
Kafka 幾個重要的配置總結
注意:配置基於Kafka 0.8.2.1
broker配置
#非負整數,用於唯一標識broker
broker.id 0
#kafka持久化資料儲存的路徑,可以指定多個,以逗號分隔
log.dirs /tmp/kafka-logs
#broker接收連線請求的埠
port 9092
#指定zk連線字串,[hostname:port]以逗號分隔
zookeeper.connect
#單條訊息最大大小控制,消費端的最大拉取大小需要略大於該值
message.max.bytes 1000000
#接收網路請求的執行緒數
num.network.threads 3
#用於執行請求的I/O執行緒數
num.io.threads 8
#用於各種後臺處理任務(如檔案刪除)的執行緒數
background.threads 10
#待處理請求最大可緩衝的佇列大小
queued.max.requests 500
#配置該機器的IP地址
host.name
#預設分割槽個數
num.partitions 1
#分段檔案大小,超過後會輪轉
log.segment.bytes 1024 * 1024 * 1024
#日誌沒達到大小,如果達到這個時間也會輪轉
log.roll.{ms,hours} 168
#日誌保留時間
log.retention.{ms,minutes,hours}
#不存在topic的時候是否自動建立
auto.create.topics.enable true
#partition預設的備份因子
default.replication.factor 1
#如果這個時間內follower沒有發起fetch請求,被認為dead,從ISR移除
replica.lag.time.max.ms 10000
#如果follower相比leader落後這麼多以上訊息條數,會被從ISR移除
replica.lag.max.messages 4000
#從leader可以拉取的訊息最大大小
replica.fetch.max.bytes 1024 * 1024
#從leader拉取訊息的fetch執行緒數
num.replica.fetchers 1
#zk會話超時時間
zookeeper.session.timeout.ms 6000
#zk連線所用時間
zookeeper.connection.timeout.ms
#zk follower落後leader的時間
zookeeper.sync.time.ms 2000
#是否開啟topic可以被刪除的方式
delete.topic.enable false
producer配置
#參與訊息確認的broker數量控制,0代表不需要任何確認 1代表需要leader replica確認 -1代表需要ISR中所有進行確認
request.required.acks 0
#從傳送請求到收到ACK確認等待的最長時間(超時時間)
request.timeout.ms 10000
#設定訊息傳送模式,預設是同步方式, async非同步模式下允許訊息累計到一定量或一段時間又另外執行緒批量傳送,吞吐量好但丟失資料風險增大
producer.type sync
#訊息序列化類實現方式,預設是byte[]陣列形式
serializer.class kafka.serializer.DefaultEncoder
#kafka訊息分割槽策略實現方式,預設是對key進行hash
partitioner.class kafka.producer.DefaultPartitioner
#對傳送的訊息採取的壓縮編碼方式,有none|gzip|snappy
compression.codec none
#指定哪些topic的message需要壓縮
compressed.topics null
#訊息傳送失敗的情況下,重試傳送的次數 存在訊息傳送是成功的,只是由於網路導致ACK沒收到的重試,會出現訊息被重複傳送的情況
message.send.max.retries 3
#在開始重新發起metadata更新操作需要等待的時間
retry.backoff.ms 100
#metadata重新整理間隔時間,如果負值則失敗的時候才會重新整理,如果0則每次傳送後都重新整理,正值則是一種週期行為
topic.metadata.refresh.interval.ms 600 * 1000
#非同步傳送模式下,快取資料的最長時間,之後便會被髮送到broker
queue.buffering.max.ms 5000
#producer端非同步模式下最多快取的訊息條數
queue.buffering.max.messages 10000
#0代表隊列沒滿的時候直接入隊,滿了立即扔棄,-1代表無條件阻塞且不丟棄
queue.enqueue.timeout.ms -1
#一次批量傳送需要達到的訊息條數,當然如果queue.buffering.max.ms達到的時候也會被髮送
batch.num.messages 200
consumer配置
#指明當前消費程序所屬的消費組,一個partition只能被同一個消費組的一個消費者消費
group.id
#針對一個partition的fetch request所能拉取的最大訊息位元組數,必須大於等於Kafka執行的最大訊息
fetch.message.max.bytes 1024 * 1024
#是否自動週期性提交已經拉取到消費端的訊息offset
auto.commit.enable true
#自動提交offset到zookeeper的時間間隔
auto.commit.interval.ms 60 * 1000
#消費均衡的重試次數
rebalance.max.retries 4
#消費均衡兩次重試之間的時間間隔
rebalance.backoff.ms 2000
#當重新去獲取partition的leader前需要等待的時間
refresh.leader.backoff.ms 200
#如果zookeeper上沒有offset合理的初始值情況下獲取第一條訊息開始的策略smallest|largeset
auto.offset.reset largest
