
遞進分析:Paxos演算法與Zookeeper分析
轉載:https://blog.csdn.net/xhh198781/article/details/10949697
Paxos演算法與Zookeeper分析
1 Paxos演算法
1.1 基本定義
演算法中的參與者主要分為三個角色,同時每個參與者又可兼領多個角色:
⑴proposer 提出提案,提案資訊包括提案編號和提議的value;
⑵acceptor 收到提案後可以接受(accept)提案;
⑶learner 只能"學習"被批准的提案;
演算法保重一致性的基本語義:
⑴決議(value)只有在被proposers提出後才能被批准(未經批准的決議稱為"提案(proposal)");
⑵在一次Paxos演算法的執行例項中,只批准(chosen)一個value;
⑶learners只能獲得被批准(chosen)的value;
有上面的三個語義可演化為四個約束:
⑴P1:一個acceptor必須接受(accept)第一次收到的提案;
⑵P2a:一旦一個具有value v的提案被批准(chosen),那麼之後任何acceptor 再次接受(accept)的提案必須具有value v;
⑶P2b:一旦一個具有value v的提案被批准(chosen),那麼以後任何 proposer 提出的提案必須具有value v;
⑷P2c:如果一個編號為n的提案具有value v,那麼存在一個多數派,要麼他們中所有人都沒有接受(accept)編號小於n的任何提案,要麼他們已經接受(accpet)的所有編號小於n的提案中編號最大的那個提案具有value v;
1.2 基本演算法(basic paxos)
演算法(決議的提出與批准)主要分為兩個階段:
1. prepare階段:
(1). 當Porposer希望提出方案V1,首先發出prepare請求至大多數Acceptor。Prepare請求內容為序列號<SN1>;
(2). 當Acceptor接收到prepare請求<SN1>時,檢查自身上次回覆過的prepare請求<SN2>
a). 如果SN2>SN1,則忽略此請求,直接結束本次批准過程;
b). 否則檢查上次批准的accept請求<SNx,Vx>,並且回覆<SNx,Vx>;如果之前沒有進行過批准,則簡單回覆<OK>;
2. accept批准階段:
(1a). 經過一段時間,收到一些Acceptor回覆,回覆可分為以下幾種:
a). 回覆數量滿足多數派,並且所有的回覆都是<OK>,則Porposer發出accept請求,請求內容為議案<SN1,V1>;
b). 回覆數量滿足多數派,但有的回覆為:<SN2,V2>,<SN3,V3>……則Porposer找到所有回覆中超過半數的那個,假設為<SNx,Vx>,則發出accept請求,請求內容為議案<SN1,Vx>;
c). 回覆數量不滿足多數派,Proposer嘗試增加序列號為SN1+,轉1繼續執行;
(1b). 經過一段時間,收到一些Acceptor回覆,回覆可分為以下幾種:
a). 回覆數量滿足多數派,則確認V1被接受;
