
python爬取小視訊——梨視訊
阿新 • • 發佈:2018-12-13
爬取梨視訊小視訊 網址:http://www.pearvideo.com/ 工具:python3,pycharm,火狐瀏覽器(或谷歌瀏覽器) 模組:requests,re,os, urllib.request,(如需控制爬取速度,可加入time模組。)
思路:
- 分析網站
- 獲取網頁原始碼
- 獲取視訊ID
- 拼接URL地址
- 獲取視訊播放地址
- 下載視訊
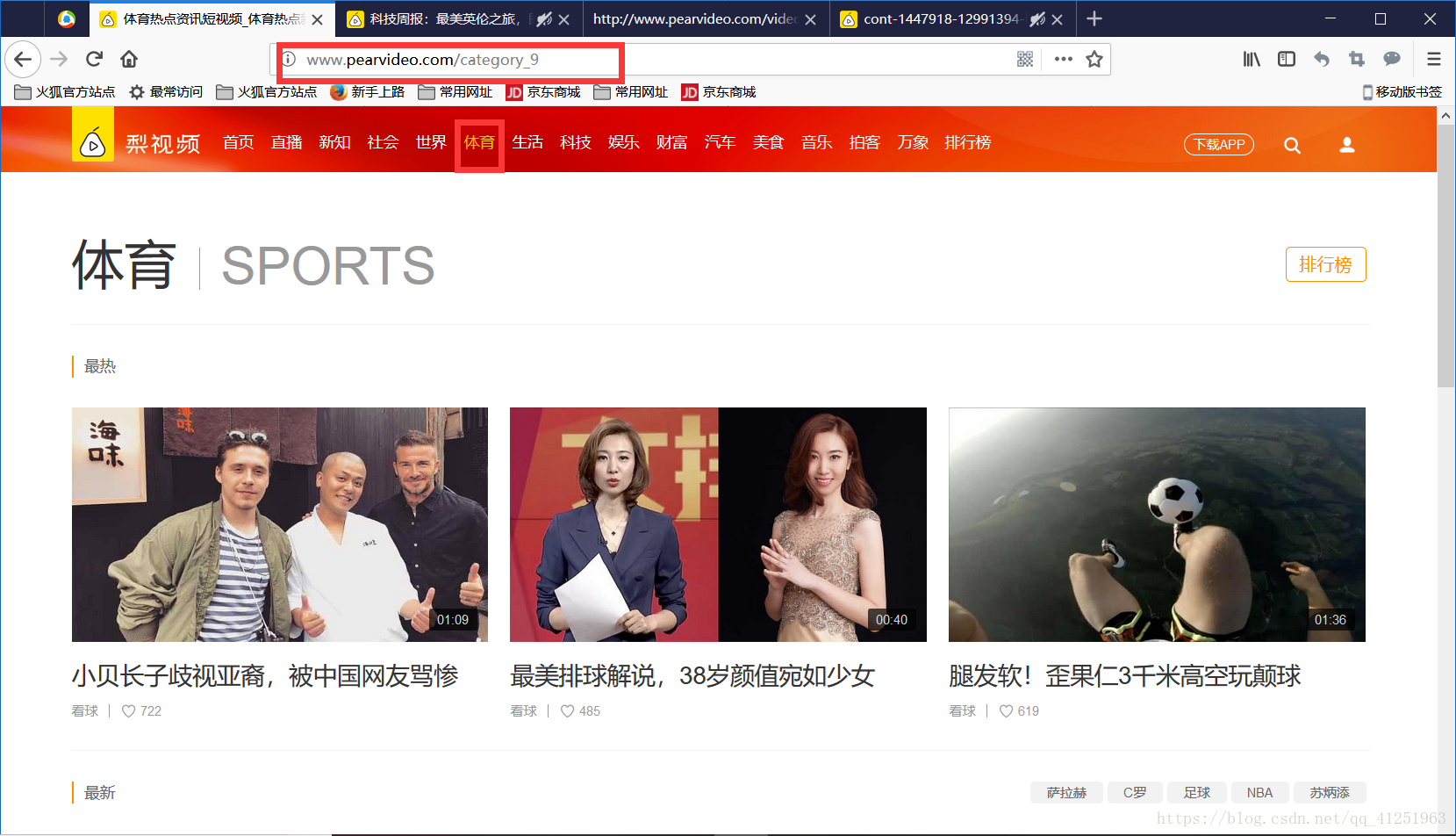
