
java集合(5)—hashmap
越努力越幸運!
hashmap
HashMap:它根據鍵的hashCode值儲存資料,大多數情況下可以直接定位到它的值,因而具有很快的訪問速度,但遍歷順序卻是不確定的。 HashMap最多隻允許一條記錄的鍵為null,允許多條記錄的值為null。HashMap非執行緒安全,即任一時刻可以有多個執行緒同時寫HashMap,可能會導致資料的不一致。如果需要滿足執行緒安全,可以用 Collections的synchronizedMap方法使HashMap具有執行緒安全的能力,或者使用ConcurrentHashMap。
hashmap的常見面試題
1.面試官:HashMap的底層實現(如何解決hash衝突 ,負載因子)
答:
初始容量是16,負載因子是0.75 超過16*0.75後就會擴容,變為32,重新hash
JDK1.8之前
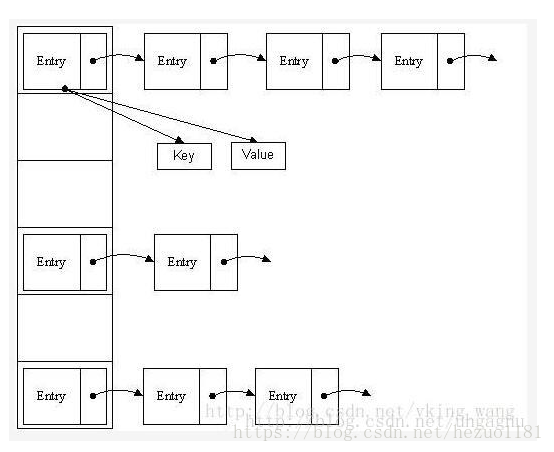
JDK1.8 之前 HashMap 由 陣列+連結串列 組成的(“連結串列雜湊” 即陣列和連結串列的結合體),陣列是 HashMap 的主體,連結串列則是主要為了解決雜湊衝突而存在的(HashMap 採用 “拉鍊法也就是鏈地址法” 解決衝突),如果定位到的陣列位置不含連結串列(當前 entry 的 next 指向 null ),那麼對於查詢,新增等操作很快,僅需一次定址即可;如果定位到的陣列包含連結串列,對於新增操作,其時間複雜度依然為 O(1),因為最新的 Entry 會插入連結串列頭部,急需要簡單改變引用鏈即可,而對於查詢操作來講,此時就需要遍歷連結串列,然後通過 key 物件的 equals 方法逐一比對查詢.
所謂 “拉鍊法” 就是將連結串列和陣列相結合。也就是說建立一個連結串列陣列,陣列中每一格就是一個連結串列。若遇到雜湊衝突,則將衝突的值加到連結串列中即可。
JDK1.8之後
相比於之前的版本, JDK1.8之後在解決雜湊衝突時有了較大的變化,當連結串列長度大於閾值(預設為8)時,將連結串列轉化為紅黑樹,以減少搜尋時間。

- · HashMap有一個叫做Entry的內部類,它用來儲存key-value對。
- · 上面的Entry物件是儲存在一個叫做table的Entry陣列中。
- · table的索引在邏輯上叫做“桶”(bucket),它儲存了連結串列的第一個元素。
- · key的hashcode()方法用來找到Entry物件所在的桶。
- · 如果兩個key有相同的hash值,他們會被放在table陣列的同一個桶裡面。
- · key的equals()方法用來確保key的唯一性。
- · value物件的equals()和hashcode()方法根本一點用也沒有。
簡單地說,HashMap 在底層將 key-value 當成一個整體進行處理,這個整體就是一個 Entry 物件。HashMap 底層採用一個 Entry[] 陣列來儲存所有的 key-value 對,當需要儲存一個 Entry 物件時,會根據hash演算法來決定其在陣列中的儲存位置,在根據equals方法決定其在該陣列位置上的連結串列中的儲存位置;當需要取出一個Entry時, 也會根據hash演算法找到其在陣列中的儲存位置,再根據equals方法從該位置上的連結串列中取出該Entry。
2.面試官:hashmap1.8為什麼要採用紅黑樹而不是B樹或者B+樹呢?