b). 回覆數量不滿足多數派,V1未被接受,Proposer增加序列號為SN1+,轉1繼續執行;
(2). 在不違背自己向其他proposer的承諾的前提下,acceptor收到accept 請求後即接受並回復這個請求。
1.3 演算法優化(fast paxos)
Paxos演算法在出現競爭的情況下,其收斂速度很慢,甚至可能出現活鎖的情況,例如當有三個及三個以上的proposer在傳送prepare請求後,很難有一個proposer收到半數以上的回覆而不斷地執行第一階段的協議。因此,為了避免競爭,加快收斂的速度,在演算法中引入了一個Leader這個角色,在正常情況下同時應該最多隻能有一個參與者扮演Leader角色,而其它的參與者則扮演Acceptor的角色,同時所有的人又都扮演Learner的角色。
在這種優化演算法中,只有Leader可以提出議案,從而避免了競爭使得演算法能夠快速地收斂而趨於一致,此時的paxos演算法在本質上就退變為兩階段提交協議。但在異常情況下,系統可能會出現多Leader的情況,但這並不會破壞演算法對一致性的保證,此時多個Leader都可以提出自己的提案,優化的演算法就退化成了原始的paxos演算法。
一個Leader的工作流程主要有分為三個階段:
(1).學習階段 向其它的參與者學習自己不知道的資料(決議);
(2).同步階段 讓絕大多數參與者保持資料(決議)的一致性;
(3).服務階段 為客戶端服務,提議案;
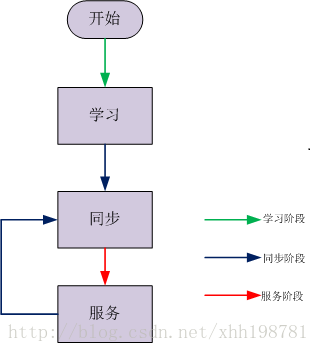
1.3.1 學習階段
當一個參與者成為了Leader之後,它應該需要知道絕大多數的paxos例項,因此就會馬上啟動一個主動學習的過程。假設當前的新Leader早就知道了1-134、138和139的paxos例項,那麼它會執行135-137和大於139的paxos例項的第一階段。如果只檢測到135和140的paxos例項有確定的值,那它最後就會知道1-135以及138-140的paxos例項。
1.3.2 同步階段
此時的Leader已經知道了1-135、138-140的paxos例項,那麼它就會重新執行1-135的paxos例項,以保證絕大多數參與者在1-135的paxos例項上是保持一致的。至於139-140的paxos例項,它並不馬上執行138-140的paxos例項,而是等到在服務階段填充了136、137的paxos例項之後再執行。這裡之所以要填充間隔,是為了避免以後的Leader總是要學習這些間隔中的paxos例項,而這些paxos例項又沒有對應的確定值。
1.3.4 服務階段
Leader將使用者的請求轉化為對應的paxos例項,當然,它可以併發的執行多個paxos例項,當這個Leader出現異常之後,就很有可能造成paxos例項出現間斷。
1.3.5 問題
(1).Leader的選舉原則
(2).Acceptor如何感知當前Leader的失敗,客戶如何知道當前的Leader
(3).當出現多Leader之後,如何kill掉多餘的Leader