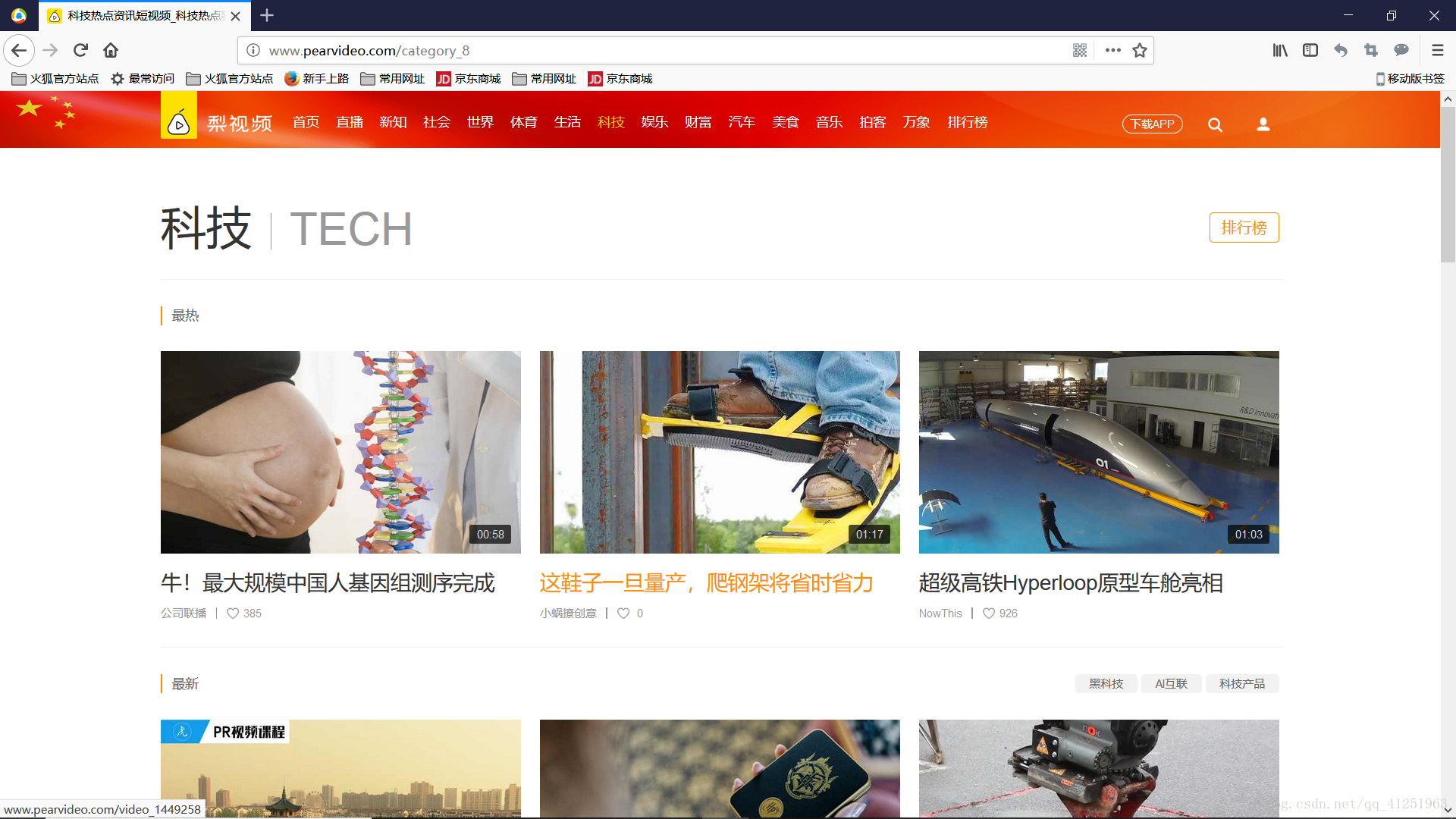
本文以下載科技類視訊為例,所以請求的網址為http://www.pearvideo.com/category_8
如果想下載體育類視訊,則更改請求網址:
分析:
首先分析網站,開啟開發者工具(F12)
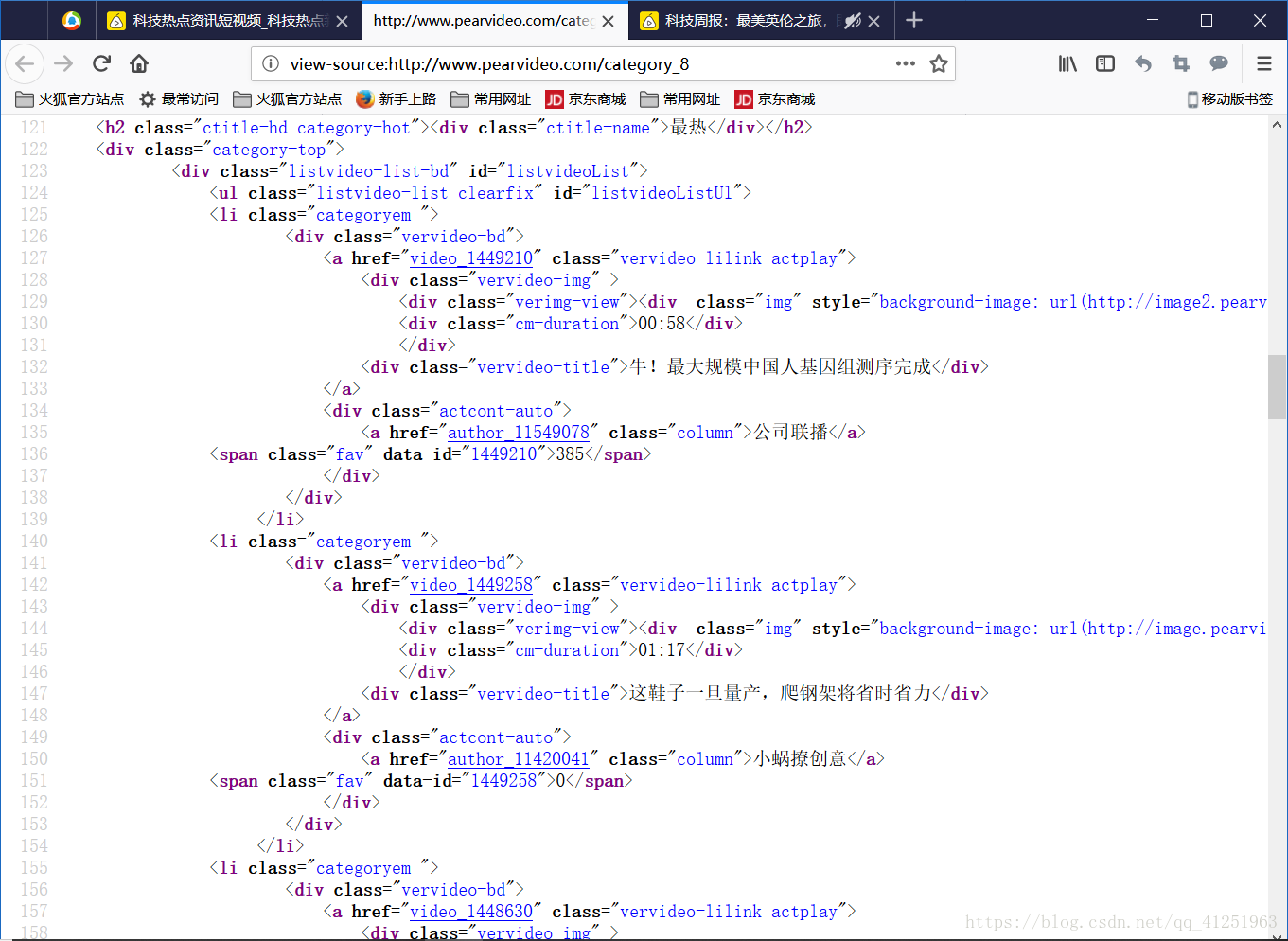
用檢視器選中一個視訊,我們可以發現視訊的ID資訊。紅框內為視訊的id。
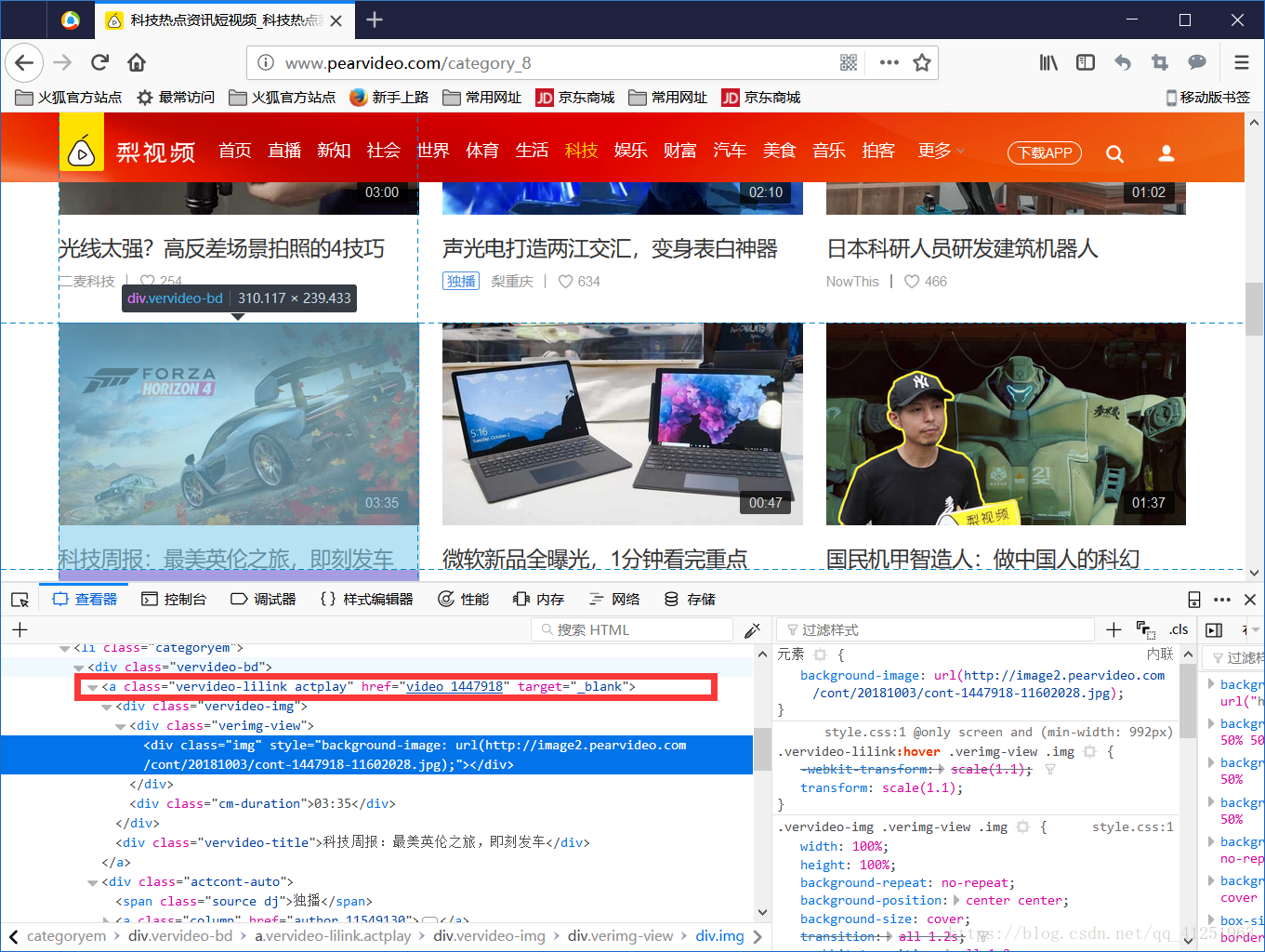
 我們檢查網頁原始碼,檢視id,利用正則表示式獲取id。
