
高效的資料壓縮編碼方式 Protobuf
一. protocol buffers 是什麼?
Protocol buffers 是一種語言中立,平臺無關,可擴充套件的序列化資料的格式,可用於通訊協議,資料儲存等。
Protocol buffers 在序列化資料方面,它是靈活的,高效的。相比於 XML 來說,Protocol buffers 更加小巧,更加快速,更加簡單。一旦定義了要處理的資料的資料結構之後,就可以利用 Protocol buffers 的程式碼生成工具生成相關的程式碼。甚至可以在無需重新部署程式的情況下更新資料結構。只需使用 Protobuf 對資料結構進行一次描述,即可利用各種不同語言或從各種不同資料流中對你的結構化資料輕鬆讀寫。
Protocol buffers 很適合做資料儲存或 RPC 資料交換格式。可用於通訊協議、資料儲存等領域的語言無關、平臺無關、可擴充套件的序列化結構資料格式。
二. 為什麼要發明 protocol buffers ?

大家可能會覺得 Google 發明 protocol buffers 是為了解決序列化速度的,其實真實的原因並不是這樣的。
protocol buffers 最先開始是 google 用來解決索引伺服器 request/response 協議的。沒有 protocol buffers 之前,google 已經存在了一種 request/response 格式,用於手動處理 request/response 的編組和反編組。它也能支援多版本協議,不過程式碼比較醜陋:
if (version == 3) { ... } else if (version > 4) { if (version == 5) { ... } ... } 如果非常明確的格式化協議,會使新協議變得非常複雜。因為開發人員必須確保請求發起者與處理請求的實際伺服器之間的所有伺服器都能理解新協議,然後才能切換開關以開始使用新協議。
這也就是每個伺服器開發人員都遇到過的低版本相容、新舊協議相容相關的問題。
protocol buffers 為了解決這些問題,於是就誕生了。protocol buffers 被寄予一下 2 個特點:
- 可以很容易地引入新的欄位,並且不需要檢查資料的中間伺服器可以簡單地解析並傳遞資料,而無需瞭解所有欄位。
- 資料格式更加具有自我描述性,可以用各種語言來處理(C++, Java 等各種語言)
這個版本的 protocol buffers 仍需要自己手寫解析的程式碼。
不過隨著系統慢慢發展,演進,protocol buffers 目前具有了更多的特性:
- 自動生成的序列化和反序列化程式碼避免了手動解析的需要。(官方提供自動生成程式碼工具,各個語言平臺的基本都有)
- 除了用於 RPC(遠端過程呼叫)請求之外,人們開始將 protocol buffers 用作持久儲存資料的便捷自描述格式(例如,在Bigtable中)。
- 伺服器的 RPC 介面可以先宣告為協議的一部分,然後用 protocol compiler 生成基類,使用者可以使用伺服器介面的實際實現來覆蓋它們。
protocol buffers 現在是 Google 用於資料的通用語言。在撰寫本文時,谷歌程式碼樹中定義了 48162 種不同的訊息型別,包括 12183 個 .proto 檔案。它們既用於 RPC 系統,也用於在各種儲存系統中持久儲存資料。
小結:
protocol buffers 誕生之初是為了解決伺服器端新舊協議(高低版本)相容性問題,名字也很體貼,“協議緩衝區”。只不過後期慢慢發展成用於傳輸資料。
Protocol Buffers 命名由來:
Why the name "Protocol Buffers"?
The name originates from the early days of the format, before we had the protocol buffer compiler to generate classes for us. At the time, there was a class called ProtocolBuffer which actually acted as a buffer for an individual method. Users would add tag/value pairs to this buffer individually by calling methods like AddValue(tag, value). The raw bytes were stored in a buffer which could then be written out once the message had been constructed.Since that time, the "buffers" part of the name has lost its meaning, but it is still the name we use. Today, people usually use the term "protocol message" to refer to a message in an abstract sense, "protocol buffer" to refer to a serialized copy of a message, and "protocol message object" to refer to an in-memory object representing the parsed message.
這個名字起源於 format 早期,在我們有 protocol buffer 編譯器為我們生成類之前。當時,有一個名為 ProtocolBuffer 的類,它實際上充當了單個方法的緩衝區。使用者可以通過呼叫像 AddValue(tag,value) 這樣的方法分別將標籤/值對新增到此緩衝區。原始位元組儲存在一個緩衝區中,一旦構建訊息就可以將其寫出。
