一款開源的,由網路大眾共同打造的地圖服務,而且是知名度最高、應用最為廣泛的開源地圖之一,在前一部分所介紹的geopy包裡的一部分返回資料就是通過這個開源地圖得到的。而且,OpenStreetMap由於是開源地圖,是提供地圖的下載的。
要下載OSM上的地圖,我們可以在這個網址直接下載:
http://download.geofabrik.de/index.html
進入頁面之後,可以看到按大洲下載地圖的連結,也可以從左邊某個大洲點進去,下載某個國家的地圖,如我們進入“Asia”,然後下載中國的地圖。
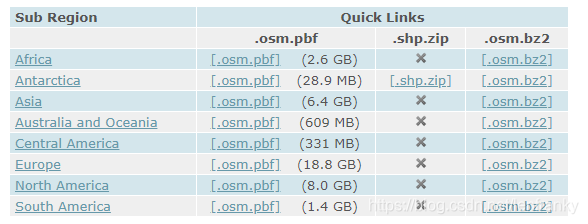

可以看到,在下載中,有三個可選項,分別是.osm.pbf、.shp.zip、.osm.bz3,在這裡,我們需要的是.osm檔案中的資訊,而第一項和第三項都是.osm檔案的壓縮形式,其中,.bz2是可以直接解壓縮的,但是大小是.pbf的1.5到2倍左右。需要下載哪一項,大家可以自己斟酌。
如果下載的是.pbf檔案,是需要一個專門的工具來將.pbf檔案轉換成.osm檔案的,這個工具可以在這裡下載:https://wiki.openstreetmap.org/wiki/Osmconvert
pbf檔案轉換
工具本身非常小,下載下來之後,放入儲存下載資料的資料夾(即儲存.pbf檔案的資料夾,推薦所在分割槽留出較多空間,因為可能佔用較多空間),然後開啟之後是一個命令列操作的介面。這時,可以用如下的命令直接進行轉換:
osmconvert syria-latest.osm.pbf --out-osm -o=syria-latest.osm_01.osm
當然,工具本身也比較方便,無需記憶命令,先按照提示鍵入a,然後程式會詢問要處理哪個檔案,這時鍵入檔案的全名,之後程式會詢問需要對該檔案進行什麼操作,這時鍵入1,選擇要對檔案格式進行轉換,最後在選擇輸出格式時,選擇1,選擇按照.osm格式輸出,便可以得到我們需要的.osm格式的檔案了。
.osm檔案中的資料
.osm檔案是OpenStreetMap專門用來封裝自家資料的一種格式,裡面可以按照XML格式的檔案來進行讀取。
關於osm內部的結構,我參考了這篇文章:https://blog.csdn.net/scy411082514/article/details/7484497/
OpenStreetMap的元素主要包括三種:點(Nodes)、路(Ways)和關係(Relations),這三種原始構成了整個地圖畫面。其中,Nodes定義了空間中點的位置;Ways定義了線或區域;Relations(可選的)定義了元素間的關係。
而我們所需要的地理層級資訊便在node欄位中,其中也可獲取到經緯度等資訊,如“都江堰”欄位內如下:
{u'k': u'gns:ADM1', u'v': u'32'}
{u'k': u'gns:DSG', u'v': u'ADM3'}
{u'k': u'gns:UFI', u'v': u'-1907309'}
{u'k': u'gns:UNI', u'v': u'10071801'}
{u'k': u'is_in', u'v': u'Chengdu, Sichuan, China'}
{u'k': u'is_in:continent', u'v': u'Asia'}
{u'k': u'is_in:country', u'v': u'China'}
{u'k': u'is_in:country_code', u'v': u'CN'}
{u'k': u'name', u'v': u'\u90fd\u6c5f\u5830\u5e02'}
{u'k': u'name:de', u'v': u'Dujiangyan'}
{u'k': u'name:en', u'v': u'Dujiangyan'}
{u'k': u'name:fr', u'v': u'D\u016bji\u0101ngy\xe0n'}
{u'k': u'name:ja', u'v': u'\u90fd\u6c5f\u5830\u5e02'}
{u'k': u'name:ru', u'v': u'\u0414\u0443\u0446\u0437\u044f\u043d\u044a\u044f\u043d\u044c'}
{u'k': u'name:vi', u'v': u'\u0110\xf4 Giang Y\u1ec3n'}
{u'k': u'name:zh', u'v': u'\u90fd\u6c5f\u5830\u5e02'}
{u'k': u'name:zh_pinyin', u'v': u'D\u016bji\u0101ngy\xe0n Shi'}
{u'k': u'place', u'v': u'city'}