#如果其超時,將會可能觸發rebalance並認為已經死去
zookeeper.session.timeout.ms 6000
#確認zookeeper連線建立操作客戶端能等待的最長時間
zookeeper.connection.timeout.ms 6000
1.maven:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.10</artifactId>
<version>0.8.2.1</version>
</dependency>
2.kafka生產者程式碼:
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
/**
*
* @author FromX
*
*/
public class KProducer {
public static void main(String[] args) throws InterruptedException {
Properties props = new Properties();
//kafka伺服器地址
props.put("bootstrap.servers", "slave1.com:6667,slave2.com:6667,slave3.com:6667");
//ack是判斷請求是否為完整的條件(即判斷是否成功傳送)。all將會阻塞訊息,這種設定效能最低,但是最可靠。
props.put("acks", "1");
//retries,如果請求失敗,生產者會自動重試,我們指定是0次,如果啟用重試,則會有重複訊息的可能性。
props.put("retries", 0);
//producer快取每個分割槽未傳送訊息,快取的大小是通過batch.size()配置設定的。值較大的話將會產生更大的批。並需要更多的記憶體(因為每個“活躍”的分割槽都有一個緩衝區)
props.put("batch.size", 16384);
//預設緩衝區可立即傳送,即便緩衝區空間沒有滿;但是,如果你想減少請求的數量,可以設定linger.ms大於0.這將指示生產者傳送請求之前等待一段時間
//希望更多的訊息補填到未滿的批中。這類似於tcp的演算法,例如上面的程式碼段,可能100條訊息在一個請求傳送,因為我們設定了linger時間為1ms,然後,如果我們
//沒有填滿緩衝區,這個設定將增加1ms的延遲請求以等待更多的訊息。需要注意的是,在高負載下,相近的時間一般也會組成批,即使是linger.ms=0。
//不處於高負載的情況下,如果設定比0大,以少量的延遲代價換取更少的,更有效的請求。
props.put("linger.ms", 1);
//buffer.memory控制生產者可用的快取總量,如果訊息傳送速度比其傳輸到伺服器的快,將會耗盡這個快取空間。當快取空間耗盡,其他傳送呼叫將被阻塞,阻塞時間的閾值
//通過max.block.ms設定,之後他將丟擲一個TimeoutExecption。
props.put("buffer.memory", 33554432);
//key.serializer和value.serializer示例:將使用者提供的key和value物件ProducerRecord轉換成位元組,你可以使用附帶的ByteArraySerizlizaer或StringSerializer處理簡單的byte和String型別.
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//設定kafka的分割槽數量
props.put("kafka.partitions", 12);
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 50; i++){
System.out.println("key-->key"+i+" value-->vvv"+i);
producer.send(new ProducerRecord<String, String>("aaa", "key"+i, "vvv"+i));
Thread.sleep(1000);
}
producer.close();
}
}
3.kafka消費者程式碼:
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Arrays;
import java.util.Properties;
/**
*
* @author FromX
*
*/
public class KConsumer {
public KafkaConsumer<String, String> getConsmer() {
Properties props = new Properties();
//設定kafka伺服器
props.put("bootstrap.servers", "c1.wb3.com:6667,n1.wb1.com:6667");
//消費者群組ID,釋出-訂閱模式,即如果一個生產者,多個消費者都要消費,那麼需要定義自己的群組,同一個群組內的消費者只有一個能消費到訊息
props.put("group.id", "test");
//true,消費者的偏移量將在後臺定期提交;false關閉自動提交位移,在訊息被完整處理之後再手動提交位移
props.put("enable.auto.commit", "true");
//如何設定為自動提交(enable.auto.commit=true),這裡設定自動提交週期
props.put("auto.commit.interval.ms", "1000");
//session.timeout.ms:在使用kafka的組管理時,用於檢測消費者故障的超時
props.put("session.timeout.ms", "30000");
//key.serializer和value.serializer示例:將使用者提供的key和value物件ProducerRecord轉換成位元組,你可以使用附帶的ByteArraySerizlizaer或StringSerializer處理簡單的byte和String型別.