從那時起,名為“緩衝”的部分已經失去了意義,但它仍然是我們使用的名稱。今天,人們通常使用術語“protocol message”來指代抽象意義上的訊息,“protocol buffer”指的是訊息的序列化副本,而“protocol message object”指的是代表記憶體中物件解析的訊息。
三. proto3 定義 message

目前 protocol buffers 最新版本是 proto3,與老的版本 proto2 還是有些區別的。這兩個版本的 API 不完全相容。
proto2 和 proto3 的名字看起來有點撲朔迷離,那是因為當我們最初開源的 protocol buffers 時,它實際上是 Google 的第二個版本了,所以被稱為 proto2,這也是我們的開源版本號從 v2 開始的原因。初始版名為 proto1,從 2001 年初開始在谷歌開發的。
在 proto 中,所有結構化的資料都被稱為 message。
message helloworld
{
required int32 id = 1; // ID
required string str = 2; // str
optional int32 opt = 3; //optional field
}
上面這幾行語句,定義了一個訊息 helloworld,該訊息有三個成員,型別為 int32 的 id,另一個為型別為 string 的成員 str。opt 是一個可選的成員,即訊息中可以不包含該成員。
接下來說明一些 proto3 中需要注意的地方。
syntax = "proto3";
message SearchRequest {
string query = 1;
int32 page_number = 2;
int32 result_per_page = 3;
}
如果開頭第一行不宣告 syntax = "proto3";,則預設使用 proto2 進行解析。
1. 分配欄位編號
每個訊息定義中的每個欄位都有唯一的編號。這些欄位編號用於標識訊息二進位制格式中的欄位,並且在使用訊息型別後不應更改。請注意,範圍 1 到 15 中的欄位編號需要一個位元組進行編碼,包括欄位編號和欄位型別(具體原因見 Protocol Buffer 編碼原理 這一章節)。範圍 16 至 2047 中的欄位編號需要兩個位元組。所以你應該保留數字 1 到 15 作為非常頻繁出現的訊息元素。請記住為將來可能新增的頻繁出現的元素留出一些空間。
可以指定的最小欄位編號為1,最大欄位編號為2^29^-1 或 536,870,911。也不能使用數字 19000 到 19999(FieldDescriptor :: kFirstReservedNumber 到 FieldDescriptor :: kLastReservedNumber),因為它們是為 Protocol Buffers實現保留的。
如果在 .proto 中使用這些保留數字中的一個,Protocol Buffers 編譯的時候會報錯。
同樣,您不能使用任何以前 Protocol Buffers 保留的一些欄位號碼。保留欄位是什麼,下一節詳細說明。
2. 保留欄位
如果您通過完全刪除某個欄位或將其註釋掉來更新訊息型別,那麼未來的使用者可以在對該型別進行自己的更新時重新使用該欄位號。如果稍後載入到了的舊版本 .proto 檔案,則會導致伺服器出現嚴重問題,例如資料混亂,隱私錯誤等等。確保這種情況不會發生的一種方法是指定刪除欄位的欄位編號(或名稱,這也可能會導致 JSON 序列化問題)為 reserved。如果將來的任何使用者試圖使用這些欄位識別符號,Protocol Buffers 編譯器將會報錯。
message Foo {
reserved 2, 15, 9 to 11;
reserved "foo", "bar";
}
注意,不能在同一個 reserved 語句中混合欄位名稱和欄位編號。如有需要需要像上面這個例子這樣寫。
3. 預設欄位規則
- 欄位名不能重複,必須唯一。
- repeated 欄位:可以在一個 message 中重複任何數字多次(包括 0 ),不過這些重複值的順序被保留。
在 proto3 中,純數字型別的 repeated 欄位編碼時候預設採用 packed 編碼(具體原因見 Protocol Buffer 編碼原理 這一章節)
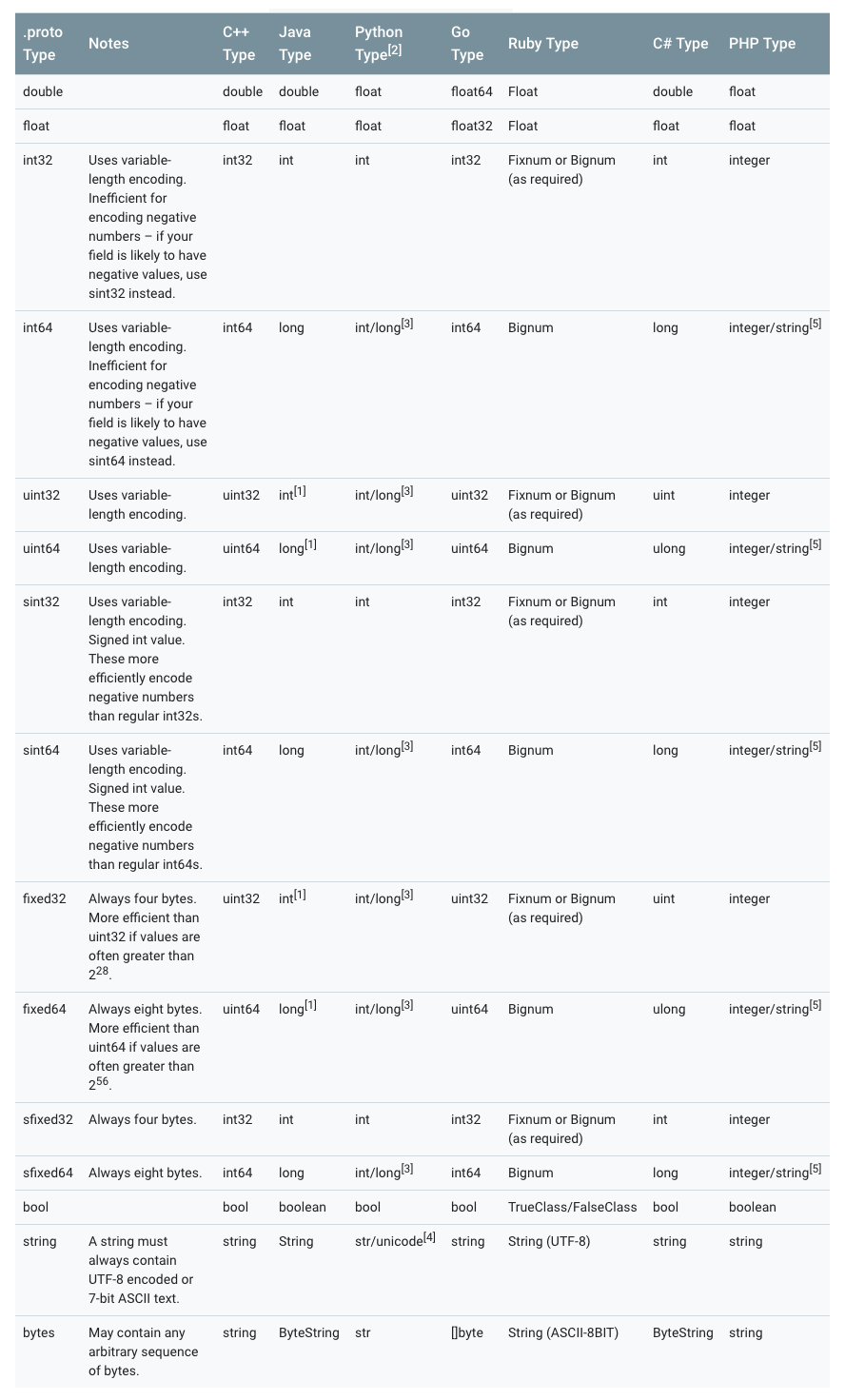
4. 各個語言標量型別對應關係
5. 列舉
在 message 中可以嵌入列舉型別。
message SearchRequest {
string query = 1;
int32 page_number = 2;
int32 result_per_page = 3;
enum Corpus {
UNIVERSAL = 0;
WEB = 1;
IMAGES = 2;
LOCAL = 3;
NEWS = 4;
PRODUCTS = 5;
VIDEO = 6;
}
Corpus corpus = 4;
}
列舉型別需要注意的是,一定要有 0 值。
- 列舉為 0 的是作為零值,當不賦值的時候,就會是零值。
- 為了和 proto2 相容。在 proto2 中,零值必須是第一個值。
另外在反序列化的過程中,無法被識別的列舉值,將會被保留在 messaage 中。因為訊息反序列化時如何表示是依賴於語言的。在支援指定符號範圍之外的值的開放列舉型別的語言中,例如 C++ 和 Go,未知的列舉值只是儲存為其基礎整數表示。在諸如 Java 之類的封閉列舉型別的語言中,列舉值會被用來標識未識別的值,並且特殊的訪問器可以訪問到底層整數。
在其他情況下,如果訊息被序列化,則無法識別的值仍將與訊息一起序列化。
5. 列舉中的保留值
如果您通過完全刪除列舉條目或將其註釋掉來更新列舉型別,未來的使用者可以在對該型別進行自己的更新時重新使用數值。如果稍後載入到了的舊版本 .proto 檔案,則會導致伺服器出現嚴重問題,例如資料混亂,隱私錯誤等等。確保這種情況不會發生的一種方法是指定已刪除條目的數字值(或名稱,這也可能會導致JSON序列化問題)為 reserved。如果將來的任何使用者試圖使用這些欄位識別符號,Protocol Buffers 編譯器將會報錯。您可以使用 max 關鍵字指定您的保留數值範圍上升到最大可能值。