紅黑樹多用在內部排序,即全放在記憶體中的,STL的map和set的內部實現就是紅黑樹。
B+樹多用於外存上時,B+也被成為一個磁碟友好的資料結構。
3.面試官:為什麼hashmap1.8不是一開始就用紅黑樹,而是要超過8以後才是使用紅黑樹呢?
答:因為紅黑樹的平均查詢長度是log(n),長度為8的時候,平均查詢長度為3。。如果繼續使用連結串列,平均查詢長度為8/2=4。這才有轉換為樹的必要。。連結串列長度如果是6以內,6/2=3,速度也很快的。轉化為樹還有生成樹的時間,並不明智。
長度為8,連結串列轉樹,長度為6,樹轉連結串列。。中間有個差值,還可以防止連結串列和樹頻繁轉換。假設8以上轉為樹,8以下轉為連結串列,那麼一個hashmap如果不停的插入刪除,連結串列長度在8左右徘徊,就會不停的樹轉連結串列,連結串列轉樹,效率很
4.面試官:hashmap的get操作
答:
當你傳遞一個key從hashmap總獲取value的時候:
對key進行null檢查。如果key是null,table[0]這個位置的元素將被返回。
key的hashcode()方法被呼叫,然後計算hash值。
indexFor(hash,table.length)用來計算要獲取的Entry物件在table陣列中的精確的位置,使用剛才計算的hash值。
在獲取了table陣列的索引之後,會迭代連結串列,呼叫equals()方法檢查key的相等性,如果equals()方法返回true,get方法返回Entry物件的value,否則,返回null。
5.面試官:hashmap的put操作
首先對key做null檢查。如果key是null,會被儲存到table[0],因為null的hash值總是0。
key的hashcode()方法會被呼叫,然後計算hash值。hash值用來找到儲存Entry物件的陣列的索引。有時候hash函式可能寫的很不好,所以JDK的設計者添加了另一個叫做hash()的方法,它接收剛才計算的hash值作為引數。
indexFor(hash,table.length)用來計算在table陣列中儲存Entry物件的精確的索引。
在我們的例子中已經看到,如果兩個key有相同的hash值(也叫衝突),他們會以連結串列的形式來儲存。所以,這裡我們就迭代連結串列。
· 如果在剛才計算出來的索引位置沒有元素,直接把Entry物件放在那個索引上。
· 如果索引上有元素,然後會進行迭代,一直到Entry->next是null。當前的Entry物件變成連結串列的下一個節點。
· 如果我們再次放入同樣的key會怎樣呢?邏輯上,它應該替換老的value。事實上,它確實是這麼做的。在迭代的過程中,會呼叫equals()方法來檢查key的相等性(key.equals(k)),如果這個方法返回true,它就會用當前Entry的value來替換之前的value。
答:
①.判斷鍵值對陣列table[i]是否為空或為null,否則執行resize()進行擴容;
②.根據鍵值key計算hash值得到插入的陣列索引i,如果table[i]==null,直接新建節點新增,轉向⑥,如果table[i]不為空,轉向③;
③.判斷table[i]的首個元素是否和key一樣,如果相同直接覆蓋value,否則轉向④,這裡的相同指的是hashCode以及equals;
④.判斷table[i] 是否為treeNode,即table[i] 是否是紅黑樹,如果是紅黑樹,則直接在樹中插入鍵值對,否則轉向⑤;
⑤.遍歷table[i],判斷連結串列長度是否大於8,大於8的話把連結串列轉換為紅黑樹,在紅黑樹中執行插入操作,否則進行連結串列的插入操作;遍歷過程中若發現key已經存在直接覆蓋value即可;
⑥.插入成功後,判斷實際存在的鍵值對數量size是否超多了最大容量threshold,如果超過,進行擴容。
6.面試官:平時在使用HashMap時一般使用什麼型別的元素作為Key?