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
return consumer;
}
public static void main(String[] args) {
KConsumer kconsumer = new KConsumer();
KafkaConsumer<String, String> consumer = kconsumer.getConsmer();
consumer.subscribe(Arrays.asList("aaa"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.println("offset = "+record.offset()+", key = "+record.key()+", value = "+ record.value());
}
}
}
4.官網文件地址:http://kafka.apache.org/documentation.html#configuration
5.極限情況的資料丟失現象
a:即使將ack設定為"all"也會在一定情況下丟失訊息,因為kafka的高效能特性,訊息在寫入kafka時並沒有落盤而是寫入了OS buffer中,使用Os的髒頁重新整理策略週期性落盤,就算落盤 仍然會有raid buffer。前者機器宕機資料丟失,後者機器跳電資料丟失。
b:對資料可靠性比較高的場景建議offset手動提交,自動提交當遇到業務系統上線關閉時,訊息讀取並且offset已經提交,但是資料沒有儲存或者仍沒來得及消費時,訊息狀態在記憶體中無法保留,重啟應用會跳過訊息,致使訊息丟失。
---------------------
Kafka設計解析(八)- Kafka事務機制與Exactly Once語義實現原理
未分類
description: 本文介紹了Kafka實現事務性的幾個階段——正好一次語義與原子操作。之後詳細分析了Kafka事務機制的實現原理,並介紹了Kafka如何處理事務相關的異常情況,如Transaction Coordinator宕機。最後介紹了Kafka的事務機制與PostgreSQL的MVCC以及Zookeeper的原子廣播實現事務的異同
寫在前面的話
本文所有Kafka原理性的描述除特殊說明外均基於Kafka 1.0.0版本。
為什麼要提供事務機制
Kafka事務機制的實現主要是為了支援
Exactly Once即正好一次語義- 操作的原子性
- 有狀態操作的可恢復性
Exactly Once
《Kafka背景及架構介紹》一文中有說明Kafka在0.11.0.0之前的版本中只支援At Least Once和At Most Once語義,尚不支援Exactly Once語義。
但是在很多要求嚴格的場景下,如使用Kafka處理交易資料,Exactly Once語義是必須的。我們可以通過讓下游系統具有冪等性來配合Kafka的At Least Once語義來間接實現Exactly Once。但是:
- 該方案要求下游系統支援冪等操作,限制了Kafka的適用場景
- 實現門檻相對較高,需要使用者對Kafka的工作機制非常瞭解
- 對於Kafka Stream而言,Kafka本身即是自己的下游系統,但Kafka在0.11.0.0版本之前不具有冪等傳送能力
因此,Kafka本身對Exactly Once語義的支援就非常必要。
操作原子性
操作的原子性是指,多個操作要麼全部成功要麼全部失敗,不存在部分成功部分失敗的可能。
實現原子性操作的意義在於:
- 操作結果更可控,有助於提升資料一致性
- 便於故障恢復。因為操作是原子的,從故障中恢復時只需要重試該操作(如果原操作失敗)或者直接跳過該操作(如果原操作成功),而不需要記錄中間狀態,更不需要針對中間狀態作特殊處理
實現事務機制的幾個階段
冪等性發送
上文提到,實現Exactly Once的一種方法是讓下游系統具有冪等處理特性,而在Kafka Stream中,Kafka Producer本身就是“下游”系統,因此如果能讓Producer具有冪等處理特性,那就可以讓Kafka Stream在一定程度上支援Exactly once語義。
為了實現Producer的冪等語義,Kafka引入了Producer ID(即PID)和Sequence Number。每個新的Producer在初始化的時候會被分配一個唯一的PID,該PID對使用者完全透明而不會暴露給使用者。
對於每個PID,該Producer傳送資料的每個<Topic, Partition>都對應一個從0開始單調遞增的Sequence Number。
類似地,Broker端也會為每個<PID, Topic, Partition>維護一個序號,並且每次Commit一條訊息時將其對應序號遞增。對於接收的每條訊息,如果其序號比Broker維護的序號(即最後一次Commit的訊息的序號)大一,則Broker會接受它,否則將其丟棄:
- 如果訊息序號比Broker維護的序號大一以上,說明中間有資料尚未寫入,也即亂序,此時Broker拒絕該訊息,Producer丟擲
InvalidSequenceNumber - 如果訊息序號小於等於Broker維護的序號,說明該訊息已被儲存,即為重複訊息,Broker直接丟棄該訊息,Producer丟擲
DuplicateSequenceNumber
上述設計解決了0.11.0.0之前版本中的兩個問題:
- Broker儲存訊息後,傳送ACK前宕機,Producer認為訊息未傳送成功並重試,造成資料重複