enum Foo {
reserved 2, 15, 9 to 11, 40 to max;
reserved "FOO", "BAR";
}
注意,不能在同一個 reserved 語句中混合欄位名稱和欄位編號。如有需要需要像上面這個例子這樣寫。
6. 允許巢狀
Protocol Buffers 定義 message 允許巢狀組合成更加複雜的訊息。
message SearchResponse {
repeated Result results = 1;
}
message Result {
string url = 1;
string title = 2;
repeated string snippets = 3;
}
上面的例子中,SearchResponse 中巢狀使用了 Result 。
更多的例子:
message SearchResponse {
message Result {
string url = 1;
string title = 2;
repeated string snippets = 3;
}
repeated Result results = 1;
}
message SomeOtherMessage {
SearchResponse.Result result = 1;
}
message Outer { // Level 0
message MiddleAA { // Level 1
message Inner { // Level 2
int64 ival = 1;
bool booly = 2;
}
}
message MiddleBB { // Level 1
message Inner { // Level 2
int32 ival = 1;
bool booly = 2;
}
}
}
7. 列舉不相容性
可以匯入 proto2 訊息型別並在 proto3 訊息中使用它們,反之亦然。然而,proto2 列舉不能直接用在 proto3 語法中(但是如果匯入的proto2訊息使用它們,這是可以的)。
8. 更新 message
如果後面發現之前定義 message 需要增加欄位了,這個時候就體現出 Protocol Buffer 的優勢了,不需要改動之前的程式碼。不過需要滿足以下 10 條規則:
- 不要改動原有欄位的資料結構。
- 如果您新增新欄位,則任何由程式碼使用“舊”訊息格式序列化的訊息仍然可以通過新生成的程式碼進行分析。您應該記住這些元素的預設值,以便新程式碼可以正確地與舊程式碼生成的訊息進行互動。同樣,由新程式碼建立的訊息可以由舊程式碼解析:舊的二進位制檔案在解析時會簡單地忽略新欄位。(具體原因見 未知欄位 這一章節)
- 只要欄位號在更新的訊息型別中不再使用,欄位可以被刪除。您可能需要重新命名該欄位,可能會新增字首“OBSOLETE_”,或者標記成保留欄位號
reserved,以便將來的.proto使用者不會意外重複使用該號碼。 - int32,uint32,int64,uint64 和 bool 全都相容。這意味著您可以將欄位從這些型別之一更改為另一個欄位而不破壞向前或向後相容性。如果一個數字從不適合相應型別的線路中解析出來,則會得到與在 C++ 中將該數字轉換為該型別相同的效果(例如,如果將 64 位數字讀為 int32,它將被截斷為 32 位)。
- sint32 和 sint64 相互相容,但與其他整數型別不相容。
- 只要位元組是有效的UTF-8,string 和 bytes 是相容的。
- 嵌入式 message 與 bytes 相容,如果 bytes 包含 message 的 encoded version。
- fixed32與sfixed32相容,而fixed64與sfixed64相容。
- enum 就陣列而言,是可以與 int32,uint32,int64 和 uint64 相容(請注意,如果它們不適合,值將被截斷)。但是請注意,當訊息反序列化時,客戶端程式碼可能會以不同的方式對待它們:例如,未識別的 proto3 列舉型別將保留在訊息中,但訊息反序列化時如何表示是與語言相關的。(這點和語言相關,上面提到過了)Int 域始終只保留它們的值。
- 將單個值更改為新的成員是安全和二進位制相容的。如果您確定一次沒有程式碼設定多個欄位,則將多個欄位移至新的欄位可能是安全的。將任何欄位移到現有欄位中都是不安全的。(注意欄位和值的區別,欄位是 field,值是 value)
9. 未知欄位
未知數字段是 protocol buffers 序列化的資料,表示解析器無法識別的欄位。例如,當一箇舊的二進位制檔案解析由新的二進位制檔案傳送的新資料的資料時,這些新的欄位將成為舊的二進位制檔案中的未知欄位。
Proto3 實現可以成功解析未知欄位的訊息,但是,實現可能會或可能不會支援保留這些未知欄位。你不應該依賴儲存或刪除未知域。對於大多數 Google protocol buffers 實現,未知欄位在 proto3 中無法通過相應的 proto 執行時訪問,並且在反序列化時被丟棄和遺忘。這是與 proto2 的不同行為,其中未知欄位總是與訊息一起儲存並序列化。
10. Map 型別
repeated 型別可以用來表示陣列,Map 型別則可以用來表示字典。
map<key_type, value_type> map_field = N;
map<string, Project> projects = 3;
key_type 可以是任何 int 或者 string 型別(任何的標量型別,具體可以見上面標量型別對應表格,但是要除去 float、double 和 bytes)
列舉值也不能作為 key。
key_type 可以是除去 map 以外的任何型別。
需要特別注意的是 :
- map 是不能用 repeated 修飾的。
- 線性陣列和 map 迭代順序的是不確定的,所以你不能依靠你的 map 是在一個特定的順序。
- 為