我們檢查網頁原始碼,檢視id,利用正則表示式獲取id。reg='<a href="(.*?)" class="vervideo-lilink actplay">'
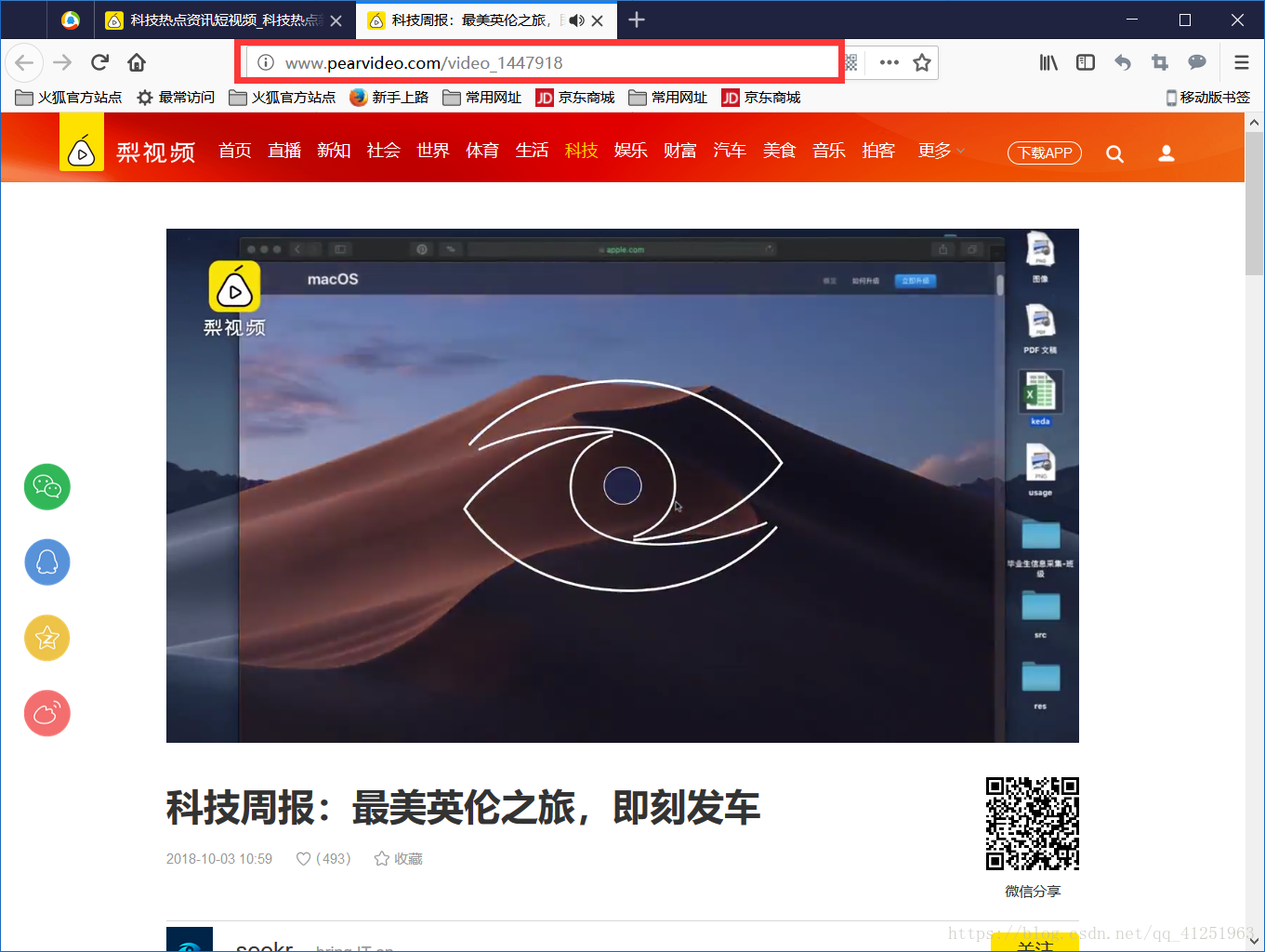
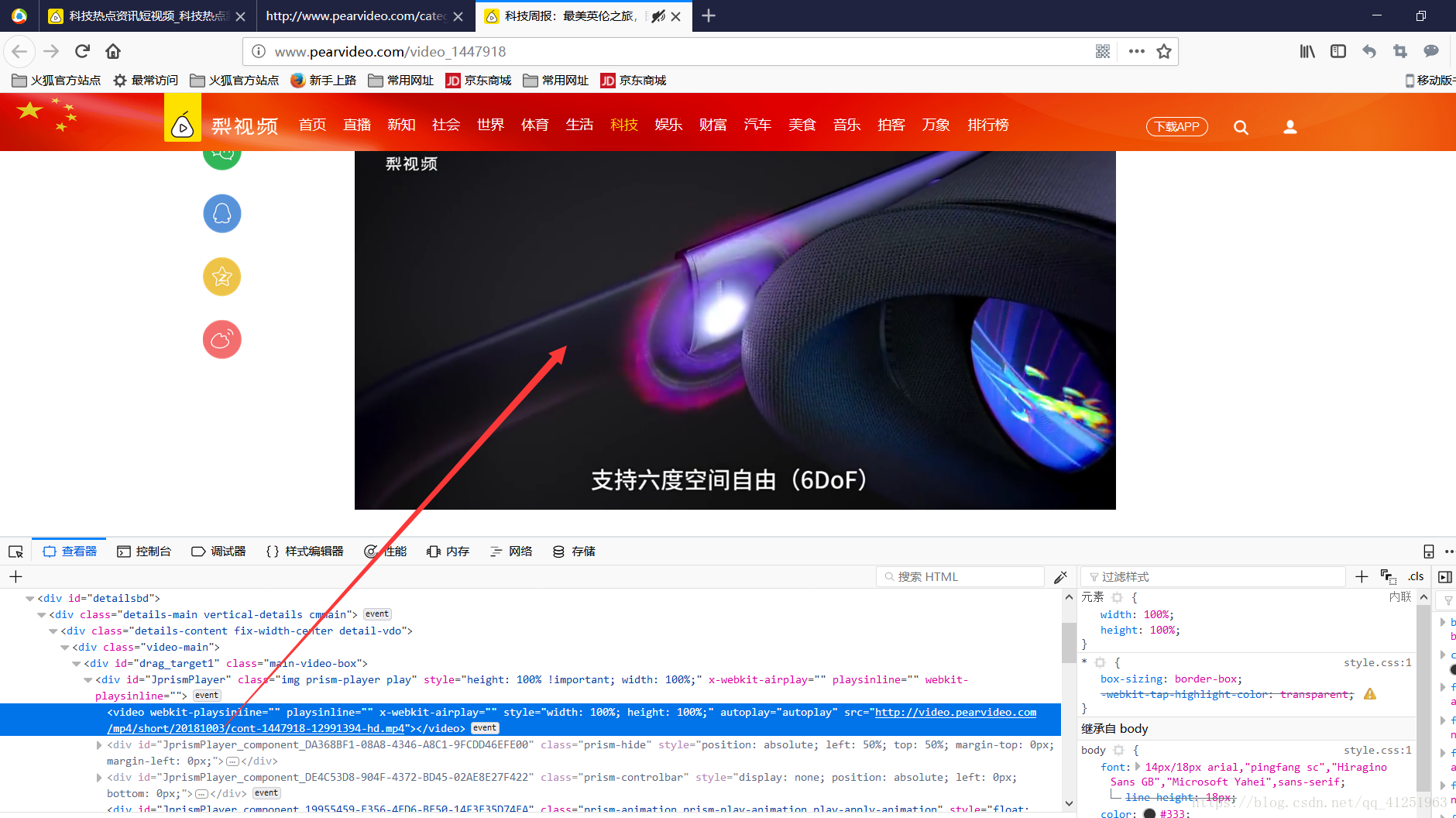
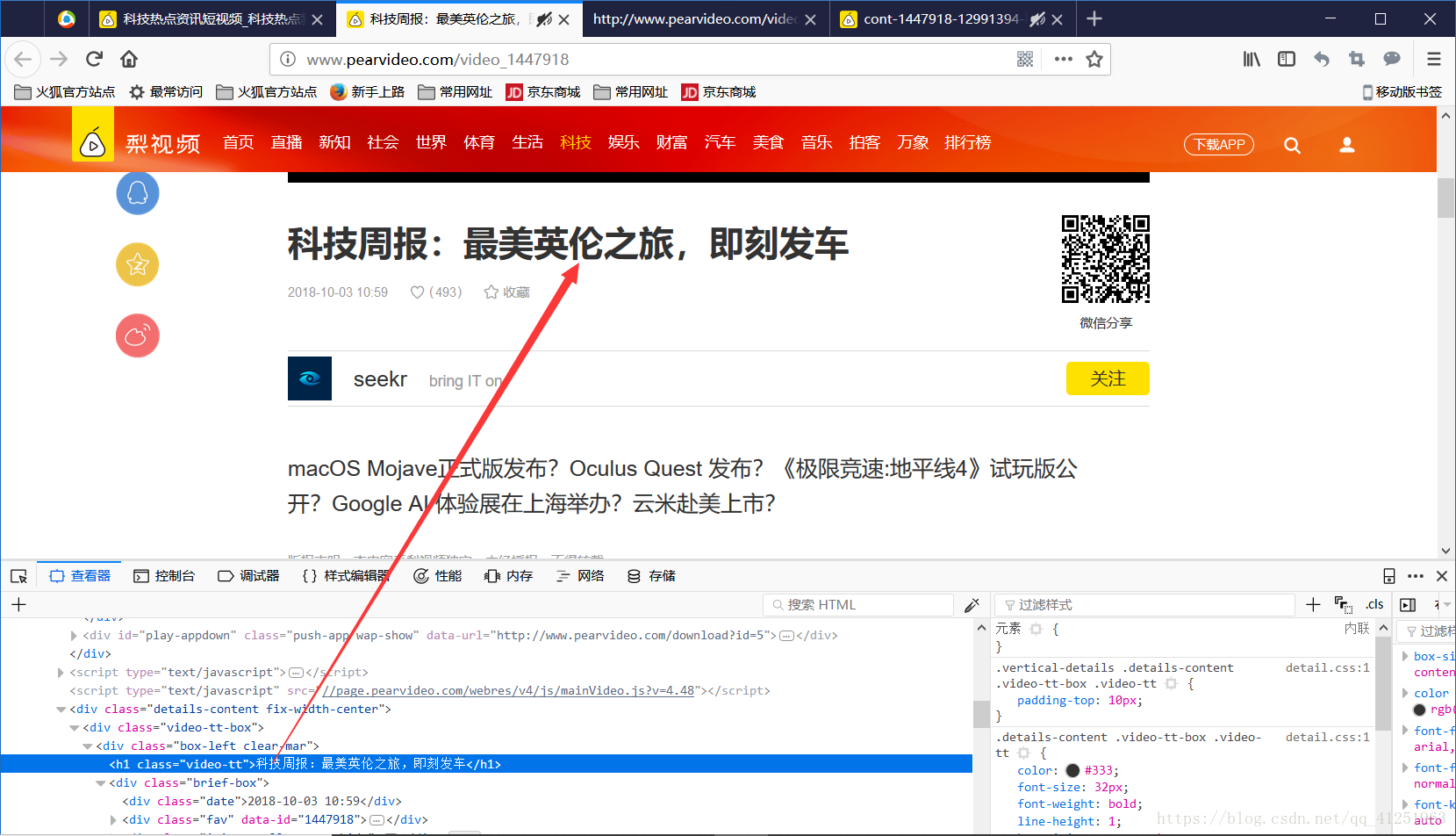
 獲取id後,我們獲取視訊播放地址。在此使用檢視器,檢視視訊,我們發現了一個視訊地址。複製後,在新的標籤頁中開啟,正是我們想要獲取的視訊。