- 前一條訊息傳送失敗,後一條訊息傳送成功,前一條訊息重試後成功,造成資料亂序
事務性保證
上述冪等設計只能保證單個Producer對於同一個<Topic, Partition>的Exactly Once語義。
另外,它並不能保證寫操作的原子性——即多個寫操作,要麼全部被Commit要麼全部不被Commit。
更不能保證多個讀寫操作的的原子性。尤其對於Kafka Stream應用而言,典型的操作即是從某個Topic消費資料,經過一系列轉換後寫回另一個Topic,保證從源Topic的讀取與向目標Topic的寫入的原子性有助於從故障中恢復。
事務保證可使得應用程式將生產資料和消費資料當作一個原子單元來處理,要麼全部成功,要麼全部失敗,即使該生產或消費跨多個<Topic, Partition>。
另外,有狀態的應用也可以保證重啟後從斷點處繼續處理,也即事務恢復。
為了實現這種效果,應用程式必須提供一個穩定的(重啟後不變)唯一的ID,也即Transaction ID。Transactin ID與PID可能一一對應。區別在於Transaction ID由使用者提供,而PID是內部的實現對使用者透明。
另外,為了保證新的Producer啟動後,舊的具有相同Transaction ID的Producer即失效,每次Producer通過Transaction ID拿到PID的同時,還會獲取一個單調遞增的epoch。由於舊的Producer的epoch比新Producer的epoch小,Kafka可以很容易識別出該Producer是老的Producer並拒絕其請求。
有了Transaction ID後,Kafka可保證:
- 跨Session的資料冪等傳送。當具有相同
Transaction ID的新的Producer例項被建立且工作時,舊的且擁有相同Transaction ID的Producer將不再工作。 - 跨Session的事務恢復。如果某個應用例項宕機,新的例項可以保證任何未完成的舊的事務要麼Commit要麼Abort,使得新例項從一個正常狀態開始工作。
需要注意的是,上述的事務保證是從Producer的角度去考慮的。從Consumer的角度來看,該保證會相對弱一些。尤其是不能保證所有被某事務Commit過的所有訊息都被一起消費,因為:
- 對於壓縮的Topic而言,同一事務的某些訊息可能被其它版本覆蓋
- 事務包含的訊息可能分佈在多個Segment中(即使在同一個Partition內),當老的Segment被刪除時,該事務的部分資料可能會丟失
- Consumer在一個事務內可能通過seek方法訪問任意Offset的訊息,從而可能丟失部分訊息
- Consumer可能並不需要消費某一事務內的所有Partition,因此它將永遠不會讀取組成該事務的所有訊息
事務機制原理
事務性訊息傳遞
這一節所說的事務主要指原子性,也即Producer將多條訊息作為一個事務批量傳送,要麼全部成功要麼全部失敗。
為了實現這一點,Kafka 0.11.0.0引入了一個伺服器端的模組,名為Transaction Coordinator,用於管理Producer傳送的訊息的事務性。
該Transaction Coordinator維護Transaction Log,該log存於一個內部的Topic內。由於Topic資料具有永續性,因此事務的狀態也具有永續性。
Producer並不直接讀寫Transaction Log,它與Transaction Coordinator通訊,然後由Transaction Coordinator將該事務的狀態插入相應的Transaction Log。
Transaction Log的設計與Offset Log用於儲存Consumer的Offset類似。
事務中Offset的提交
許多基於Kafka的應用,尤其是Kafka Stream應用中同時包含Consumer和Producer,前者負責從Kafka中獲取訊息,後者負責將處理完的資料寫回Kafka的其它Topic中。
為了實現該場景下的事務的原子性,Kafka需要保證對Consumer Offset的Commit與Producer對傳送訊息的Commit包含在同一個事務中。否則,如果在二者Commit中間發生異常,根據二者Commit的順序可能會造成資料丟失和資料重複:
- 如果先Commit Producer傳送資料的事務再Commit Consumer的Offset,即
At Least Once語義,可能造成資料重複。 - 如果先Commit Consumer的Offset,再Commit Producer資料傳送事務,即
At Most Once語義,可能造成資料丟失。
用於事務特性的控制型訊息
為了區分寫入Partition的訊息被Commit還是Abort,Kafka引入了一種特殊型別的訊息,即Control Message。該類訊息的Value內不包含任何應用相關的資料,並且不會暴露給應用程式。它只用於Broker與Client間的內部通訊。
對於Producer端事務,Kafka以Control Message的形式引入一系列的Transaction Marker。Consumer即可通過該標記判定對應的訊息被Commit了還是Abort了,然後結合該Consumer配置的隔離級別決定是否應該將該訊息返回給應用程式。
事務處理樣例程式碼