.proto生成文字格式時,map 按 key 排序。數字的 key 按數字排序。 - 從陣列中解析或合併時,如果有重複的 key,則使用所看到的最後一個 key(覆蓋原則)。從文字格式解析對映時,如果有重複的 key,解析可能會失敗。
Protocol Buffer 雖然不支援 map 型別的陣列,但是可以轉換一下,用以下思路實現 maps 陣列:
message MapFieldEntry {
key_type key = 1;
value_type value = 2;
}
repeated MapFieldEntry map_field = N;
上述寫法和 map 陣列是完全等價的,所以用 repeated 巧妙的實現了 maps 陣列的需求。
11. JSON Mapping
Proto3 支援 JSON 中的規範編碼,使系統之間共享資料變得更加容易。編碼在下表中按型別逐個描述。
如果 JSON 編碼資料中缺少值或其值為空,則在解析為 protocol buffer 時,它將被解釋為適當的預設值。如果一個欄位在協議緩衝區中具有預設值,預設情況下它將在 JSON 編碼資料中省略以節省空間。具體 Mapping 的實現可以提供選項決定是否在 JSON 編碼的輸出中傳送具有預設值的欄位。
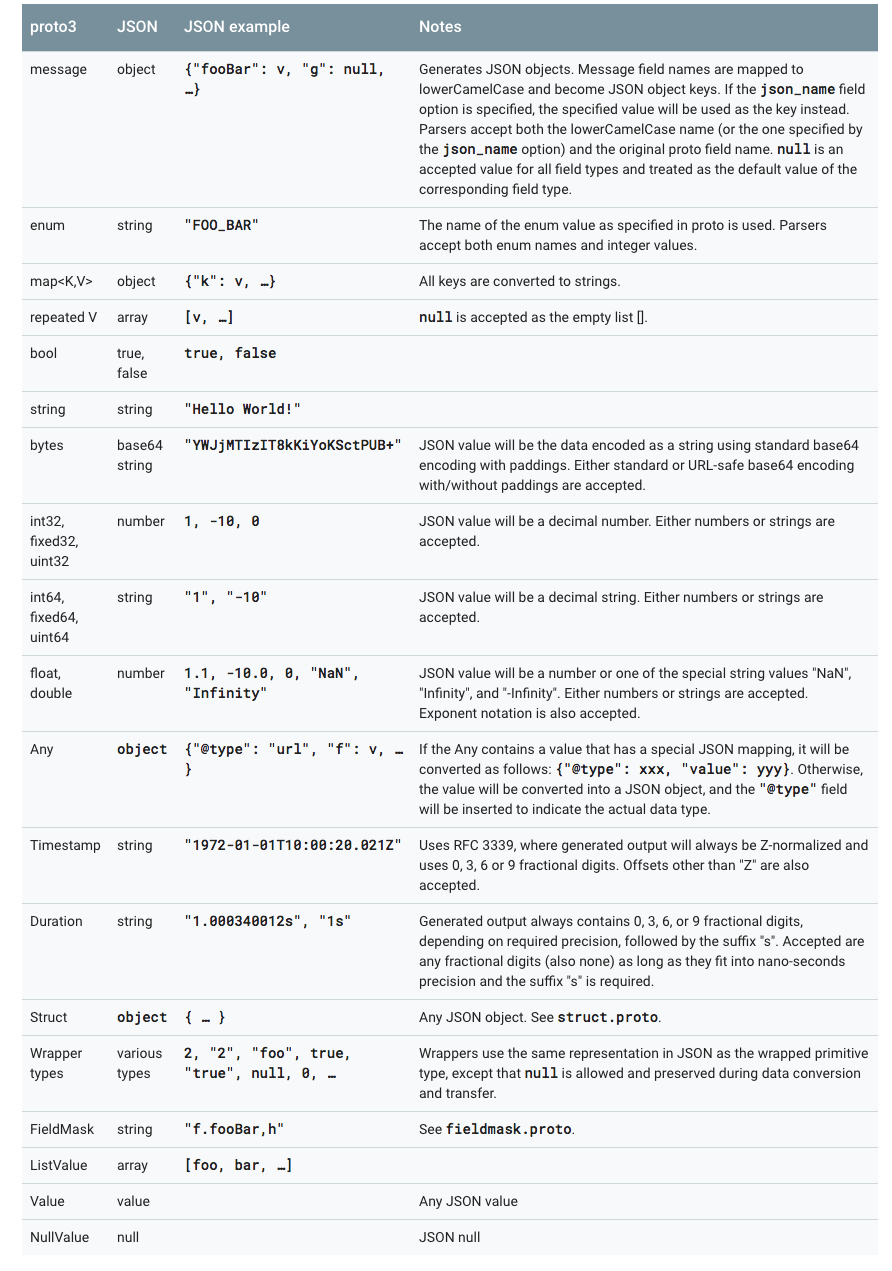
proto3 的 JSON 實現中提供了以下 4 中 options:
- 使用預設值傳送欄位:在預設情況下,預設值的欄位在 proto3 JSON 輸出中被忽略。一個實現可以提供一個選項來覆蓋這個行為,並使用它們的預設值輸出欄位。
- 忽略未知欄位:預設情況下,Proto3 JSON 解析器應拒絕未知欄位,但可能提供一個選項來忽略解析中的未知欄位。
- 使用 proto 欄位名稱而不是 lowerCamelCase 名稱:預設情況下,proto3 JSON 的 printer 將欄位名稱轉換為 lowerCamelCase 並將其用作 JSON 名稱。實現可能會提供一個選項,將原始欄位名稱用作 JSON 名稱。 Proto3 JSON 解析器需要接受轉換後的 lowerCamelCase 名稱和原始欄位名稱。
- 傳送列舉形式的列舉值而不是字串:在 JSON 輸出中預設使用列舉值的名稱。可以提供一個選項來使用列舉值的數值。
四. proto3 定義 Services
如果要使用 RPC(遠端過程呼叫)系統的訊息型別,可以在 .proto 檔案中定義 RPC 服務介面,protocol buffer 編譯器將使用所選語言生成服務介面程式碼和 stubs。所以,例如,如果你定義一個 RPC 服務,入參是 SearchRequest 返回值是 SearchResponse,你可以在你的 .proto 檔案中定義它,如下所示:
service SearchService {
rpc Search (SearchRequest) returns (SearchResponse);
}
與 protocol buffer 一起使用的最直接的 RPC 系統是 gRPC:在谷歌開發的語言和平臺中立的開源 RPC 系統。gRPC 在 protocol buffer 中工作得非常好,並且允許你通過使用特殊的 protocol buffer 編譯外掛,直接從 .proto 檔案中生成 RPC 相關的程式碼。
如果你不想使用 gRPC,也可以在你自己的 RPC 實現中使用 protocol buffers。您可以在 Proto2 語言指南中找到更多關於這些相關的資訊。
還有一些正在進行的第三方專案為 Protocol Buffers 開發 RPC 實現。
五. Protocol Buffer 命名規範
message 採用駝峰命名法。message 首字母大寫開頭。欄位名採用下劃線分隔法命名。
message SongServerRequest {
required string song_name = 1;
}
列舉型別採用駝峰命名法。列舉型別首字母大寫開頭。每個列舉值全部大寫,並且採用下劃線分隔法命名。
enum Foo {
FIRST_VALUE = 0;
SECOND_VALUE = 1;
}
每個列舉值用分號結束,不是逗號。
服務名和方法名都採用駝峰命名法。並且首字母都大寫開頭。
service FooService {
rpc GetSomething(FooRequest) returns (FooResponse);
}
六. Protocol Buffer 編碼原理
在討論 Protocol Buffer 編碼原理之前,必須先談談 Varints 編碼。
Base 128 Varints 編碼
Varint 是一種緊湊的表示數字的方法。它用一個或多個位元組來表示一個數字,值越小的數字使用越少的位元組數。這能減少用來表示數字的位元組數。
Varint 中的每個位元組(最後一個位元組除外)都設定了最高有效位(msb),這一位表示還會有更多位元組出現。每個位元組的低 7 位用於以 7 位組的形式儲存數字的二進位制補碼錶示,最低有效組首位。
如果用不到 1 個位元組,那麼最高有效位設為 0 ,如下面這個例子,1 用一個位元組就可以表示,所以 msb 為 0.
C0000 0001
如果需要多個位元組表示,msb 就應該設定為 1 。例如 300,如果用 Varint 表示的話:
C1010 1100 0000 0010
如果按照正常的二進位制計算的話,這個表示的是 88068(65536 + 16384 + 4096 + 2048 + 4)。
那 Varint 是怎麼編碼的呢?
下面程式碼是 Varint int 32 的編碼計算方法。
