
redis的五種資料結構原理分析
本章主要內容
- 簡單介紹redis
- redis中的五種資料結構分析
- 應用場景分析
- 總結
關於Redis
redis是一個開源的使用C語言編寫的一個kv儲存系統,是一個速度非常快的非關係遠端記憶體資料庫。它支援包括String、List、Set、Zset、hash五種資料結構。除此之外,通過複製、持久化和客戶端分片等特性,使用者可以很方便地將redis擴充套件成一個能夠包含數百GB資料和每秒處理上百萬次的請求的系統。目前支援多種語言的api,方便使用者使用。
redis同時也內建了事務、LUA指令碼、複製等功能,提供兩種持久化選項,一種是每隔一段時間將資料匯入到磁碟(快照模式),另一種是追加命令到日誌中(AOF模式)。如果只是作為高效的記憶體資料庫使用也可以關閉持久化功能。通過哨兵(sentinel)和自動分割槽(Cuuster)的方式可以提高redis伺服器的高可用性。
與關係型資料庫相比,redis的命令請求不需要經過查詢分析器或查詢優化器進行處理,也避免了更新資料時引起的隨機讀\寫,這些慢操作。它直接讀寫記憶體中的資料,並且資料是按照一定的資料結構儲存的。所以它的速度非常快。
五種資料結構
字串(String)
與其它程式語言或其它鍵值儲存提供的字串非常相似,鍵(key)------值(value) (字串格式),字串擁有一些操作命令,如:get set del 還有一些比如自增或自減操作等等。redis是使用C語言開發,但C中並沒有字串型別,只能使用指標或符陣列的形式表示一個字串,所以redis設計了一種簡單動態字串(SDS[Simple Dynamic String])作為底實現:
定義SDS物件,此物件中包含三個屬性:
- len buf中已經佔有的長度(表示此字串的實際長度)
- free buf中未使用的緩衝區長度
- buf[] 實際儲存字串資料的地方
所以取字串的長度的時間複雜度為O(1),另,buf[]中依然採用了C語言的以\0結尾可以直接使用C語言的部分標準C字串庫函式。
空間分配原則:當len小於IMB(1024*1024)時增加字串分配空間大小為原來的2倍,當len大於等於1M時每次分配 額外多分配1M的空間。
由此可以得出以下特性:
- redis為字元分配空間的次數是小於等於字串的長度N,而原C語言中的分配原則必為N。降低了分配次數提高了追加速度,代價就是多佔用一些記憶體空間,且這些空間不會自動釋放。
- 二進位制安全的
- 高效的計算字串長度(時間複雜度為O(1))
- 高效的追加字串操作。
列表(List)
redis對鍵表的結構支援使得它在鍵值儲存的世界中獨樹一幟,一個列表結構可以有序地儲存多個字串,擁有例如:lpush lpop rpush rpop等等操作命令。在3.2版本之前,列表是使用ziplist和linkedlist實現的,在這些老版本中,當列表物件同時滿足以下兩個條件時,列表物件使用ziplist編碼:
- 列表物件儲存的所有字串元素的長度都小於64位元組
- 列表物件儲存的元素數量小於512個
當有任一條件 不滿足時將會進行一次轉碼,使用linkedlist。
而在3.2版本之後,重新引入了一個quicklist的資料結構,列表的底層都是由quicklist實現的,它結合了ziplist和linkedlist的優點。按照原文的解釋這種資料結構是【A doubly linked list of ziplists】意思就是一個由ziplist組成的雙向連結串列。那麼這兩種資料結構怎麼樣結合的呢?
