
家用電器使用者行為分析與事件識別
目標
1、根據熱水器採集到的資料,劃分一次完整用水資料。
2、在劃分好的一次完整用水事件中,識別出洗浴事件。
資料預處理
1、原始資料集太大,進行資料抽取
2、由於熱水器採集的用水資料屬性較多,我們只選擇與分析目標相關的屬性。
3、如何劃分一次完整的用水事件呢?
如果水流量為0的狀態記錄之間的時間間隔超過一個閾值T,則從該段水流量為0的狀態記錄向前找到最後一條水流量不為0的用水記錄作為上一次用水事件的結束;向後找到水流量不為0的狀態記錄作為下一個用水事件的開始。
實現方法:
只取水流量>0的值,然後對過濾後的資料進行相鄰時間差分運算,差分結果大於給定閾值的差分結果保留下來,統計所有值的個數,就是用水事件數。
data = data[data[u'水流量'] > 0] #只要流量大於0的記錄
d = data[u'發生時間'].diff() > threshold #相鄰時間作差分,比較是否大於閾值
data[u'事件編號'] = d.cumsum() + 1 #通過累積求和的方式為事件編號
4、閾值尋優模型:
對使用者某時間段不同用水時間間隔閾值事件劃分個數和劃分閾值作圖,
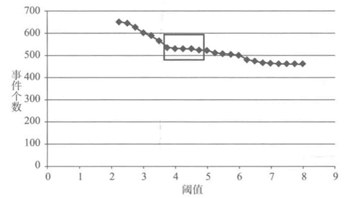
在某段閾值範圍內,下降趨勢明顯,說明在該段閾值範圍內,使用者的停頓習慣比較集中。在趨勢比較平穩部分,說明在對應段閾值範圍內,使用者的用水停頓習慣趨於穩定,所以取該段時間開始作為閾值,既不會將短的用水事件合併,也不會將長的用水事件拆開。
如何使用程式識別這個最優的閾值呢?
對每一個點求出一個斜率指標,這個指標不是改點和相鄰點形成的直線的斜率值,而是從改點往後選取n(3-6)個點,這n個點的相鄰點可以求出一個斜率值,將所有的斜率值求出平均值,作為起始點的斜率指標k。如果k<1,就將該點作為最優的閾值點。1是經過實際資料驗證的一個專家閾值。當不存在K<1時,則找所有閾值中斜率指標最小的閾值,如果該閾值的斜率指標小於5,則取該閾值作為用水事件劃分的閾值,如果該閾值的斜率指標不小於5,則閾值取預設值的閾值為4分鐘。其中,斜率指標小於5是一個專家閾值。
程式碼實現:
n = 4 #使用以後四個點的平均斜率
threshold = pd.Timedelta(minutes = 5) #專家閾值
data = pd.read_excel(inputfile)
data[u'發生時間'] = pd.to_datetime(data[u'發生時間'], format = '%Y%m%d%H%M%S')
data = data[data[u'水流量'] > 0] #只要流量大於0的記錄
def event_num(ts):
d = data[u'發生時間'].diff() > ts #相鄰時間作差分,比較是否大於閾值
return d.sum() + 1 #這樣直接返回事件數
dt = [pd.Timedelta(minutes = i) for i in np.arange(1, 9, 0.25)]
h = pd.DataFrame(dt, columns = [u'閾值']) #定義閾值列
h[u'事件數'] = h[u'閾值'].apply(event_num) #計算每個閾值對應的事件數
h[u'斜率'] = h[u'事件數'].diff()/0.25 #計算每兩個相鄰點對應的斜率
h[u'斜率指標'] = pd.rolling_mean(h[u'斜率'].abs(), n) #採用後n個的斜率絕對值平均作為斜率指標
ts = h[u'閾值'][h[u'斜率指標'].idxmin() - n]
#注:用idxmin返回最小值的Index,由於rolling_mean()自動計算的是前n個斜率的絕對值平均
#所以結果要進行平移(-n)
if ts > threshold:
ts = pd.Timedelta(minutes = 4)
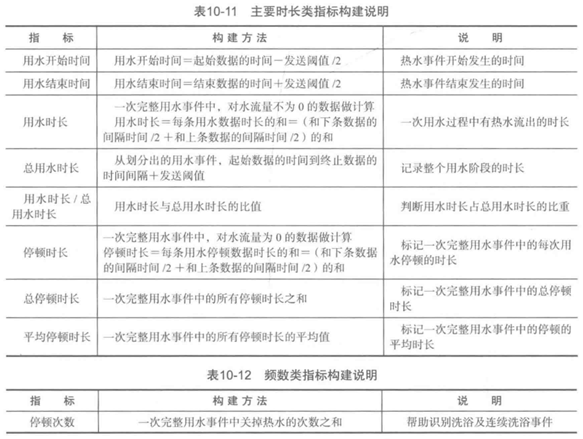
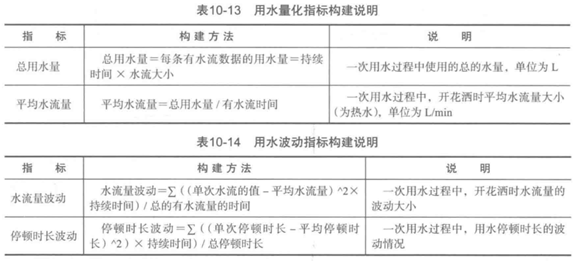
5、屬性構造
本案例研究的是用水行為,可構造4類指標:時長指標、頻率指標、用水的量化指標、用水的波動指標。
屬性構建說明:
模型構建
使用MLP進行建模
一般2層的神經網路可以解決大部分分類問題。經反覆驗證得到兩個隱層的 隱節點數分別為17,10時分類效果較好。
程式碼實現:
model = Sequential() #建立模型
model.add(Dense(11, 17)) #新增輸入層、隱藏層的連線
model.add(Activation('relu')) #以Relu函式為啟用函式
model.add(Dense(17, 10)) #新增隱藏層、隱藏層的連線
model.add(Activation('relu')) #以Relu函式為啟用函式
model.add(Dense(10, 1)) #新增隱藏層、輸出層的連線
model.add(Activation('sigmoid')) #以sigmoid函式為啟用函式
#編譯模型,損失函式為binary_crossentropy,用adam法求解
model.compile(loss='binary_crossentropy', optimizer='adam', class_mode="binary")
model.fit(x_train, y_train, nb_epoch = 100, batch_size = 1) #訓練模型