(4).如何動態的擴充套件Acceptor
2. Zookeeper
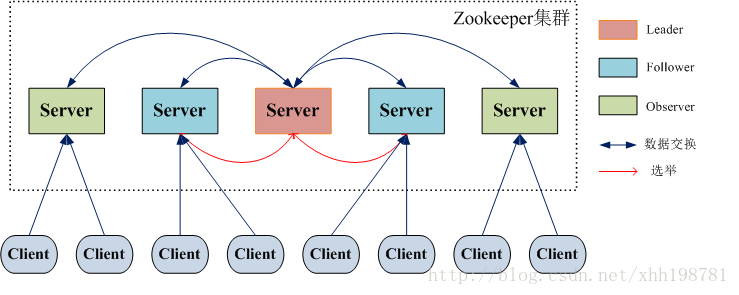
2.1 整體架構
在Zookeeper叢集中,主要分為三者角色,而每一個節點同時只能扮演一種角色,這三種角色分別是:
(1). Leader 接受所有Follower的提案請求並統一協調發起提案的投票,負責與所有的Follower進行內部的資料交換(同步);
(2). Follower 直接為客戶端服務並參與提案的投票,同時與Leader進行資料交換(同步);
(3). Observer 直接為客戶端服務但並不參與提案的投票,同時也與Leader進行資料交換(同步);
2.2 QuorumPeer的基本設計
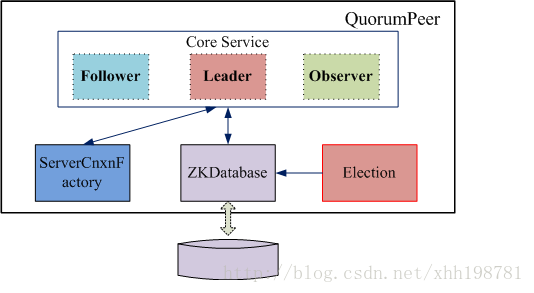
Zookeeper對於每個節點QuorumPeer的設計相當的靈活,QuorumPeer主要包括四個元件:客戶端請求接收器(ServerCnxnFactory)、資料引擎(ZKDatabase)、選舉器(Election)、核心功能元件(Leader/Follower/Observer)。其中:
(1). ServerCnxnFactory負責維護與客戶端的連線(接收客戶端的請求併發送相應的響應);
(2). ZKDatabase負責儲存/載入/查詢資料(基於目錄樹結構的KV+操作日誌+客戶端Session);
(3). Election負責選舉叢集的一個Leader節點;
(4). Leader/Follower/Observer一個QuorumPeer節點應該完成的核心職責;
2.3 QuorumPeer工作流程
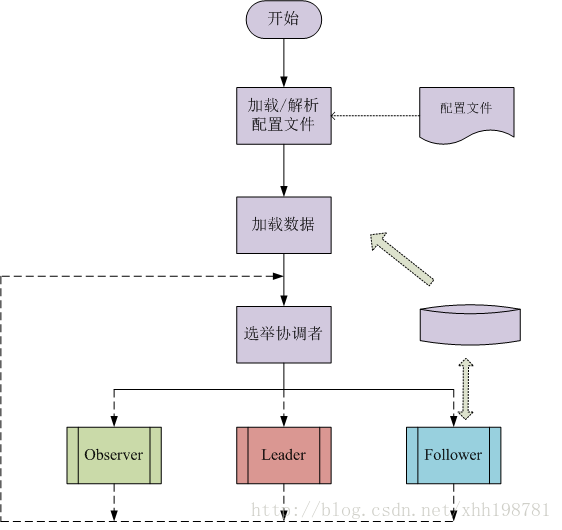
2.3.1 Leader職責
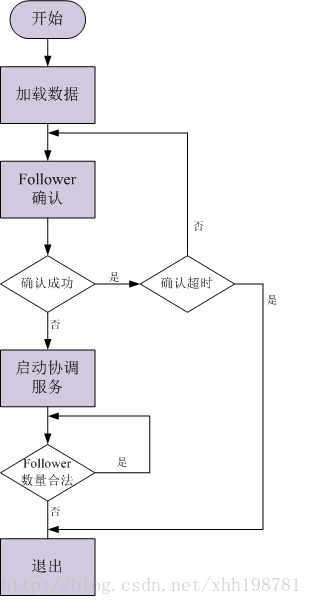
Follower確認: 等待所有的Follower連線註冊,若在規定的時間內收到合法的Follower註冊數量,則確認成功;否則,確認失敗。
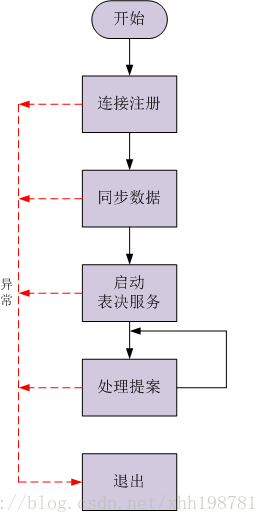
2.3.2 Follower職責
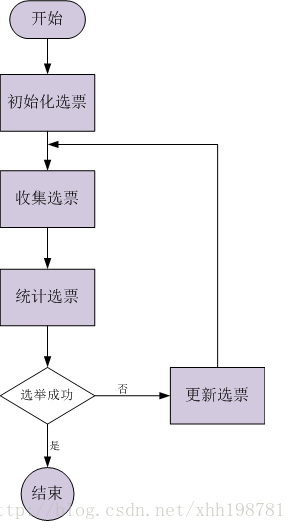
2.4 選舉演算法
2.4.1 LeaderElection選舉演算法
選舉執行緒由當前Server發起選舉的執行緒擔任,他主要的功能對投票結果進行統計,並選出推薦的Server。選舉執行緒首先向所有Server發起一次詢問(包括自己),被詢問方,根據自己當前的狀態作相應的回覆,選舉執行緒收到回覆後,驗證是否是自己發起的詢問(驗證xid 是否一致),然後獲取對方的id(myid),並存儲到當前詢問物件列表中,最後獲取對方提議 的
leader 相關資訊(id,zxid),並將這些 資訊儲存到當次選舉的投票記錄表中,當向所有Serve r