Producer<String, String> producer = new KafkaProducer<String, String>(props);// 初始化事務,包括結束該Transaction ID對應的未完成的事務(如果有)// 保證新的事務在一個正確的狀態下啟動producer.initTransactions();// 開始事務producer.beginTransaction();// 消費資料ConsumerRecords<String, String> records = consumer.poll(100);try{// 傳送資料producer.send(new ProducerRecord<String, String>("Topic", "Key", "Value"));// 傳送消費資料的Offset,將上述資料消費與資料傳送納入同一個Transaction內producer.sendOffsetsToTransaction(offsets, "group1");// 資料傳送及Offset傳送均成功的情況下,提交事務producer.commitTransaction();} catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {// 資料傳送或者Offset傳送出現異常時,終止事務producer.abortTransaction();} finally {// 關閉Producer和Consumerproducer.close();consumer.close();}
完整事務過程
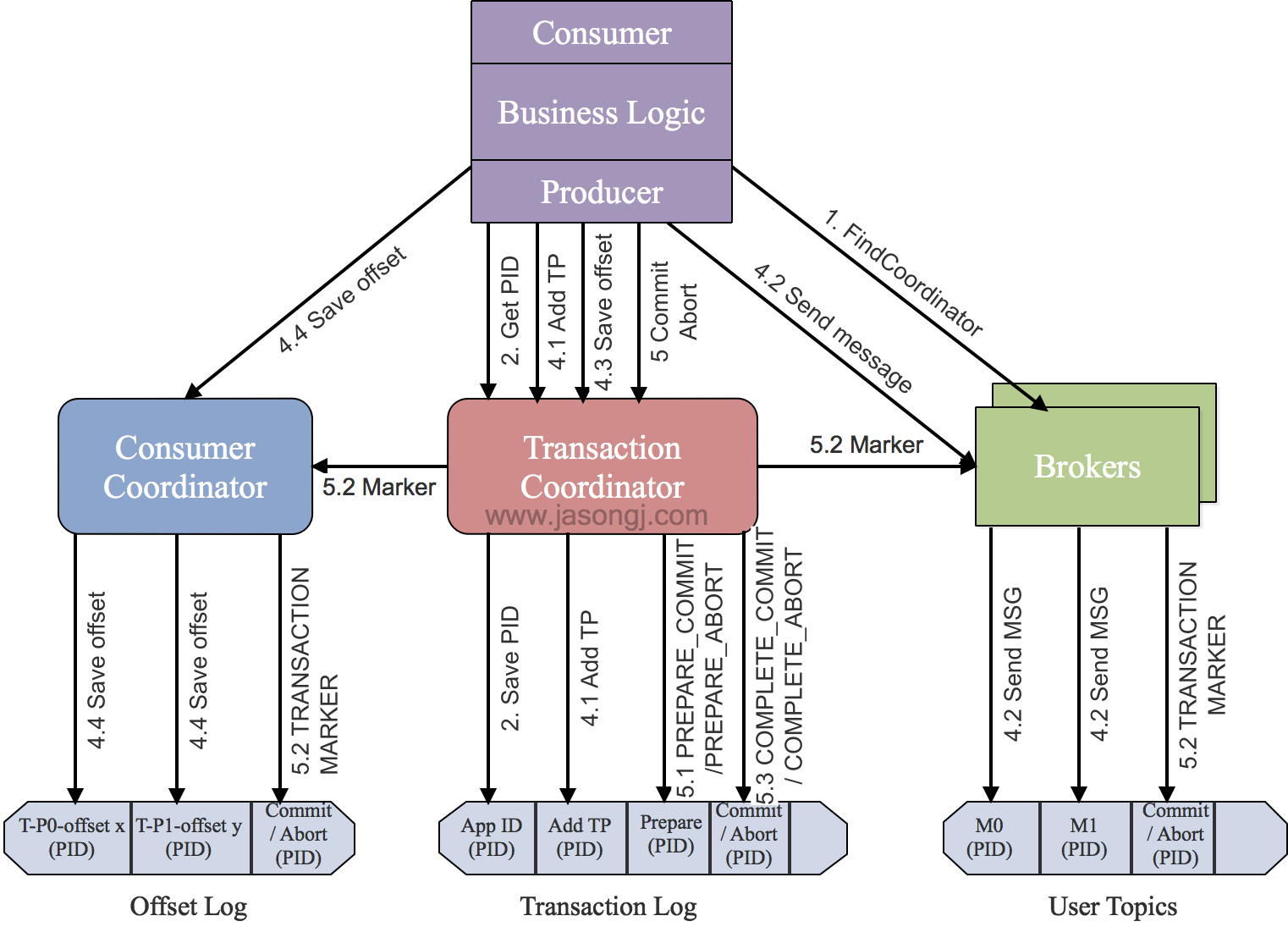
找到Transaction Coordinator
由於Transaction Coordinator是分配PID和管理事務的核心,因此Producer要做的第一件事情就是通過向任意一個Broker傳送FindCoordinator請求找到Transaction Coordinator的位置。
注意:只有應用程式為Producer配置了Transaction ID時才可使用事務特性,也才需要這一步。另外,由於事務性要求Producer開啟冪等特性,因此通過將transactional.id設定為非空從而開啟事務特性的同時也需要通過將enable.idempotence設定為true來開啟冪等特性。
獲取PID
找到Transaction Coordinator後,具有冪等特性的Producer必須發起InitPidRequest請求以獲取PID。
注意:只要開啟了冪等特性即必須執行該操作,而無須考慮該Producer是否開啟了事務特性。
* 如果事務特性被開啟 *
InitPidRequest會發送給Transaction Coordinator。如果Transaction Coordinator是第一次收到包含有該Transaction ID的InitPidRequest請求,它將會把該<TransactionID, PID>存入Transaction Log,如上圖中步驟2.1所示。這樣可保證該對應關係被持久化,從而保證即使Transaction Coordinator宕機該對應關係也不會丟失。
除了返回PID外,InitPidRequest還會執行如下任務:
- 增加該PID對應的epoch。具有相同PID但epoch小於該epoch的其它Producer(如果有)新開啟的事務將被拒絕。
- 恢復(Commit或Abort)之前的Producer未完成的事務(如果有)。
注意:InitPidRequest的處理過程是同步阻塞的。一旦該呼叫正確返回,Producer即可開始新的事務。
另外,如果事務特性未開啟,InitPidRequest可傳送至任意Broker,並且會得到一個全新的唯一的PID。該Producer將只能使用冪等特性以及單一Session內的事務特性,而不能使用跨Session的事務特性。
開啟事務
Kafka從0.11.0.0版本開始,提供beginTransaction()方法用於開啟一個事務。呼叫該方法後,Producer本地會記錄已經開啟了事務,但Transaction Coordinator只有在Producer傳送第一條訊息後才認為事務已經開啟。
Consume-Transform-Produce
這一階段,包含了整個事務的資料處理過程,並且包含了多種請求。
AddPartitionsToTxnRequest
一個Producer可能會給多個<Topic, Partition>傳送資料,給一個新的<Topic, Partition>傳送資料前,它需要先向Transaction Coordinator傳送AddPartitionsToTxnRequest。
Transaction Coordinator會將該<Transaction, Topic, Partition>存於Transaction Log內,並將其狀態置為BEGIN,如上圖中步驟4.1所示。有了該資訊後,我們才可以在後續步驟中為每個Topic, Partition>設定COMMIT或者ABORT標記(如上圖中步驟5.2所示)。
另外,如果該<Topic, Partition>為該事務中第一個<Topic, Partition>,Transaction Coordinator還會啟動對該事務的計時(每個事務都有自己的超時時間)。
ProduceRequest
Producer通過一個或多個ProduceRequest傳送一系列訊息。除了應用資料外,該請求還包含了PID,epoch,和Sequence Number。該過程如上圖中步驟4.2所示。
AddOffsetsToTxnRequest
為了提供事務性,Producer新增了sendOffsetsToTransaction方法,該方法將多組訊息的傳送和消費放入同一批處理內。