獲取id後,我們獲取視訊播放地址。在此使用檢視器,檢視視訊,我們發現了一個視訊地址。複製後,在新的標籤頁中開啟,正是我們想要獲取的視訊。
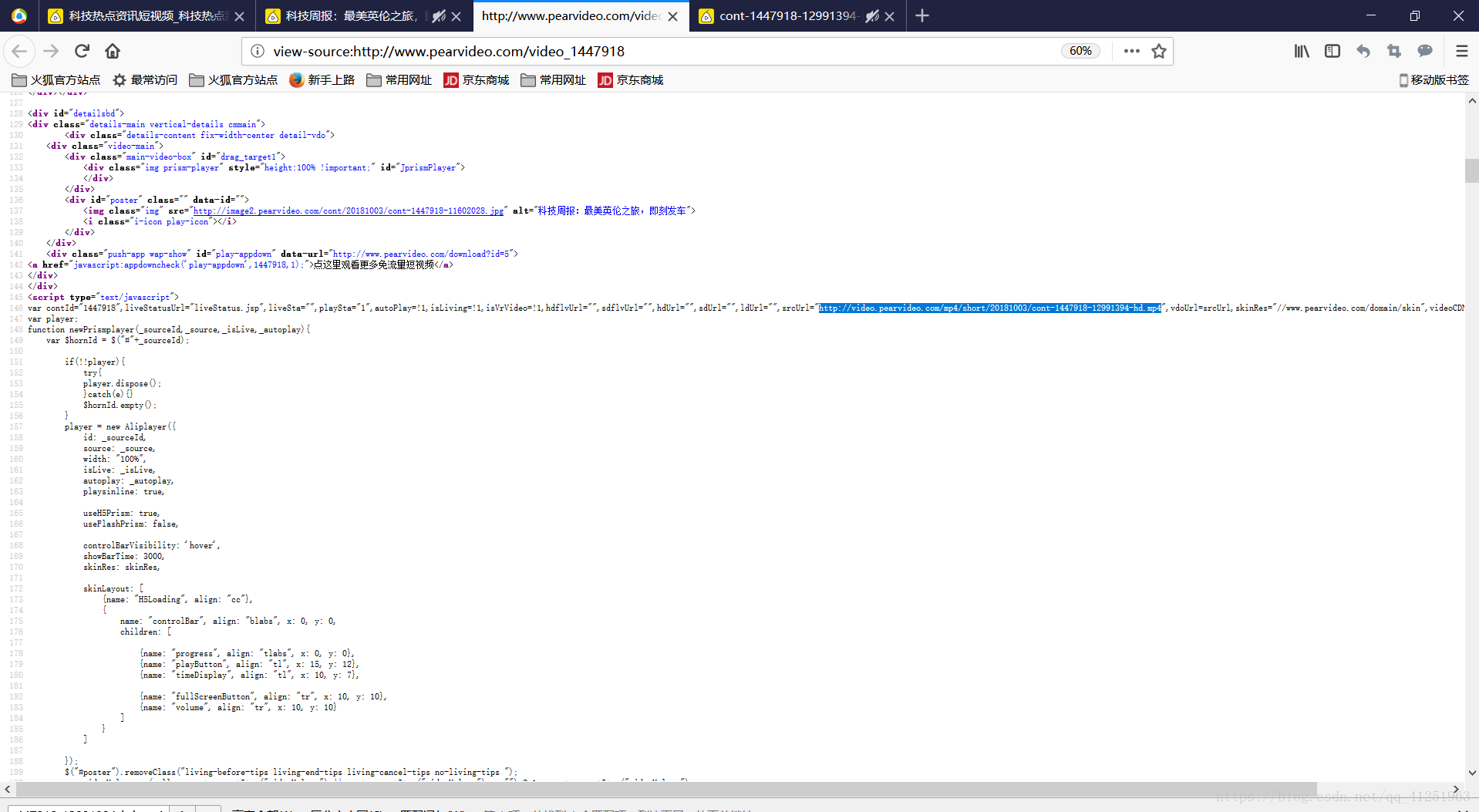
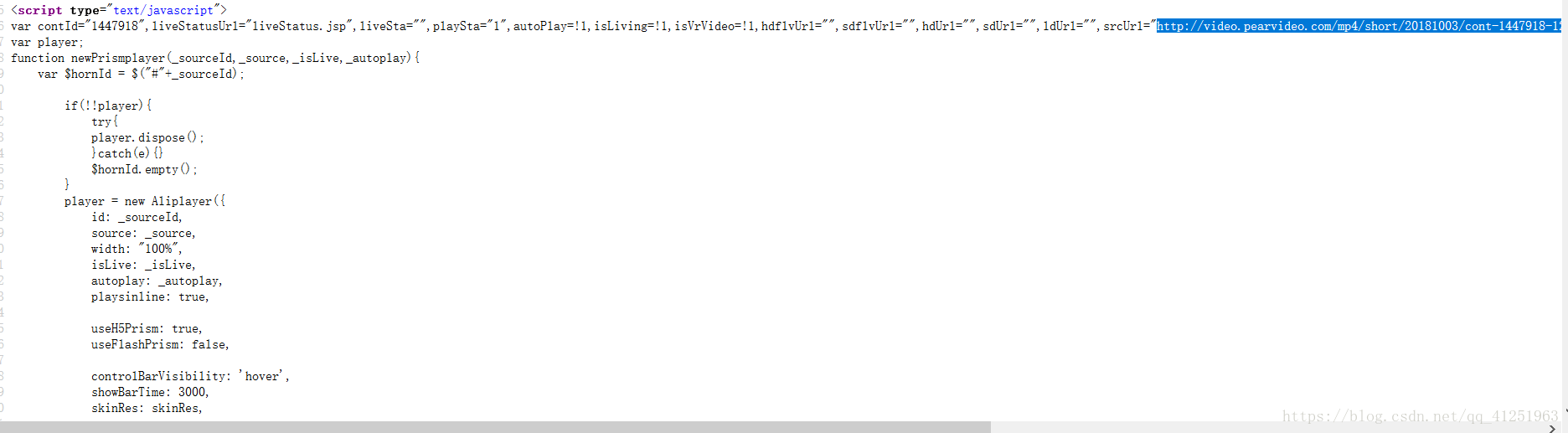
我們還是獲取播放視訊頁面的網頁原始碼,使用正則表示式reg='ldUrl="",srcUrl="(.*?)"'
 正則表示式:
正則表示式:reg='<h1 class="video-tt">(.*?)</h1>'
下載視訊:建立資料夾,存取視訊if path not in os.listdir(): os.mkdir(path)
