
爬蟲過程中如何構建代理IP池?
做網路爬蟲時,一般對代理IP的需求量比較大。因為在爬取網站資訊的過程中,很多網站做了反爬蟲策略,可能會對每個IP做頻次控制。這樣我們在爬取網站時就需要很多代理IP。
代理IP的獲取,可以從以下幾個途徑得到:
- 從免費的網站上獲取,質量很低,能用的IP極少
- 購買收費的代理服務,質量高很多
- 自己搭建代理伺服器,穩定,但需要大量的伺服器資源。
本文的代理IP池是通過爬蟲事先從多個免費網站上獲取代理IP之後,再做檢查判斷IP是否可用,可用的話就存放到MongoDB中,最後展示到前端的頁面上。
獲取可用Proxy
獲取代理的核心程式碼是ProxyManager,它採用RxJava2來實現,主要做了以下幾件事:
1、建立ParallelFlowable,針對每一個提供免費代理IP的頁面並行地抓取。

2、針對每一個頁面進行抓取,返回List

3、對每一個頁面獲取的代理IP列表進行校驗,判斷是否可用

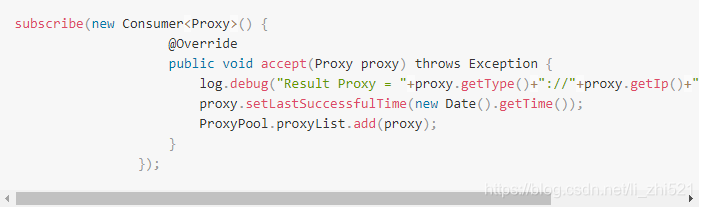
在做爬蟲時,自己維護一個可用的代理IP池是很有必要的事情,當然想要追求更高穩定性的代理IP還是考慮購買比較好。
相關推薦
爬蟲過程中的代理ip使用
目前很多網站都會設定相對應的防爬蟲機制,這是因為有一部分人在實際的爬蟲主權過程中會進行惡意採集或者惡意攻擊,通常情況下,防爬蟲程式是通過IP來識別哪一些是機器人使用者,因此可以使用可用的IP資訊解決實際中的爬蟲遇到的問題 一般情況下爬蟲開
爬蟲過程中如何構建代理IP池?
做網路爬蟲時,一般對代理IP的需求量比較大。因為在爬取網站資訊的過程中,很多網站做了反爬蟲策略,可能會對每個IP做頻次控制。這樣我們在爬取網站時就需要很多代理IP。 代理IP的獲取,可以從以下幾個途徑得到: 從免費的網站上獲取,質量很低,能用的IP極少 購買收費的代理服務,
構建一個給爬蟲使用的代理IP池
做網路爬蟲時,一般對代理IP的需求量比較大。因為在爬取網站資訊的過程中,很多網站做了反爬蟲策略,
建立爬蟲代理IP池
web odin pro __main__ headers XML Coding txt文件 端口號 #!/usr/bin/python3.5 # -*- coding:utf-8 -*- import time import tempfile from l
如何搭建穩定的代理ip池, 供爬蟲使用
什麽 git 免費 文章 存在 服務器 根據 代理服務器 如何 新型的代理ip池aox_proxy_pool 在這篇文章之前, 應該不少人都看過很多搭建代理ip池的文章, 然後發現都是坑, 無法使用。說的比較多的 推薦買xx家的代理ip, 賊穩定, 好使(廣告) 抓取x
通過Python利用ADSL伺服器和tinyproxy構建資料自己的動態代理IP池,用django+redis做web服務 (優化版)
代理池初始版:https://blog.csdn.net/MeteorCountry/article/details/82085238 上一篇文章中所搭建的代理池在使用過程中出現了點小問題,代理池中莫名的多出了一些無效代理,檢查日誌後返現是在更新代理 池時舊的代理IP沒有刪除成功,就添加了新
通過Python利用ADSL伺服器和tinyproxy構建資料自己的動態代理IP池,用django+redis做web服務,提供IP介面
應公司業務需求需要在一些地方使用代理,要求連通率高,速度快,最主要的還要便宜,對比多家供應商後,最後還是決定自購撥號服務搭建代理IP池。 需要配置:1.一臺或多臺adsl伺服器(用以提供IP,可網上購買,通過ssh同域名連線)2.一臺正常固定IP伺服器擁來搭建IP代理池。(統一配置:python
爬蟲代理IP池的實現
使用代理髮送請求: requests.get(url,proxies={協議:協議+ip+埠}) 正向代理:客戶端知道最終伺服器的地址 反向代理:客戶端不知道最終伺服器的地址 怎樣合理的使用代理: 準備一堆的ip地址,組成ip池,隨機選擇一個ip來時用 如何隨機選擇