面試者通常會回答,使用String或者Integer這樣的類。這個時候可以繼續追問為什麼使用String、Integer呢?這些類有什麼特點?如果面試者有很好的思考,可以回答出這些類是Immutable的,並且這些類已經很規範的覆寫了hashCode()以及equals()方法。作為不可變類天生是執行緒安全的,而且可以很好的優化比如可以快取hash值,避免重複計算等等,那麼基本上這道題算是過關了。
7.面試官:如果讓你實現一個自定義的class作為HashMap的key該如何實現?
參考
8.面試官:hashcode equal
9.面試官:HashMap是執行緒安全的嗎? 如果多個執行緒操作同一個HashMap物件會產生哪些非正常現象?
10.面試官:HashMap中bucket的大小為什麼是2的冪?
為了能讓 HashMap 存取高效,儘量較少碰撞,也就是要儘量把資料分配均勻,每個連結串列/紅黑樹長度大致相同。這個實現就是把資料存到哪個連結串列/紅黑樹中的演算法。
“取餘(%)操作中如果除數是2的冪次則等價於與其除數減一的與(&)操作(也就是說 hash%length==hash&(length-1)的前提是 length 是2的 n 次方;)。” 並且 採用二進位制位操作 &,相對於%能夠提高運算效率。
11.面試官:為什麼HashMap中負載因子子是0.75?
Node[] table的初始化長度length(預設值是16),Load factor為負載因子(預設值是0.75),threshold是HashMap所能容納的最大資料量的Node(鍵值對)個數。threshold = length * Load factor。也就是說,在陣列定義好長度之後,負載因子越大,所能容納的鍵值對個數越多。
結合負載因子的定義公式可知,threshold就是在此Load factor和length(陣列長度)對應下允許的最大元素數目,超過這個數目就重新resize(擴容),擴容後的HashMap容量是之前容量的兩倍。預設的負載因子0.75是對空間和時間效率的一個平衡選擇,建議大家不要修改,除非在時間和空間比較特殊的情況下,如果記憶體空間很多而又對時間效率要求很高,可以降低負載因子Load factor的值;相反,如果記憶體空間緊張而對時間效率要求不高,可以增加負載因子loadFactor的值,這個值可以大於1。
12.面試官:HashMap 和 Hashtable 的區別
答:
- 執行緒是否安全: HashMap 是非執行緒安全的,HashTable 是執行緒安全的;HashTable 內部的方法基本都經過
synchronized修飾。(如果你要保證執行緒安全的話就使用 ConcurrentHashMap 吧!);- 效率: 因為執行緒安全的問題,HashMap 要比 HashTable 效率高一點。另外,HashTable 基本被淘汰,不要在程式碼中使用它;
- 對Null key 和Null value的支援: HashMap 中,null 可以作為鍵,這樣的鍵只有一個,可以有一個或多個鍵所對應的值為 null。。但是在 HashTable 中 put 進的鍵值只要有一個 null,直接丟擲 NullPointerException。
- 初始容量大小和每次擴充容量大小的不同 : ①建立時如果不指定容量初始值,Hashtable 預設的初始大小為11,之後每次擴充,容量變為原來的2n+1。HashMap 預設的初始化大小為16。之後每次擴充,容量變為原來的2倍。②建立時如果給定了容量初始值,那麼 Hashtable 會直接使用你給定的大小,而 HashMap 會將其擴充為2的冪次方大小。也就是說 HashMap 總是使用2的冪作為雜湊表的大小。
- 底層資料結構: JDK1.8 以後的 HashMap 在解決雜湊衝突時有了較大的變化,當連結串列長度大於閾值(預設為8)時,將連結串列轉化為紅黑樹,以減少搜尋時間。Hashtable 沒有這樣的機制。