該方法先判斷在當前事務中該方法是否已經被呼叫並傳入了相同的Group ID。若是,直接跳到下一步;若不是,則向Transaction Coordinator傳送AddOffsetsToTxnRequests請求,Transaction Coordinator將對應的所有<Topic, Partition>存於Transaction Log中,並將其狀態記為BEGIN,如上圖中步驟4.3所示。該方法會阻塞直到收到響應。
TxnOffsetCommitRequest
作為sendOffsetsToTransaction方法的一部分,在處理完AddOffsetsToTxnRequest後,Producer也會發送TxnOffsetCommit請求給Consumer Coordinator從而將本事務包含的與讀操作相關的各<Topic, Partition>的Offset持久化到內部的__consumer_offsets中,如上圖步驟4.4所示。
在此過程中,Consumer Coordinator會通過PID和對應的epoch來驗證是否應該允許該Producer的該請求。
這裡需要注意:
- 寫入
__consumer_offsets的Offset資訊在當前事務Commit前對外是不可見的。也即在當前事務被Commit前,可認為該Offset尚未Commit,也即對應的訊息尚未被完成處理。 Consumer Coordinator並不會立即更新快取中相應<Topic, Partition>的Offset,因為此時這些更新操作尚未被COMMIT或ABORT。
Commit或Abort事務
一旦上述資料寫入操作完成,應用程式必須呼叫KafkaProducer的commitTransaction方法或者abortTransaction方法以結束當前事務。
EndTxnRequest
commitTransaction方法使得Producer寫入的資料對下游Consumer可見。abortTransaction方法通過Transaction Marker將Producer寫入的資料標記為Aborted狀態。下游的Consumer如果將isolation.level設定為READ_COMMITTED,則它讀到被Abort的訊息後直接將其丟棄而不會返回給客戶程式,也即被Abort的訊息對應用程式不可見。
無論是Commit還是Abort,Producer都會發送EndTxnRequest請求給Transaction Coordinator,並通過標誌位標識是應該Commit還是Abort。
收到該請求後,Transaction Coordinator會進行如下操作
- 將
PREPARE_COMMIT或PREPARE_ABORT訊息寫入Transaction Log,如上圖中步驟5.1所示 - 通過
WriteTxnMarker請求以Transaction Marker的形式將COMMIT或ABORT資訊寫入使用者資料日誌以及Offset Log中,如上圖中步驟5.2所示 - 最後將
COMPLETE_COMMIT或COMPLETE_ABORT資訊寫入Transaction Log中,如上圖中步驟5.3所示
補充說明:對於commitTransaction方法,它會在傳送EndTxnRequest之前先呼叫flush方法以確保所有傳送出去的資料都得到相應的ACK。對於abortTransaction方法,在傳送EndTxnRequest之前直接將當前Buffer中的事務性訊息(如果有)全部丟棄,但必須等待所有被髮送但尚未收到ACK的訊息傳送完成。
上述第二步是實現將一組讀操作與寫操作作為一個事務處理的關鍵。因為Producer寫入的資料Topic以及記錄Comsumer Offset的Topic會被寫入相同的Transactin Marker,所以這一組讀操作與寫操作要麼全部COMMIT要麼全部ABORT。
WriteTxnMarkerRequest
上面提到的WriteTxnMarkerRequest由Transaction Coordinator傳送給當前事務涉及到的每個<Topic, Partition>的Leader。收到該請求後,對應的Leader會將對應的COMMIT(PID)或者ABORT(PID)控制資訊寫入日誌,如上圖中步驟5.2所示。
該控制訊息向Broker以及Consumer表明對應PID的訊息被Commit了還是被Abort了。
這裡要注意,如果事務也涉及到__consumer_offsets,即該事務中有消費資料的操作且將該消費的Offset存於__consumer_offsets中,Transaction Coordinator也需要向該內部Topic的各Partition的Leader傳送WriteTxnMarkerRequest從而寫入COMMIT(PID)或COMMIT(PID)控制資訊。
寫入最終的COMPLETE_COMMIT或COMPLETE_ABORT訊息
寫完所有的Transaction Marker後,Transaction Coordinator會將最終的COMPLETE_COMMIT或COMPLETE_ABORT訊息寫入Transaction Log中以標明該事務結束,如上圖中步驟5.3所示。
此時,Transaction Log中所有關於該事務的訊息全部可以移除。當然,由於Kafka內資料是Append Only的,不可直接更新和刪除,這裡說的移除只是將其標記為null從而在Log Compact時不再保留。