下載urllib.request.urlretrieve
完整程式碼:有註釋
import requests import re import os import urllib.request #下載視訊 def download(): #獲取網頁原始碼 url="http://www.pearvideo.com/category_8" #模擬瀏覽器去請求伺服器 headers={ 'User-Agent':'Mozilla / 5.0(Windows NT 10.0;WOW64;rv:62.0) Gecko / 20100101Firefox / 62.0', } #狀態碼 html=requests.get(url,headers=headers) #print(html.text) #獲取視訊id .*?匹配所有 reg='<a href="(.*?)" class="vervideo-lilink actplay">' video_id=re.findall(reg,html.text) #print(video_id) #拼接URL地址 video_url=[]#接收拼接好的url starturl='http://www.pearvideo.com'+'' for vid in video_id: newurl=starturl+'/'+vid #print(newurl) video_url.append(newurl) #獲取視訊播放地址 for purl in video_url: html=requests.get(purl,headers=headers) reg='ldUrl="",srcUrl="(.*?)"' playurl=re.findall(reg,html.text) #print(playurl) #獲取視訊標題 reg='<h1 class="video-tt">(.*?)</h1>' video_name=re.findall(reg,html.text) #print(video_name[0]) #下載視訊 print('正在下載視訊%s'%video_name) path='video' if path not in os.listdir(): os.mkdir(path) filepath=path+"/%s"%video_name[0]+'.mp4' #下載 urllib.request.urlretrieve(playurl[0],filepath) download()
執行結果,獲取到視訊.