Cchar* EncodeVarint32(char* dst, uint32_t v) { // Operate on characters as unsigneds unsigned char* ptr = reinterpret_cast<unsigned char*>(dst); static const int B = 128; if (v < (1<<7)) { *(ptr++) = v; } else if (v < (1<<14)) { *(ptr++) = v | B; *(ptr++) = v>>7; } else if (v < (1<<21)) { *(ptr++) = v | B; *(ptr++) = (v>>7) | B; *(ptr++) = v>>14; } else if (v < (1<<28)) { *(ptr++) = v | B; *(ptr++) = (v>>7) | B; *(ptr++) = (v>>14) | B; *(ptr++) = v>>21; } else { *(ptr++) = v | B; *(ptr++) = (v>>7) | B; *(ptr++) = (v>>14) | B; *(ptr++) = (v>>21) | B; *(ptr++) = v>>28; } return reinterpret_cast<char*>(ptr); } 300 = 100101100
由於 300 超過了 7 位(Varint 一個位元組只有 7 位能用來表示數字,最高位 msb 用來表示後面是否有更多位元組),所以 300 需要用 2 個位元組來表示。
Varint 的編碼,以 300 舉例:
Cif (v < (1<<14)) { *(ptr++) = v | B; *(ptr++) = v>>7; } 1. 100101100 | 10000000 = 1 1010 1100 2. 110101100 取出末尾 7 位 = 010 1100 3. 100101100 >> 7 = 10 = 0000 0010 4. 1010 1100 0000 0010 (最終 Varint 結果) Varint 的解碼演算法應該是這樣的:(實際就是編碼的逆過程)
- 如果是多個位元組,先去掉每個位元組的 msb(通過邏輯或運算),每個位元組只留下 7 位。
- 逆序整個結果,最多是 5 個位元組,排序是 1-2-3-4-5,逆序之後就是 5-4-3-2-1,位元組內部的二進位制位的順序不變,變的是位元組的相對位置。
解碼過程呼叫 GetVarint32Ptr 函式,如果是大於一個位元組的情況,會呼叫 GetVarint32PtrFallback 來處理。
Cinline const char* GetVarint32Ptr(const char* p, const char* limit, uint32_t* value) { if (p < limit) { uint32_t result = *(reinterpret_cast<const unsigned char*>(p)); if ((result & 128) == 0) { *value = result; return p + 1; } } return GetVarint32PtrFallback(p, limit, value); } const char* GetVarint32PtrFallback(const char* p, const char* limit, uint32_t* value) { uint32_t result = 0; for (uint32_t shift = 0; shift <= 28 && p < limit; shift += 7) { uint32_t byte = *(reinterpret_cast<const unsigned char*>(p)); p++; if (byte & 128) { // More bytes are present result |= ((byte & 127) << shift); } else { result |= (byte << shift); *value = result; return reinterpret_cast<const char*>(p); } } return NULL; } 至此,Varint 處理過程讀者應該都熟悉了。上面列舉出了 Varint 32 的演算法,64 位的同理,只不過不再用 10 個分支來寫程式碼了,太醜了。(32位 是 5 個 位元組,64位 是 10 個位元組)
64 位 Varint 編碼實現:
Cchar* EncodeVarint64(char* dst, uint64_t v) { static const int B = 128; unsigned char* ptr = reinterpret_cast<unsigned char*>(dst); while (v >= B) { *(ptr++) = (v & (B-1)) | B; v >>= 7; } *(ptr++) = static_cast<unsigned char>(v); return reinterpret_cast<char*>(ptr); } 原理不變,只不過用迴圈來解決了。
64 位 Varint 解碼實現:
Cconst char* GetVarint64Ptr(const char* p, const char* limit, uint64_t* value) { uint64_t result = 0; for (uint32_t shift = 0; shift <= 63 && p < limit; shift += 7) { uint64_t byte = *(reinterpret_cast<const unsigned char*>(p)); p++; if (byte & 128) { // More bytes are present result |= ((byte & 127) << shift); } else { result |= (byte << shift); *value = result; return reinterpret_cast<const char*>(p); } } return NULL; } 讀到這裡可能有讀者會問了,Varint 不是為了緊湊 int 的麼?那 300 本來可以用 2 個位元組表示,現在還是 2 個位元組了,哪裡緊湊了,花費的空間沒有變啊?!