另外,COMPLETE_COMMIT或COMPLETE_ABORT的寫入並不需要得到所有Rreplica的ACK,因為如果該訊息丟失,可以根據事務協議重發。
補充說明,如果參與該事務的某些<Topic, Partition>在被寫入Transaction Marker前不可用,它對READ_COMMITTED的Consumer不可見,但不影響其它可用<Topic, Partition>的COMMIT或ABORT。在該<Topic, Partition>恢復可用後,Transaction Coordinator會重新根據PREPARE_COMMIT或PREPARE_ABORT向該<Topic, Partition>傳送Transaction Marker。
總結
PID與Sequence Number的引入實現了寫操作的冪等性- 寫操作的冪等性結合
At Least Once語義實現了單一Session內的Exactly Once語義 Transaction Marker與PID提供了識別訊息是否應該被讀取的能力,從而實現了事務的隔離性- Offset的更新標記了訊息是否被讀取,從而將對讀操作的事務處理轉換成了對寫(Offset)操作的事務處理
- Kafka事務的本質是,將一組寫操作(如果有)對應的訊息與一組讀操作(如果有)對應的Offset的更新進行同樣的標記(即
Transaction Marker)來實現事務中涉及的所有讀寫操作同時對外可見或同時對外不可見 - Kafka只提供對Kafka本身的讀寫操作的事務性,不提供包含外部系統的事務性
異常處理
Exception處理
InvalidProducerEpoch
這是一種Fatal Error,它說明當前Producer是一個過期的例項,有Transaction ID相同但epoch更新的Producer例項被建立並使用。此時Producer會停止並丟擲Exception。
InvalidPidMapping
Transaction Coordinator沒有與該Transaction ID對應的PID。此時Producer會通過包含有Transaction ID的InitPidRequest請求建立一個新的PID。
NotCorrdinatorForGTransactionalId
該Transaction Coordinator不負責該當前事務。Producer會通過FindCoordinatorRequest請求重新尋找對應的Transaction Coordinator。
InvalidTxnRequest
違反了事務協議。正確的Client實現不應該出現這種Exception。如果該異常發生了,使用者需要檢查自己的客戶端實現是否有問題。
CoordinatorNotAvailable
Transaction Coordinator仍在初始化中。Producer只需要重試即可。
DuplicateSequenceNumber
傳送的訊息的序號低於Broker預期。該異常說明該訊息已經被成功處理過,Producer可以直接忽略該異常並處理下一條訊息
InvalidSequenceNumber
這是一個Fatal Error,它說明發送的訊息中的序號大於Broker預期。此時有兩種可能
- 資料亂序。比如前面的訊息傳送失敗後重試期間,新的訊息被接收。正常情況下不應該出現該問題,因為當冪等傳送啟用時,
max.inflight.requests.per.connection被強制設定為1,而acks被強制設定為all。故前面訊息重試期間,後續訊息不會被髮送,也即不會發生亂序。並且只有ISR中所有Replica都ACK,Producer才會認為訊息已經被髮送,也即不存在Broker端資料丟失問題。 - 伺服器由於日誌被Truncate而造成資料丟失。此時應該停止Producer並將此Fatal Error報告給使用者。
InvalidTransactionTimeout
InitPidRequest調用出現的Fatal Error。它表明Producer傳入的timeout時間不在可接受範圍內,應該停止Producer並報告給使用者。
處理Transaction Coordinator失敗
寫PREPARE_COMMIT/PREPARE_ABORT前失敗
Producer通過FindCoordinatorRequest找到新的Transaction Coordinator,並通過EndTxnRequest請求發起COMMIT或ABORT流程,新的Transaction Coordinator繼續處理EndTxnRequest請求——寫PREPARE_COMMIT或PREPARE_ABORT,寫Transaction Marker,寫COMPLETE_COMMIT或COMPLETE_ABORT。
寫完PREPARE_COMMIT/PREPARE_ABORT後失敗
此時舊的Transaction Coordinator可能已經成功寫入部分Transaction Marker。新的Transaction Coordinator會重複這些操作,所以部分Partition中可能會存在重複的COMMIT或ABORT,但只要該Producer在此期間沒有發起新的事務,這些重複的Transaction Marker就不是問題。
寫完COMPLETE_COMMIT/ABORT後失敗
舊的Transaction Coordinator可能已經寫完了COMPLETE_COMMIT或COMPLETE_ABORT但在返回EndTxnRequest之前失敗。該場景下,新的Transaction Coordinator會直接給Producer返回成功。
事務過期機制
事務超時