都詢問完以後,對統計結果進行篩選並進行統計,計算出當次詢問後獲勝的是哪一個Server,並將當前zxid最大的Server 設定為當前Server要推薦的Server(有可能是自己,也有可以是其它的Server,根據投票結果而定,但是每一個Server在第一次投票時都會投自己),如果此時獲勝的Server獲得n/2 + 1的Server票數,設定當前推薦的leader為獲勝的Server。根據獲勝的Server相關資訊設定自己的狀態。每一個Server都重複以上流程直到選舉出Leader。
初始化選票(第一張選票): 每個quorum節點一開始都投給自己;
收集選票: 使用UDP協議儘量收集所有quorum節點當前的選票(單執行緒/同步方式),超時設定200ms;
統計選票: 1).每個quorum節點的票數;
2).為自己產生一張新選票(zxid、myid均最大);
選舉成功: 某一個quorum節點的票數超過半數;
更新選票: 在本輪選舉失敗的情況下,當前quorum節點會從收集的選票中選取合適的選票(zxid、myid均最大)作為自己下一輪選舉的投票;
異常問題的處理
1). 選舉過程中,Server的加入
當一個Server啟動時它都會發起一次選舉,此時由選舉執行緒發起相關流程,那麼每個 Serve r都會獲得當前zxi d最大的哪個Serve r是誰,如果當次最大的Serve r沒有獲得n/2+1 個票數,那麼下一次投票時,他將向zxid最大的Server投票,重複以上流程,最後一定能選舉出一個Leader。
2). 選舉過程中,Server的退出
只要保證n/2+1個Server存活就沒有任何問題,如果少於n/2+1個Server 存活就沒辦法選出Leader。
3). 選舉過程中,Leader死亡
當選舉出Leader以後,此時每個Server應該是什麼狀態(FLLOWING)都已經確定,此時由於Leader已經死亡我們就不管它,其它的Fllower按正常的流程繼續下去,當完成這個流程以後,所有的Fllower都會向Leader傳送Ping訊息,如果無法ping通,就改變自己的狀為(FLLOWING ==> LOOKING),發起新的一輪選舉。
4). 選舉完成以後,Leader死亡
處理過程同上。
5). 雙主問題
Leader的選舉是保證只產生一個公認的Leader的,而且Follower重新選舉與舊Leader恢復並退出基本上是同時發生的,當Follower無法ping同Leader是就認為Leader已經出問題開始重新選舉,Leader收到Follower的ping沒有達到半數以上則要退出Leader重新選舉。
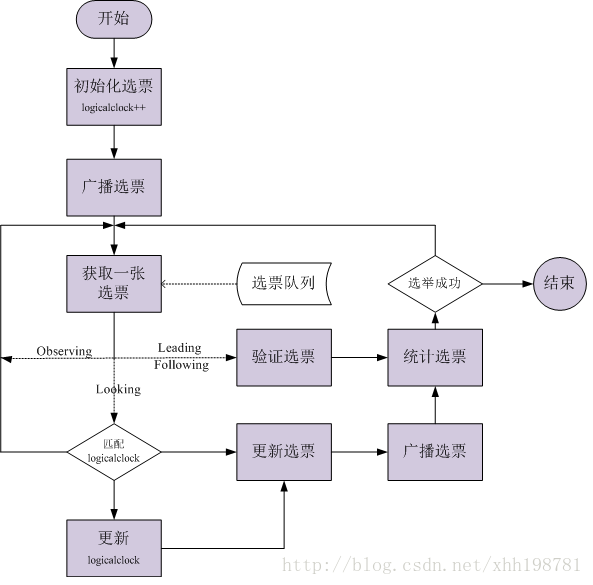
2.4.2 FastLeaderElection選舉演算法
FastLeaderElection是標準的fast paxos的實現,它首先向所有Server提議自己要成為leader,當其它Server收到提議以後,解決 epoch 和 zxid 的衝突,並接受對方的提議,然後向對方傳送接受提議完成的訊息。
FastLeaderElection演算法通過非同步的通訊方式來收集其它節點的選票,同時在分析選票時又根據投票者的當前狀態來作不同的處理,以加快Leader的選舉程序。