{u'k': u'wikidata', u'v': u'Q1023900'}
{u'k': u'wikipedia', u'v': u'en:Dujiangyan City'}
而其中的is_in欄位,便是我們需要的地理層級資訊了,如這一條中的{u'k': u'is_in', u'v': u'Chengdu, Sichuan, China'},便說明都江堰屬於“中國,四川,成都,都江堰”,將其解析出來便可直接使用。
將.osm檔案中的資料轉存到json中
由於.osm中的資料是按照xml的形式儲存的,若每次都從中讀取資料的話,對於單個就達幾個G甚至數十上百G的檔案,若按照樹的方式來進行解析,不光時間上難以接受,首先面臨的就是記憶體不足的問題。
對於.osm檔案已經有專門的資料庫可以來儲存其中的資訊,而在我們的工程中使用的是MongoDb資料庫,為了便於以後的使用,和往我們的資料庫裡匯入資料,這裡我準備先將.osm檔案轉換到.json檔案中。
需要注意的是,在轉換的過程中,我們是不能將整個檔案完整地解析出來的,因為會佔用極大的記憶體,在這裡,我們可以採用遞迴的方法來進行處理。
程式碼如下:
# -*- coding: utf-8 -*-
import json
from lxml import etree
import xmltodict
def iter_element(file_parsed, file_length, file_write):
current_line = 0
try:
for event, element in file_parsed:
current_line += 1
print current_line/float(file_length)
elem_data = etree.tostring(element)
elem_dict = xmltodict.parse(elem_data, attr_prefix="", cdata_key="")
if (element.tag == "node"):
elem_jsonStr = json.dumps(elem_dict["node"])
file_write.write(elem_jsonStr + "\n")
# 每次讀取之後進行一次清空
element.clear()
while element.getprevious() is not None:
del element.getparent()[0]
except:
pass
if __name__ == '__main__':
osmfile = r'D:\data\china-latest.osm'
file_length = -1
for file_length, line in enumerate(open(osmfile, 'rU')):
pass
file_length += 1
print "length of the file:\t" + str(file_length)
file_node = open(osmfile+"_node.json","w+")
file_parsed = etree.iterparse(osmfile, tag=["node"])
iter_element(file_parsed, file_length, file_node)
file_node.close()
這樣,就可以將其中的node裡的資訊儲存下來了,之後,我們可以將其中包含地理層級資訊的部分篩選出來,經過觀察,可以發現裡面有大量只有一到兩行的資料,其中資料是後面不會使用的,這裡,我們可以將其篩出,程式碼如下:
import json
count = 0
file_write = open(r'D:\data\test.txt', mode = 'wb')
with open(r'D:\data\china-latest.osm_node.json', mode='rb') as file_read:
for line in file_read:
line = line.replace('\n', '')
info = json.loads(line)
if 'tag' in info and type(info['tag']) is list and len(info['tag']) > 2:
for item in info['tag']:
print item
file_write.write(str(item) + '\n')
print "-" * 60
file_write.write("-" * 100 + '\n')
count += 1
在上面這段程式碼中,僅僅是讀取之前所得到的.json檔案並將大於兩行的資料打印出來並儲存到一個txt檔案中,後面可以改為其它操作。