transaction.timeout.ms
終止過期事務
當Producer失敗時,Transaction Coordinator必須能夠主動的讓某些進行中的事務過期。否則沒有Producer的參與,Transaction Coordinator無法判斷這些事務應該如何處理,這會造成:
- 如果這種進行中事務太多,會造成
Transaction Coordinator需要維護大量的事務狀態,大量佔用記憶體 Transaction Log內也會存在大量資料,造成新的Transaction Coordinator啟動緩慢READ_COMMITTED的Consumer需要快取大量的訊息,造成不必要的記憶體浪費甚至是OOM- 如果多個
Transaction ID不同的Producer交叉寫同一個Partition,當一個Producer的事務狀態不更新時,READ_COMMITTED的Consumer為了保證順序消費而被阻塞
為了避免上述問題,Transaction Coordinator會週期性遍歷記憶體中的事務狀態Map,並執行如下操作
- 如果狀態是
BEGIN並且其最後更新時間與當前時間差大於transaction.remove.expired.transaction.cleanup.interval.ms(預設值為1小時),則主動將其終止:1)未避免原Producer臨時恢復與當前終止流程衝突,增加該Producer對應的PID的epoch,並確保將該更新的資訊寫入Transaction Log;2)以更新後的epoch回滾事務,從而使得該事務相關的所有Broker都更新其快取的該PID的epoch從而拒絕舊Producer的寫操作 - 如果狀態是
PREPARE_COMMIT,完成後續的COMMIT流程————向各<Topic, Partition>寫入Transaction Marker,在Transaction Log內寫入COMPLETE_COMMIT - 如果狀態是
PREPARE_ABORT,完成後續ABORT流程
終止Transaction ID
某Transaction ID的Producer可能很長時間不再發送資料,Transaction Coordinator沒必要再儲存該Transaction ID與PID等的對映,否則可能會造成大量的資源浪費。因此需要有一個機制探測不再活躍的Transaction ID並將其資訊刪除。
Transaction Coordinator會週期性遍歷記憶體中的Transaction ID與PID對映,如果某Transaction ID沒有對應的正在進行中的事務並且它對應的最後一個事務的結束時間與當前時間差大於transactional.id.expiration.ms(預設值是7天),則將其從記憶體中刪除並在Transaction Log中將其對應的日誌的值設定為null從而使得Log Compact可將其記錄刪除。
與其它系統事務機制對比
PostgreSQL MVCC
Kafka的事務機制與《MVCC PostgreSQL實現事務和多版本併發控制的精華》一文中介紹的PostgreSQL通過MVCC實現事務的機制非常類似,對於事務的回滾,並不需要刪除已寫入的資料,都是將寫入資料的事務標記為Rollback/Abort從而在讀資料時過濾該資料。
兩階段提交
Kafka的事務機制與《分散式事務(一)兩階段提交及JTA》一文中所介紹的兩階段提交機制看似相似,都分PREPARE階段和最終COMMIT階段,但又有很大不同。
- Kafka事務機制中,PREPARE時即要指明是
PREPARE_COMMIT還是PREPARE_ABORT,並且只須在Transaction Log中標記即可,無須其它元件參與。而兩階段提交的PREPARE需要傳送給所有的分散式事務參與方,並且事務參與方需要儘可能準備好,並根據準備情況返回Prepared或Non-Prepared狀態給事務管理器。 - Kafka事務中,一但發起
PREPARE_COMMIT或PREPARE_ABORT,則確定該事務最終的結果應該是被COMMIT或ABORT。而分散式事務中,PREPARE後由各事務參與方返回狀態,只有所有參與方均返回Prepared狀態才會真正執行COMMIT,否則執行ROLLBACK - Kafka事務機制中,某幾個Partition在COMMIT或ABORT過程中變為不可用,隻影響該Partition不影響其它Partition。兩階段提交中,若唯一收到COMMIT命令參與者Crash,其它事務參與方無法判斷事務狀態從而使得整個事務阻塞
- Kafka事務機制引入事務超時機制,有效避免了掛起的事務影響其它事務的問題
- Kafka事務機制中存在多個
Transaction Coordinator例項,而分散式事務中只有一個事務管理器
Zookeeper
Zookeeper的原子廣播協議與兩階段提交以及Kafka事務機制有相似之處,但又有各自的特點
- Kafka事務可COMMIT也可ABORT。而Zookeeper原子廣播協議只有COMMIT沒有ABORT。當然,Zookeeper不COMMIT某訊息也即等效於ABORT該訊息的更新。
- Kafka存在多個
Transaction Coordinator例項,擴充套件性較好。而Zookeeper寫操作只能在Leader節點進行,所以其寫效能遠低於讀效能。 - Kafka事務是COMMIT還是ABORT完全取決於Producer即客戶端。而Zookeeper原子廣播協議中某條訊息是否被COMMIT取決於是否有一大半FOLLOWER ACK該訊息。