
讀書筆記-Coordinated Deep Reinforcement Learners for Traffic Light Control
Coordinated Deep Reinforcement Learners for Traffic Light Control
本文研究了交通燈的學習控制策略。在交通燈控制問題引入了一種新的獎勵函式,並提出了將DQN演算法 與 傳輸規劃transfer planning相結合的多代理深度強化學習方法。通過使用傳輸規劃,它避免了之前多代理強化學習中存在的問題,並且允許更快和更可擴充套件的學習。它優於早期關於多代理交通燈控制的工作,但DQN演算法可能會發生振盪,需要進行更多的研究以防止DQN不穩定。
背景
將RL應用於交通燈控制的一個難題是選擇特徵:狀態的數量是巨大的,每個狀態描述交叉點周圍的確切情況。
我們對單交叉DQN方法【15】進行了修改,並研究了獎勵函式的有效表示式。 為了提高訓練過程的穩定性,我們測試了在交通控制背景下深度學習領域中一些最新技術的效果【22,5,17】。 此外,我們提出了使用這些技術來協調多交叉口的方法。
有兩種方法來穩定DQN演算法: 第一種是經驗重放【10,14】,其中取樣資料點 <s,a,r,s0> 儲存在儲存器memory中,並且在訓練時批量取樣這些資料點(或根據 TD-error,如優先經驗重放【17】)並用於反向傳播backpropagation。
第二種解決方案是 target network freezing【12】,其中Q-value估計被分成兩個不同的網路,一個用於估計當前狀態的Q(s,a)的值網路value network, 一個計算目標y 的目標網路target network 。
交通燈控制 - 深度強化學習DQN
STATE
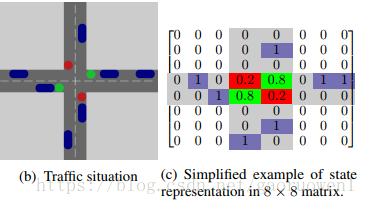
我們使用類似影象image-like的表示來表示交叉口周圍的狀態,如圖b示。 在之前的工作【15】中,由交通燈控制的車道上車輛位置的二元矩陣表示狀態,如圖c示。
因此,卷積神經網路應該能夠識別交通堵塞。
在當前模型中,交通燈顏色的表示使用數字來對映。
交通燈資訊將是狀態空間的額外層,每個交通燈顏色都具有二進位制特徵。
但是,這會隨著狀態空間的增加導致replay memory的記憶體問題,以及較慢的計算。
ACTION
在每個時間步,代理採取的動作在兩種不同的交通燈配置間進行選擇。代理選擇哪個車道獲得綠燈。
TRANSITION
從 到 的轉換由SUMO隱式定義,取決於和模擬中的汽車。
REWARD
為交通燈控制問題定義反饋訊號並不明確 一個好的指標是旨在減少行駛時間。然而,車輛的平均行駛時間在完成其路線之前無法計算,這導致獎勵極度延遲的問題。
因此,將標準進行不同權重的組合,迭代交叉口周圍的車輛。其中i是車輛索引,N是代理控制的車道上的車輛數量:
運輸懲罰 penalties for teleports j (表示SUMO中的車禍或擁堵)
緊急停止e(減速度超過 )
燈光配置是否已更改 c(布林變數,以防止閃爍flickering)
車輛的延誤 d=1 - (vehivle speed / allowed speed)
車輛的等待時間 w
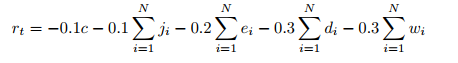
Learning stability
使用上述狀態描述和獎勵函式,我們研究了“未調整的DQN演算法”的效能。結果顯示如下,其顯示了在每10,000個時間步後的獎勵和平均旅行時間。
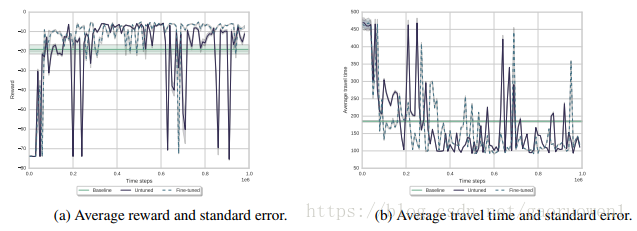
於是,測試了許多不同的引數設定,並使用了優先順序經驗重放機制。 除此之外還測試了Double DQN(DDQN)演算法在交通問題上的表現。但是DDQN似乎陷入區域性最小值。還嘗試使用批量標準化Batch Normalization【5】,發現批量標準化會導致分歧divergence。可見還需要更多的研究來解決在這些演算法中遇到的問題。
協作深度強化學習
通過利用 transfer planning【13】 和 ** max-plus coordination algorithm**【6】將單代理DQN擴充套件到多代理,並在不同的流量場景下評估該方法。
方法
為了在多個代理之間進行協調,我們遵循早期的工作【4,6】並將全域性Q函式定義為區域性問題的線性組合,其中e對應於鄰居代理的子集。
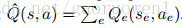
與前面提到的方法【4,6】相反,使用轉移計劃transfer planning【13】的變體找到函式Qe。