Varint 確實是一種緊湊的表示數字的方法。它用一個或多個位元組來表示一個數字,值越小的數字使用越少的位元組數。這能減少用來表示數字的位元組數。比如對於 int32 型別的數字,一般需要 4 個 byte 來表示。但是採用 Varint,對於很小的 int32 型別的數字,則可以用 1 個 byte 來表示。當然凡事都有好的也有不好的一面,採用 Varint 表示法,大的數字則需要 5 個 byte 來表示。從統計的角度來說,一般不會所有的訊息中的數字都是大數,因此大多數情況下,採用 Varint 後,可以用更少的位元組數來表示數字資訊。
300 如果用 int32 表示,需要 4 個位元組,現在用 Varint 表示,只需要 2 個位元組了。縮小了一半!
1. Message Structure 編碼
protocol buffer 中 message 是一系列鍵值對。message 的二進位制版本只是使用欄位號(field's number 和 wire_type)作為 key。每個欄位的名稱和宣告型別只能在解碼端通過引用訊息型別的定義(即 .proto 檔案)來確定。這一點也是人們常常說的 protocol buffer 比 JSON,XML 安全一點的原因,如果沒有資料結構描述 .proto 檔案,拿到資料以後是無法解釋成正常的資料的。
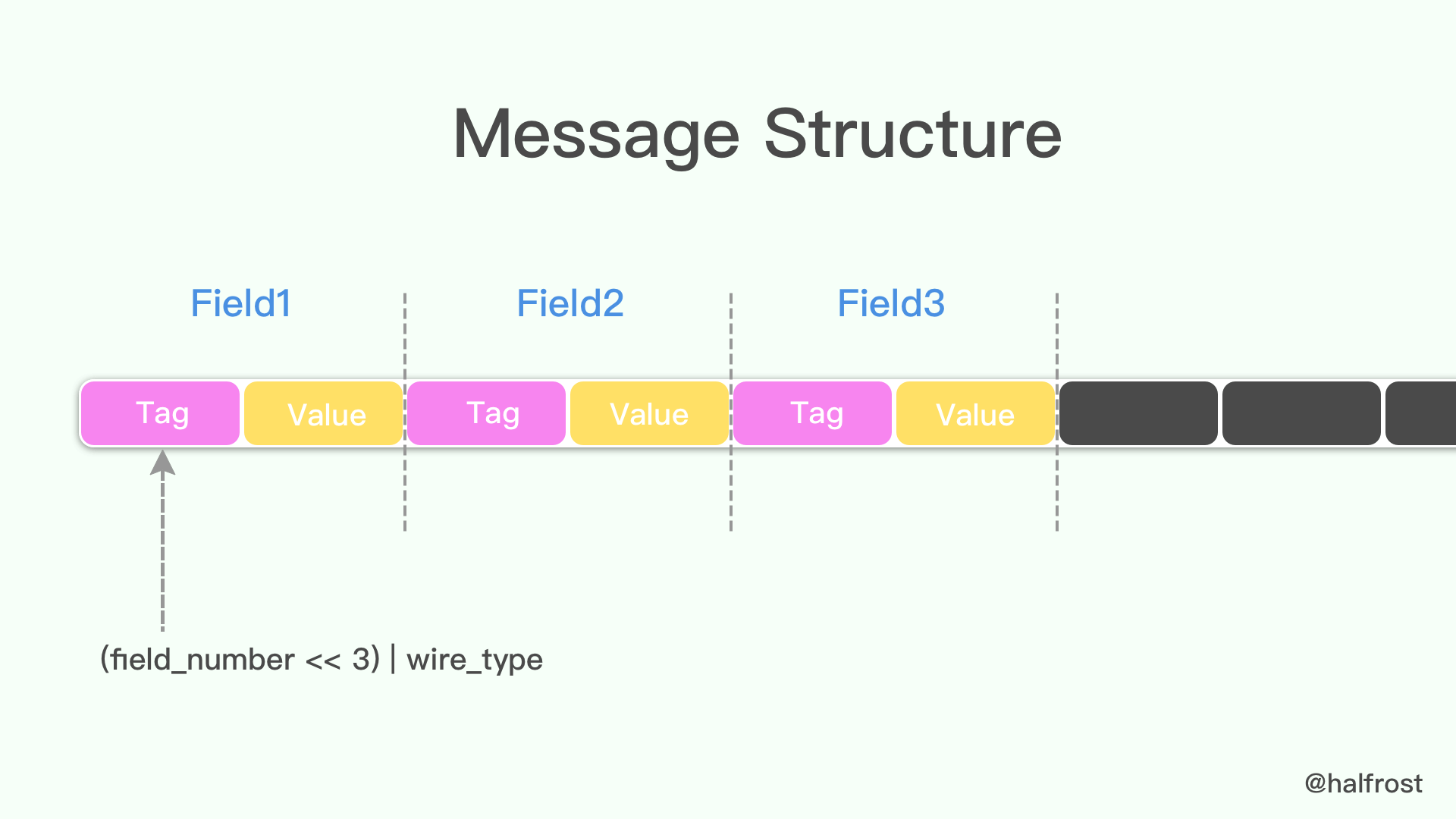
由於採用了 tag-value 的形式,所以 option 的 field 如果有,就存在在這個 message buffer 中,如果沒有,就不會在這裡,這一點也算是壓縮了 message 的大小了。
當訊息編碼時,鍵和值被連線成一個位元組流。當訊息被解碼時,解析器需要能夠跳過它無法識別的欄位。這樣,可以將新欄位新增到訊息中,而不會破壞不知道它們的舊程式。這就是所謂的 “向後”相容性。
為此,線性的格式訊息中每對的“key”實際上是兩個值,其中一個是來自.proto檔案的欄位編號,加上提供正好足夠的資訊來查詢下一個值的長度。在大多數語言實現中,這個 key 被稱為 tag。
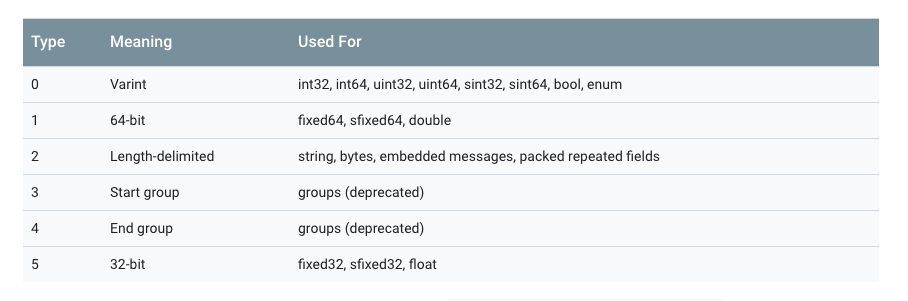
注意上圖中,3 和 4 已經被廢棄了,所以 wire_type 取值目前只有 0、1、2、5。
key 的計算方法是 (field_number << 3) | wire_type,換句話說,key 的最後 3 位表示的就是 wire_type。
舉例,一般 message 的欄位號都是 1 開始的,所以對應的 tag 可能是這樣的:
C000 1000
末尾 3 位表示的是 value 的型別,這裡是 000,即 0 ,代表的是 varint 值。右移 3 位,即 0001,這代表的就是欄位號(field number)。tag 的例子就舉這麼多,接下來舉一個 value 的例子,還是用 varint 來舉例:
C96 01 = 1001 0110 0000 0001 → 000 0001 ++ 001 0110 (drop the msb and reverse the groups of 7 bits) → 10010110 → 128 + 16 + 4 + 2 = 150 可以 96 01 代表的資料就是 150 。
message Test1 {
required int32 a = 1;
}
如果存在上面這樣的一個 message 的結構,如果存入 150,在 Protocol Buffer 中顯示的二進位制應該為 08 96 01 。
額外說一句,type 需要注意的是 type = 2 的情況,tag 裡面除了包含 field number 和 wire_type ,還需要再包含一個 length,決定 value 從那一段取出來。(具體原因見 Protocol Buffer 字串 這一章節)
2. Signed Integers 編碼
從上面的表格裡面可以看到 wire_type = 0 中包含了無符號的 varints,但是如果是一個無符號數呢?
一個負數一般會被表示為一個很大的整數,因為計算機定義負數的符號位為數字的最高位。如果採用 Varint 表示一個負數,那麼一定需要 10 個 byte 長度。為此 Google Protocol Buffer 定義了 sint32 這種型別,採用 zigzag 編碼。將所有整數對映成無符號整數,然後再採用 varint 編碼方式編碼,這樣,絕對值小的整數,編碼後也會有一個較小的 varint 編碼值。
Zigzag 對映函式為:
CZigzag(n) = (n << 1) ^ (n >> 31), n 為 sint32 時 Zigzag(n) = (n << 1) ^ (n >> 63), n 為 sint64 時 按照這種方法,-1 將會被編碼成 1,1 將會被編碼成 2,-2 會被編碼成 3,如下表所示:
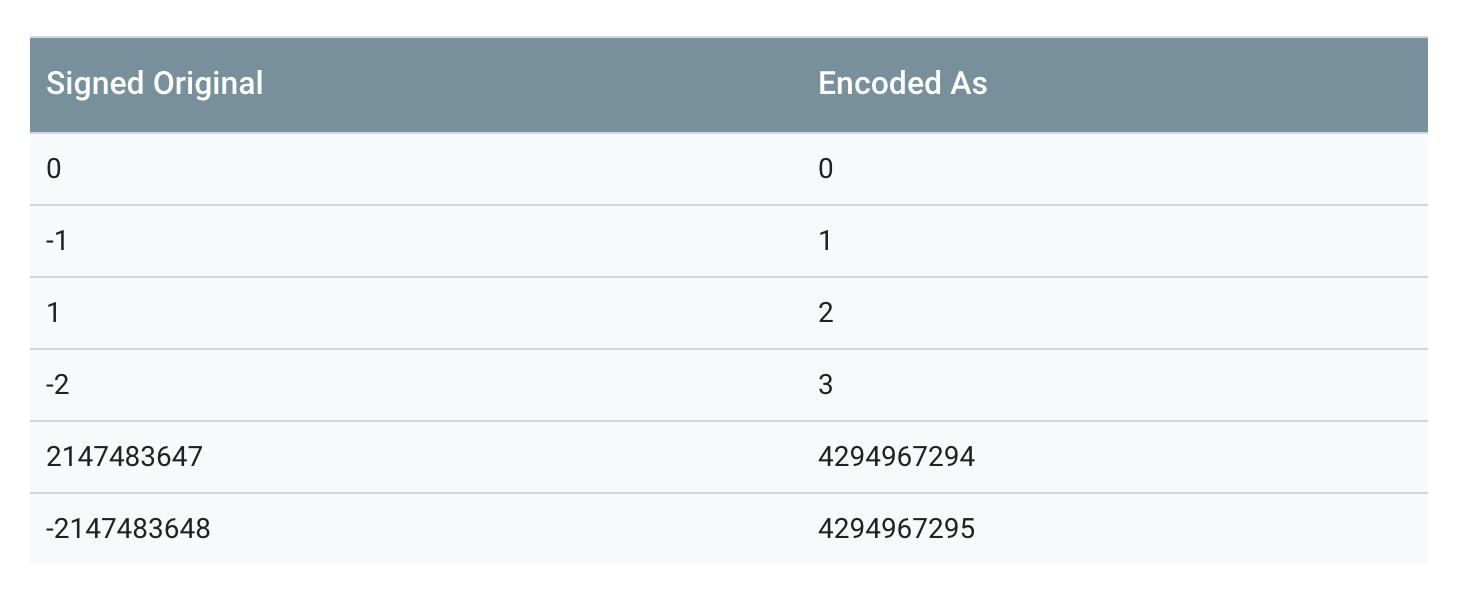
需要注意的是,第二個轉換 (n >> 31) 部分,是一個算術轉換。所以,換句話說,移位的結果要麼是一個全為0(如果n是正數),要麼是全部1(如果n是負數)。
當 sint32 或 sint64 被解析時,它的值被解碼回原始的帶符號的版本。
3. Non-varint Numbers
Non-varint 數字比較簡單,double 、fixed64 的 wire_type 為 1,在解析時告訴解析器,該型別的資料需要一個 64 位大小的資料塊即可。同理,float 和 fixed32 的 wire_type 為5,給其 32 位資料塊即可。兩種情況下,都是高位在後,低位在前。
說 Protocol Buffer 壓縮資料沒有到極限,原因就在這裡,因為並沒有壓縮 float、double 這些浮點型別。
4. 字串
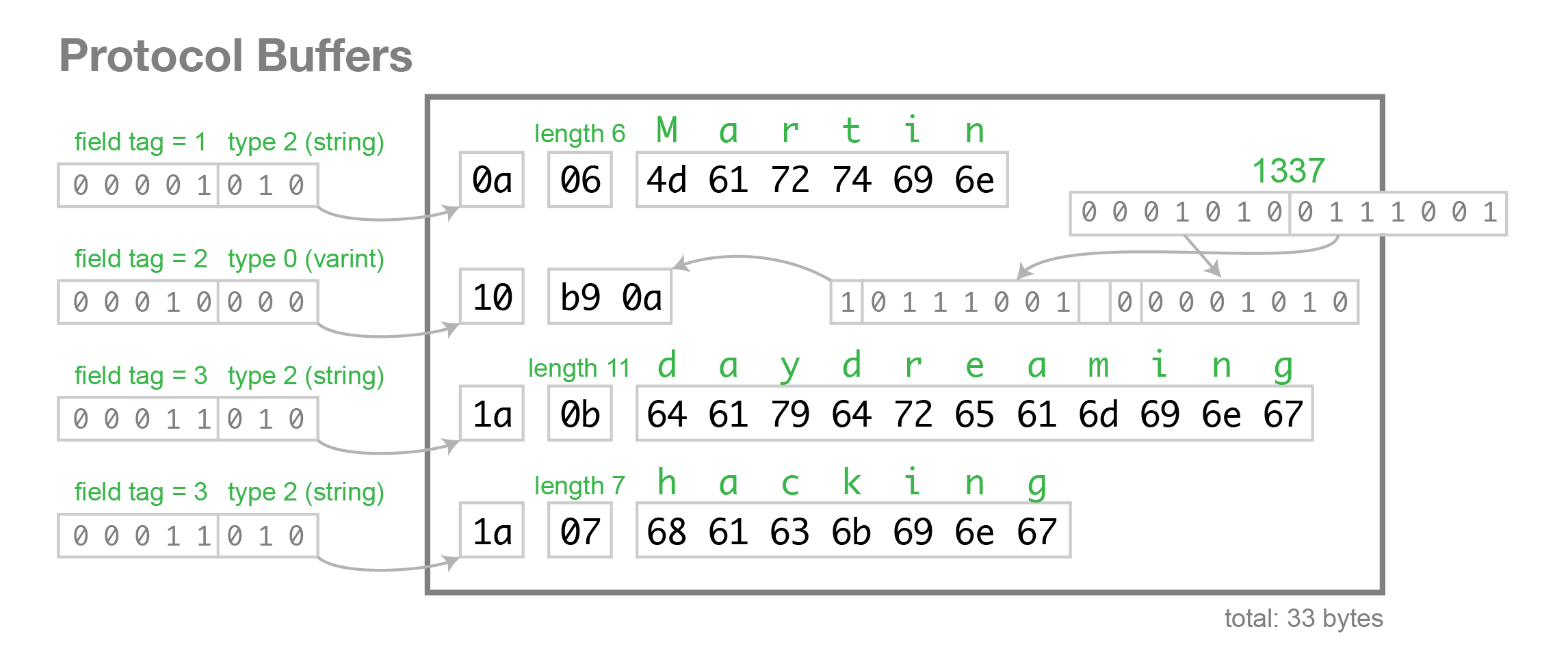
