
Python 和 C 的賦值邏輯對比
目錄
摘要:
如果你學過 C 語言,那麼當你初見 Python 時可能會覺得 Python 的賦值方式略有詭異:好像差不多,但又好像哪裡有點不太對勁。
本文比較並解釋了這種賦值邏輯上的差異。回答了為什麼需要這種賦值邏輯以及如何使用這種賦值邏輯的問題。
當然,即使未學過 C 語言,也可通過本文更好地瞭解 Python 的賦值邏輯——這種賦值邏輯影響著 Python 的方方面面,從而可以讓你更好地理解和編寫 Python 程式。
第一章 引例
先來看一組似乎矛盾的程式碼:
# 程式碼 1 >>> a = 3 >>> b = a >>> b = 5 >>> a 3
這看上去似乎很好理解。第二步中, a 只是把值複製給 b,然後 b 又被更新為 5,a 和 b 是兩個獨立的變數,那麼 a 的值當然不會受到影響。
真的是這樣嗎?
再來看一段程式碼:
# 程式碼 2
>>> a = [1, 2, 3]
>>> b = a
>>> b[0] = 1024
>>> a
[1024, 2, 3]第二步中,a 只是複製把列表複製給 b,然後更新 b[0] 的值,最後輸出 a,可是 a 竟然也被改變了。
按照程式碼 1 的邏輯(即變數之間獨立),程式碼 2 的中的 a 不應該受到影響。
為什麼出現了這樣的差異?
第二章 Python 的“反直覺”
先不解釋上面那個“看似矛盾”的問題。
先來看看另一組簡單的 Python 程式碼在記憶體中是什麼樣子的:
# 程式碼 3
b = 3
b = b + 5它在記憶體中的操作示意圖是這樣的:
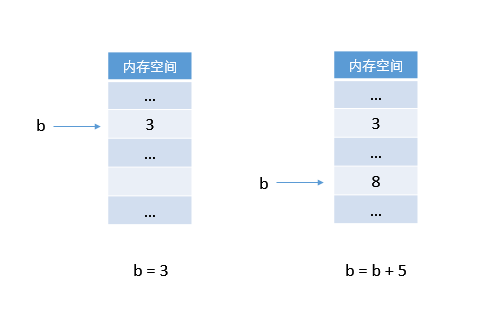
然而,從程式碼的的字面意思上看,“把 3 賦給 b,把 b 加 5 之後再賦給 b。”
也就是把程式碼看成這個樣子:
b ← 3
b ← b + 5所以下面這張在記憶體中的操作圖可能更符合我們的直覺:
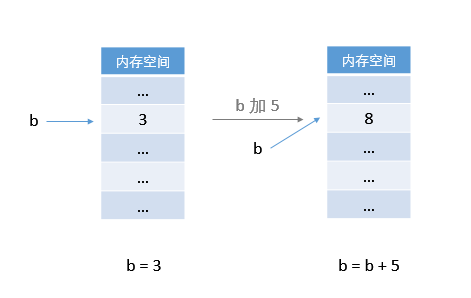
也即 b + 5 的值又寫回到 b 中。典型的 C 程式就是這樣的。為變數 b 分配一個 int 型的記憶體單元,然後將整數 3 存放在該記憶體單元中。b
b 的值,但 b 在記憶體中的地址就不再變化了。所以我們說 b = b + 5,就等於 b ← b + 5,把 b 的值加 5 之後還依然放入 b 中。 變數 b 和它所在記憶體空間緊緊繫結在一起,人形合一。
而再看看上面 Python 中的記憶體示意圖,b + 5 得到了一個新值,然後令 b 指向了這個新值。換句話說,它做的是事情是這樣的:
b → 3
b → b + 5先令 b 指向 3,再令 b 指向 b + 5 這個新值。
C 程式更新的是記憶體單元中存放的值,而 Python 更新的是變數的指向。 C 程式中變數儲存了一個值,而 Python 中的變數指向一個值。
如果說 C 程式是通過操縱記憶體地址而間接操作資料(每個變數固定對應一個記憶體地址,所以說操縱變數就是操縱記憶體地址),資料處於被動地位,那麼 Python 則是直接操縱資料,資料處於主動地位,變數只是作為一種引用關係而存在,而不再擁有儲存功能。
在 Python 中,每一個數據都會佔用一個記憶體空間,如 b + 5 這個新的資料也佔用了一個全新的記憶體空間。
Python 的這種操作讓資料成為主體,資料與資料之間直接進行互動。
而資料在 Python 中被稱為物件 (Object)。
這句話並不太嚴謹。不過在這個簡單的例子中是成立的。
一個整數 3 是一個 int 型物件,一個 'hello' 是一個字串物件,一個 [1, 2, 3] 是一個列表物件。
Python 把一切資料都看成「物件」。它為每一個物件分配一個記憶體空間。 一個物件被建立後,它的 id 就不再發生變化。
id 是 identity 的縮寫。意為“身份;標識”。 在 Python 中,可以使用
id(),來獲得一個物件的 id,可以看作是該物件在記憶體中的地址。
一個物件被建立後,它不能被直接銷燬。因此,在上個例子中,變數 b 首先指向了物件 3,然後繼續執行 b + 5,b + 5 產生了一個新的物件 8,由於物件 3 不能被銷燬,則令 b 指向新的物件 8,而不是用物件 8 去覆蓋物件 3。在程式碼執行完成後,記憶體中依然有物件 3,也有物件 8,變數 b 指向了物件 8。
如果沒有變數指向物件 3(即無法引用它了),Python 會使用垃圾回收演算法來決定是否回收它(這是自動的,不需要程式編寫者操心)。
一箇舊的物件不能被覆蓋,因舊的物件互動而新產生的資料會放在新的物件中。也就是說每個物件是一個獨立的個體,每個物件都有自己的“主權”。因此,兩個物件的互動可以產生一個新的物件,而不會對原物件產生影響。在大型程式中,各個物件之間的互動錯綜複雜,這種獨立性則使得這些互動足夠安全。
C 程式為每個變數都分配一個了固定的記憶體地址,這保證了 C 變數之間的獨立性。
C 語言是變數(也即記憶體地址)之間的互動,Python 是物件(資料)之間的互動。這是兩種不同的互動方式。
那麼,Python 這種資料之間直接進行互動的好處體現在哪裡?