ziplist的結構
由表頭和N個entry節點和壓縮列表尾部識別符號zlend組成的一個連續的記憶體塊。然後通過一系列的編碼規則,提高記憶體的利用率,主要用於儲存整數和比較短的字串。可以看出在插入和刪除元素的時候,都需要對記憶體進行一次擴充套件或縮減,還要進行部分資料的移動操作,這樣會造成更新效率低下的情況。
這篇文章對ziplist的結構講的還是比較詳細的:
https://blog.csdn.net/yellowriver007/article/details/79021049
linkedlist的結構
意思為一個雙向連結串列,和普通的連結串列定義相同,每個entry包含向前向後的指標,當插入或刪除元素的時候,只需要對此元素前後指標操作即可。所以插入和刪除效率很高。但查詢的效率卻是O(n)[n為元素的個數]。
瞭解了上面的這兩種資料結構,我們再來看看上面說的“ziplist組成的雙向連結串列”是什麼意思?實際上,它整體巨集觀上就是一個連結串列結構,只不過每個節點都是以壓縮列表ziplist的結構儲存著資料,而每個ziplist又可以包含多個entry。也可以說一個quicklist節點儲存的是一片資料,而不是一個數據。總結:
- 整體上quicklist就是一個雙向連結串列結構,和普通的連結串列操作一樣,插入刪除效率很高,但查詢的效率卻是O(n)。不過,這樣的連結串列訪問兩端的元素的時間複雜度卻是O(1)。所以,對list的操作多數都是poll和push。
- 每個quicklist節點就是一個ziplist,具備壓縮列表的特性。
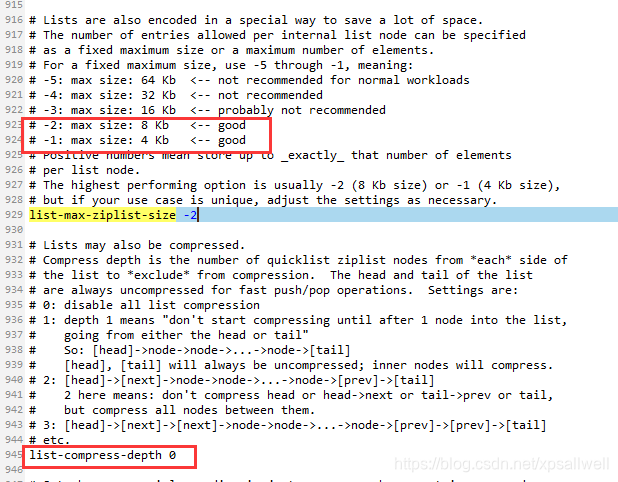
在redis.conf配置檔案中,有兩個引數可以優化列表:
- list-max-ziplist-size 表示每個quicklistNode的位元組大小。預設為-2 表示8KB
- list-compress-depth 表示quicklistNode節點是否要壓縮。預設是0 表示不壓縮
雜湊(hash)
redis的雜湊可以儲存多個鍵 值 對之間的對映,雜湊儲存的值既可以是字串又可以是數字值,並且使用者同樣可以對雜湊儲存的數字值執行自增操作或者自減操作。雜湊可以看作是一個文件或關係資料庫裡的一行。hash底層的資料結構實現有兩種:
- 一種是ziplist,上面已經提到過。當儲存的資料超過配置的閥值時就是轉用hashtable的結構。這種轉換比較消耗效能,所以應該儘量避免這種轉換操作。同時滿足以下兩個條件時才會使用這種結構:
- 當鍵的個數小於hash-max-ziplist-entries(預設512)
- 當所有值都小於hash-max-ziplist-value(預設64)
- 另一種就是hashtable。這種結構的時間複雜度為O(1),但是會消耗比較多的記憶體空間。
集合(Set)
redis的集合和列表都可以儲存多個字串,它們之間的不同在於,列表可以儲存多個相同的字串,而集合則通過使用散列表(hashtable)來保證自已儲存的每個字串都是各不相同的(這些散列表只有鍵,但沒有與鍵相關聯的值),redis中的集合是無序的。還可能存在另一種集合,那就是intset,它是用於儲存整數的有序集合,裡面存放同一型別的整數。共有三種整數:int16_t、int32_t、int64_t。查詢的時間複雜度為O(logN),但是插入的時候,有可能會涉及到升級(比如:原來是int16_t的集合,當插入int32_t的整數的時候就會為每個元素升級為int32_t)這時候會對記憶體重新分配,所以此時的時間複雜度就是O(N)級別的了。注意:intset只支援升級不支援降級操作。
intset在redis.conf中也有一個配置引數set-max-intset-entries預設值為512。表示如果entry的個數小於此值,則可以編碼成REDIS_ENCODING_INTSET型別儲存,節約記憶體。否則採用dict的形式儲存。