wire_type 型別為 2 的資料,是一種指定長度的編碼方式:key + length + content,key 的編碼方式是統一的,length 採用 varints 編碼方式,content 就是由 length 指定長度的 Bytes。
舉例,假設定義如下的 message 格式:
message Test2 {
optional string b = 2;
}
設定該值為"testing",二進位制格式檢視:
C12 07 74 65 73 74 69 6e 67 74 65 73 74 69 6e 67 是“testing”的 UTF8 程式碼。
此處,key 是16進製表示的,所以展開是:
12 -> 0001 0010,後三位 010 為 wire type = 2,0001 0010 右移三位為 0000 0010,即 tag = 2。
length 此處為 7,後邊跟著 7 個bytes,即我們的字串"testing"。
所以 wire_type 型別為 2 的資料,編碼的時候會預設轉換為 T-L-V (Tag - Length - Value)的形式。
5. 嵌入式 message
假設,定義如下巢狀訊息:
message Test3 {
optional Test1 c = 3;
}
設定欄位為整數150,編碼後的位元組為:
C1a 03 08 96 01
08 96 01 這三個代表的是 150,上面講解過,這裡就不再贅述了。
1a -> 0001 1010,後三位 010 為 wire type = 2,0001 1010 右移三位為 0000 0011,即 tag = 3。
length 為 3,代表後面有 3 個位元組,即 08 96 01 。
需要轉變為 T - L - V 形式的還有 string, bytes, embedded messages, packed repeated fields (即 wire_type 為 2 的形式都會轉變成 T - L - V 形式)
6. Optional 和 Repeated 的編碼
在 proto2 中定義成 repeated 的欄位,(沒有加上 [packed=true] option ),編碼後的 message 有一個或者多個包含相同 tag 數字的 key-value 對。這些重複的 value 不需要連續的出現;他們可能與其他的欄位間隔的出現。儘管他們是無序的,但是在解析時,他們是需要有序的。在 proto3 中 repeated 欄位預設採用 packed 編碼(具體原因見 Packed Repeated Fields 這一章節)
對於 proto3 中的任何非重複欄位或 proto2 中的可選欄位,編碼的 message 可能有也可能沒有包含該欄位號的鍵值對。
通常,編碼後的 message,其 required 欄位和 optional 欄位最多隻有一個例項。但是解析器卻需要處理多對一的情況。對於數字型別和 string 型別,如果同一值出現多次,解析器接受最後一個它收到的值。對於內嵌欄位,解析器合併(merge)它接收到的同一欄位