很遺憾,這並不是本文所要討論的內容,該部分屬於面向物件設計的核心內容。本文只是對 Python 的這種互動方式與 C 語言的互動方式做了一些比較,以區分兩者在邏輯與物理上的差異所在。
相信這種邏輯會幫助你更好地編寫 Python 程式,並且幫助你在日後更加深入地理解面向物件的程式設計。
本章補充: Python 的賦值更改的是變數的指向關係,因此,對於 Python,從前向後閱讀一個賦值表示式會更加容易理解。
// C 語言 b ← b + 5 // 把 b+5 的值賦給 b # Python b → b + 5 # 令 b 指向 b + 5
第三章 回答第一章的問題
先看程式碼 1:
# 程式碼 1
>>> a = 3
>>> b = a
>>> b = 5
>>> a
3Python 中所有的資料都是物件,數字型別也不例外。3 是一個 int 型別的物件,5 也是一個 int 型的物件。
第一行,a 指向物件 3。
第二行,令 b 也指向 a 所指向的物件 3。
第三行,因為物件不可被覆蓋(銷燬),令 b 指向新物件 5,則只剩下 a 指向物件 3。
第四行,輸出 a,得到 3。
在記憶體中的操作示意圖 (Python):
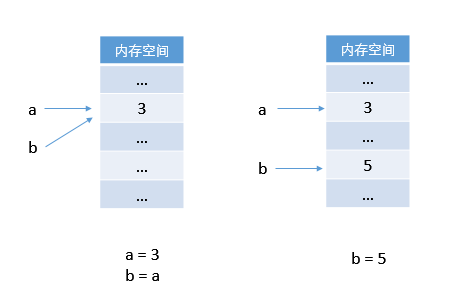
這與第一章中的解釋完全不同,第一章中的解釋是用 C 語言解釋的:
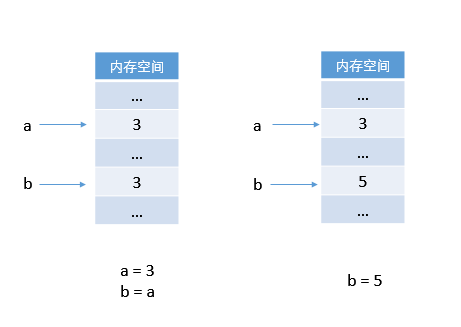
這是兩種完全不一樣的機制。
Python 中 b 首先指向了物件 3,然而因為物件之間的獨立性,一個物件不能去覆蓋另一個物件,則令 b 指向物件 5,而不是將物件 3 在記憶體中替換為物件 5。
再來看程式碼 2:
# 程式碼 2
>>> a = [1, 2, 3]
>>> b = a
>>> b[0] = 1024
>>> a
[1024, 2, 3]第一行,令 a 指向一個列表 [1, 2, 3];
第二行,令 b 也指向 a 所指向的列表;
第三行,令 b[0] = 1024,1024 雖然是一個物件,但它並沒有試圖覆蓋b所指向的物件,而是對該物件的第一個元素進行修改。修改,而不是覆蓋,所以它可以原物件進行操作,而不是令 b 指向修改後的物件。
所在第四行輸出的 a 所指向的列表也發生了變化。
在記憶體中的操作示意圖 (Python):
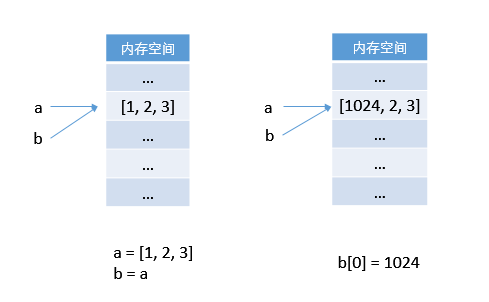
這種物件的值可以修改的物件被稱為可變物件 (immutable object)。常見的列表、字典為可變物件。
因為它的值可以被修改,因此如果有多個變數指向該列表:
a = [1, 2, 3]
b = a
c = a
d = a
...那麼使用 b, c, d, ... 的任何一個變數都能訪問該物件並修改其中的內容。這種特性常常被我們用於函式的引數傳遞,如果函式的引數是可變物件,那麼函式可以對“實參”中的內容進行修改:
>>> a = [1, 2, 3]
>>> def change(t):
t[0] = 1024
>>> change(a)
>>> a
[1024, 2, 3]
>>> 呼叫函式 change 時,令 t 也指向了 a 所指向的列表,然後使用 t 更改了列表中的第一個元素,更改,而不是覆蓋,因此對 t 所指向的物件的更改也改變了“實參” a 所指向的物件。而 C 語言則因為實參到形參是值傳遞,則無法改變實參的內容(雖然藉助指標可以實現,但這裡只說一般情況下)。
但在函式以外的區域,我們要儘量避免這樣使用,這很容易導致出錯(當然,有時候會很有用,這取決於你的程式)。比如,在多人協作程式設計時,如果甲不小心修改了某可變物件,那麼乙、丙、丁等用到該物件的人都會受到影響。