搭建一個自己的百萬級爬蟲代理ip池.
做爬蟲抓取時,我們經常會碰到網站針對IP地址封鎖的反爬蟲策略。但只要有大量可用的代理IP資源,問題自然迎刃而解。 以前嘗試過自己抓取網路上免費代理IP來搭建代理池,可免費IP質量參差不齊,不僅資源少、速度慢,而且失效快,滿足不了快速密集抓取的需求。 收費代理提供的代理資源質量明顯提升
多執行緒+代理ip池 爬蟲
# coding=utf-8 import tushare as ts import pandas as pd import requests import json import re import time from retrying import retry from concurren
呼叫成品api構建自己的代理IP池
# coding=utf-8 import tushare as ts import pandas as pd import requests import json import re import time def get_pro(): a=requests.get('http
Python3網路爬蟲(十一):爬蟲黑科技之讓你的爬蟲程式更像人類使用者的行為(代理IP池等)
轉載請註明作者和出處:http://blog.csdn.net/c406495762 執行平臺: Windows Python版本: Python3.x IDE: Sublime text3 1 前言 近期,有些朋友問我一些關於如何應
維護爬蟲代理IP池--採集並驗證
任務分析 我們爬的免費代理來自於https://www.kuaidaili.com這個網站。用`requests`將ip地址與埠採集過來,將`IP`與`PORT`組合成`requests`需要的代理格式,用`requests`訪問`[http://ipcheck.chinahosting.tk/][1]`,
Python3網絡爬蟲(十一):爬蟲黑科技之讓你的爬蟲程序更像人類用戶的行為(代理IP池等)
ping通 range alt 所在 and 有用 傳遞 javascrip was 原文鏈接: Jack-Cui,http://blog.csdn.net/c406495762 運行平臺: Windows Python版本: Python3.x IDE: Sublime
爬蟲代理IP池
爬蟲代理IP池 介紹 原始碼獲取方式 技術交流群 介紹 通過爬蟲技術獲取有效的代理IP,基於Python-tornado的API框架對代理IP進行操作,詳情請瀏覽專案Git 原始碼獲取方式 Git : https://githu
python爬蟲設定代理ip池——方法(一)
"""在使用python爬蟲的時候,經常會遇見所要爬取的網站採取了反爬取技術,高強度、高效率地爬取網頁資訊常常會給網站伺服器帶來巨大壓力,所以同一個IP反覆爬取同一個網頁,就很可能被封,那如何解決呢?使用代理ip,設定代理ip池。以下介紹的免費獲取代理ip池的方法:優點:1.
Python爬蟲代理IP池
aid 高性能 資源 ret 有用 惰性 做成 同時 選擇 目錄[-] 1、問題 2、代理池設計 3、代碼模塊 4、安裝 5、使用 6、最後 在公司做分布式深網爬蟲,搭建了一套穩定的代理池服務,為上千個爬蟲提供有效的代理,保證各個爬
爬蟲入門到放棄系列05:從程式模組設計到代理IP池
## 前言 上篇文章吧啦吧啦講了一些有的沒的,現在還是回到主題寫點技術相關的。本篇文章作為基礎爬蟲知識的最後一篇,將以爬蟲程式的模組設計來完結。 在我漫(liang)長(nian)的爬蟲開發生涯中,我通常將爬蟲程式分為四大模組。  tex gen 錯誤類型 pro orm 大體思路 使用redis作為隊列,買了一份蘑菇代理,但是這個代理每5秒可以請求一次,我們將IP請求出來,從redis列表隊列的左側插入,要用的時候再從右側取出,請求成功證明該IP是可用的,將該代理IP從左