每個Server都一個接收執行緒池和一個傳送執行緒池, 在沒有發起選舉時,這兩個執行緒池處於阻塞狀態,直到有訊息到來時才解除阻塞並處理訊息,同時每個Serve r都有一個選舉執行緒(可以發起選舉的執行緒擔任)。
1). 主動發起選舉端(選舉執行緒)的處理
首先自己的 logicalclock加1,然後生成notification訊息,並將訊息放入傳送佇列中, 系統中配置有幾個Server就生成幾條訊息,保證每個Server都能收到此訊息,如果當前Server 的狀態是LOOKING就一直迴圈檢查接收佇列是否有訊息,如果有訊息,根據訊息中對方的狀態進行相應的處理。
2).主動傳送訊息端(傳送執行緒池)的處理
將要傳送的訊息由Notification訊息轉換成ToSend訊息,然後傳送對方,並等待對方的回覆。
3). 被動接收訊息端(接收執行緒池)的處理
將收到的訊息轉換成Notification訊息放入接收佇列中,如果對方Server的epoch小於logicalclock則向其傳送一個訊息(讓其更新epoch);如果對方Server處於Looking狀態,自己則處於Following或Leading狀態,則也傳送一個訊息(當前Leader已產生,讓其儘快收斂)。
2.4.3 AuthFastLeaderElection選舉演算法
AuthFastLeaderElection演算法同FastLeaderElection演算法基本一致,只是在訊息中加入了認證資訊,該演算法在最新的Zookeeper中也建議棄用。
2.5 Zookeeper的API
| 名稱 |
同步 |
非同步 |
watch |
許可權認證 |
| create |
√ |
√ |
|
√ |
| delete |
√ |
√ |
|
√ |
| exist |
√ |
√ |
√ |
|
| getData |
√ |
√ |
√ |
√ |
| setData |
√ |
√ |
|
√ |
| getACL |
√ |
√ |
|
|
| setACL |
√ |
√ |
|
√ |
| getChildren |
√ |
√ |
√ |
√ |
| sync |
|
√ |
|
|
| multi |
√ |
|
|
√ |
| createSession |
√ |
|
|
|
| closeSession |
√ |
|
|
|
2.6 Zookeeper中的請求處理流程
2.6.1 Follower節點處理使用者的讀寫請求
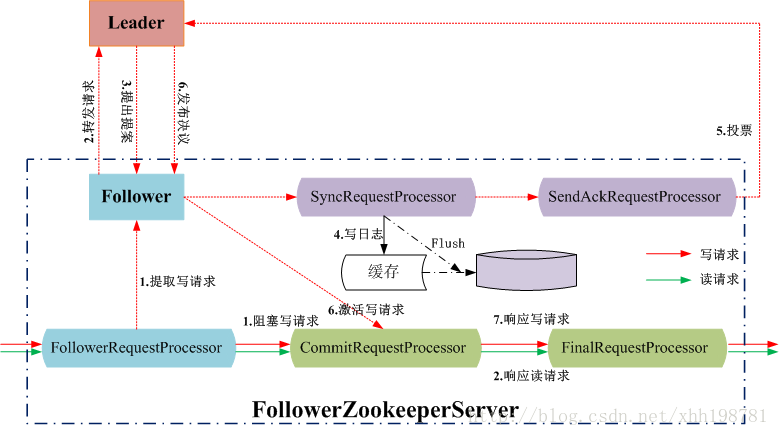
2.6.2 Leader節點處理寫請求
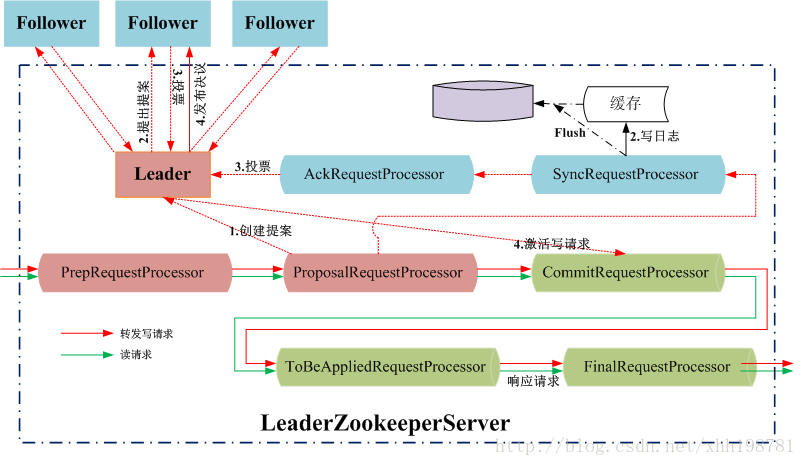
值得注意的是, Follower/Leader上的讀操作時並行的,讀寫操作是序列的,當CommitRequestProcessor處理一個寫請求時,會阻塞之後所有的讀寫請求。
通訊不可靠: 訊息延遲、訊息重複傳遞、訊息丟失