有序集合(zset)
有序集合和雜湊一樣,都用於儲存鍵值對:有序集合的鍵被稱為成員(member),每個成員都是各不相同的。有序集合的值則被稱為分值(score),分值必須為浮點數。有序集合是redis裡面唯一一個既可以根據成員訪問元素(這一點和雜湊一樣),又可以根據分值以及分值的排列順序訪問元素的結構。它的儲存方式也有兩種:
- 是ziplist結構。
與上面的hash中的ziplist類似,member和score順序存放並按score的順序排列
- 另一種是skiplist與dict的結合。
skiplist是一種跳躍表結構,用於有序集合中快速查詢,大多數情況下它的效率與平衡樹差不多,但比平衡樹實現簡單。redis的作者對普通的跳躍表進行了修改,包括新增span\tail\backward指標、score的值可重複這些設計,從而實現排序功能和反向遍歷的功能。
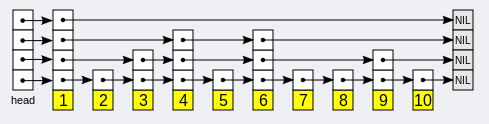
一般跳躍表的實現,主要包含以下幾個部分:
- 表頭(head):指向頭節點
- 表尾(tail):指向尾節點
- 節點(node):實際儲存的元素節點,每個節點可以有多層,層數是在建立此節點的時候隨機生成的一個數值,而且每一層都是一個指向後面某個節點的指標。
- 層(level):目前表內節點的最大層數
- 長度(length):節點的數量。
跳躍表的遍歷總是從高層開始,然後隨著元素值範圍的縮小,慢慢降低到低層。
跳躍表的實現原理可以參考:https://blog.csdn.net/Acceptedxukai/article/details/17333673
前面也說了,有序列表是使用skiplist和dict結合實現的,skiplist用來保障有序性和訪問查詢效能,dict就用來儲存元素資訊,並且dict的訪問時間複雜度為O(1)。
應用場景
redis一般應用場景
- 快取會話(單點登入)
- 分散式鎖,比如:使用setnx
- 各種排行榜或計數器
- 商品列表或使用者基礎資料列表等
- 使用list作為訊息對列
- 秒殺,庫存扣減等
五種型別的應用場景
- String,redis對於KV的操作效率很高,可以直接用作計數器。例如,統計線上人數等等,另外string型別是二進位制儲存安全的,所以也可以使用它來儲存圖片,甚至是視訊等。
- hash,存放鍵值對,一般可以用來存某個物件的基本屬性資訊,例如,使用者資訊,商品資訊等,另外,由於hash的大小在小於配置的大小的時候使用的是ziplist結構,比較節約記憶體,所以針對大量的資料儲存可以考慮使用hash來分段儲存來達到壓縮資料量,節約記憶體的目的,例如,對於大批量的商品對應的圖片地址名稱。比如:商品編碼固定是10位,可以選取前7位做為hash的key,後三位作為field,圖片地址作為value。這樣每個hash表都不超過999個,只要把redis.conf中的hash-max-ziplist-entries改為1024,即可。
- list,列表型別,可以用於實現訊息佇列,也可以使用它提供的range命令,做分頁查詢功能。
- set,集合,整數的有序列表可以直接使用set。可以用作某些去重功能,例如使用者名稱不能重複等,另外,還可以對集合進行交集,並集操作,來查詢某些元素的共同點
- zset,有序集合,可以使用範圍查詢,排行榜功能或者topN功能。
總結
本章介紹了redis的五種資料結構和它們使用的底層儲存原理,為了達到節省記憶體和快速訪問的目的每種資料結構可能有兩種儲存和訪問結構,在必要的時候會由一種結構轉換成另一種結構,但這個轉換的過程會消耗系統性能和記憶體空間的,所以在使用的過程中需要注意這些配置引數,開發中儘量避免達到這些峰值,使得redis能夠持續的提供高效的服務。