在transfer planning中,我們為一個多代理問題的子問題學習Q函式。如果源問題和其他子問題相似,那麼我們可以在較大的多代理問題中為每個子問題重用源問題的Q函式,而不是為每個單獨的子問題訓練Q函式。換句話說,與早期的工作【4,6】不同,transfer planning不會嘗試最小化Q的全域性近似誤差。
這種transfer planning方法避免了之前多代理強化學習中存在的兩個問題。第一個是多個代理同時學習和行動導致環境的不平穩性。通過對源問題進行訓練,環境動態在學習過程中不會發生變化。第二個是同時培訓許多代理的成本。因為源問題是獨立的,所以它們可以獨立地(例如順序地)解決。此外,我們利用源問題的對稱性,進一步降低了計算成本。
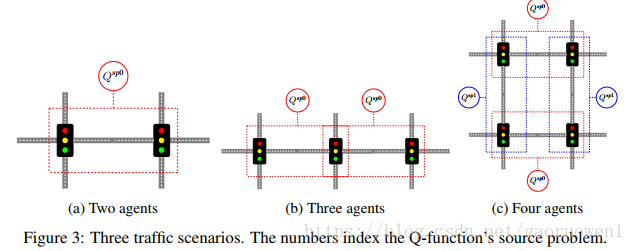
例如,在圖3a中的兩個代理源問題上訓練DQN代理以獲得Qsp0,並且使用旋轉版本來獲得Qsp1,然後使用transfer planning來解決圖3b和3c中的多代理問題。
作為對比實驗,使用早期演算法Wiering 【23】及多代理擴充套件Kuyer【8】。我們使用Wiering演算法來學習雙代理方案的策略,然後使用transfer planning和max-plus將他們組合以獲得類似於Kuyer的演算法。 結果顯示DQN方法在大多數情況下優於Wiering / Kuyer方法,但它由於不穩定性有時表現不佳。
[15] Tobias Rijken. DeepLight: Deep reinforcement learning for signalised traffic control, 2015.
[17] Tom Schaul, John Quan, Ioannis Antonoglou, and David Silver. Prioritized experience replay. ICLR 2016, 2016. [12] Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning. Nature, 518(7540):529–533, 2015. [5] Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167, 2015.
[22] Hado van Hasselt, Arthur Guez, and David Silver. Deep reinforcement learning with double Q-learning. CoRR, abs/1509.06461, 2015.
[4] Carlos Guestrin, Michail Lagoudakis, and Ronald Parr. Coordinated reinforcement learning. In ICML, volume 2, pages 227–234, 2002. [6] Jelle R Kok and Nikos Vlassis. Using the max-plus algorithm for multiagent decision making in coordination graphs. In Robot Soccer World Cup, pages 1–12. Springer, 2005.
[13] Frans A Oliehoek, Shimon Whiteson, and Matthijs TJ Spaan. Approximate solutions for factored Dec-POMDPs with many agents. In Proceedings of the 2013 international conference on Autonomous agents and multi-agent systems, pages 563–570. International Foundation for Autonomous Agents and Multiagent Systems, 2013.
[23] Marco Wiering et al. Multi-agent reinforcement learning for traffic light control. In ICML, 2000 [8] Lior Kuyer, Shimon Whiteson, Bram Bakker, and Nikos Vlassis. Multiagent reinforcement learning for urban traffic control using coordination graphs. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases, pages 656–671. Springer, 2008.