而對於不可變物件 (immutable object),即其值無法更改的物件,傳入函式時則不會影響“實參”的值:
>>> a = 5
>>> def add(n):
n = n + 2
>>> add(a)
>>> a
5呼叫函式 add 時,令 n 也指向了 a 所指向的物件 5, 再執行 n = n + 2,n 所指向的物件 5 與物件 2 相加得到了一個新的物件 7,由於一個物件不能覆蓋另一個物件,則 n 指向新的物件 7,而沒有改變原物件。因此 a 的值未發生變化。雖然與 C 程式的結果一致,但與 C 程式的機制完全不同,C 程式之所以沒改變 a,是因為呼叫函式時只發生了值傳遞,即只把 a 的值複製給了 n。
不要混淆這兩種賦值邏輯,它們有著完全不同的物理實現方式。
不同的思維邏輯會導致不同的編寫邏輯。儘管這兩種邏輯在很多情況下的結果是一致的,但並不能就簡單地認為它們是一致的。否則在一些小的細節方面出了錯誤,就會難以理解。只能死記硬背,把一些東西當作 Python 的特例來記,雖然「唯手熟爾」也可以讓你走得很遠,但思維正確時,不僅可以走得更遠,也會走得更加輕鬆。
比如,當你的思維清晰時,以下問題的答案自然也就水落石出了:
- 為什麼列表的方法的返回值大多是
None? - 為什麼字串的方法的返回值大多是一個新的物件?
- 為什麼 Python 中沒有自增/自減運算子?
- 為什麼有的可變物件傳入函式之後,卻不能被函式修改“實參”的值?(比如將上面的
change函式的主體改成t = t[1:]。呼叫函式之後,a所指向的物件並沒有發生改變。) - ……
這些內容與本文主題不大相關,所以不再列出答案。
有趣的補充:
1. 數字是一個天然的不可變物件(immutable object)。 對於
n = n + 2,有人可能會說,為什麼不能把它看成像列表那樣的修改,修改後n依然指向的是原物件,這樣的話執行add(a)之後,a就會變成7了,可為什麼不是這樣?因為每一個數字都是一個單個的物件,而物件不能覆蓋物件。所以該句實際上是:a指向的物件加上物件2,產生了一個新的物件,然後令a指向了新物件a + 2。 因此,數字型別並不存在修改這一說,它是一個天然的不可變物件。2. 為什麼 Python 中沒有自增(++)、自減(--)運算子? 自增或自減運算子,在 C 語言中很常用,簡潔實用。但在 Python 中卻一定不會有。上節說到,數字是天然的不可變物件,所謂自增就是自身增加,所以它無法自增。它只能從一個物件指向下一個物件。可以這樣寫
a += 1。3. 既然 Python 更改的只是引用關係,那麼如何複製一個列表?a = [1, 2, 3] b = a # 這樣做不能複製一個列表,a 和 b 指向的都是列表 [1, 2, 3] # 答案: ## 1. 使用 list 的 copy 方法 b = a.copy() ## 2. 使用 slice 操作 b = a[:] # slice 操作返回一個新的物件
最後一章 回顧
本文的章節安排是基於便於講解的內容邏輯。這裡給出文章的思維邏輯,以便回顧:
- Python 與 C 語言的賦值邏輯差異
- 一個直接操縱資料,一個間接操縱資料
- 為什麼需要這種賦值邏輯
- 幫助實現物件之間的互動
- 物件不可被直接摧毀(覆蓋)
- 可以修改可變物件的值
- ……
- 為什麼想要物件之間進行互動(面向物件設計的內容)
- 幫助實現物件之間的互動
- 如何使用這種賦值邏輯
- 從左向右閱讀/編寫一個表示式
- 使用物件互動來設計、理解程式
- 為什麼可變物件可以更改“實參”,而不可變物件不可以
- 為什麼沒有自增/自減運算子
- 需要複製可變物件怎麼辦