
大資料組織形象圖及詳細說明
“聽說現在的大資料可厲害,你幹啥人家都知道”。
早上8點,賣包子的大媽這樣對我說:
隨著大規模資料處理技術的日漸成熟,擁有海量使用者資料的公司都想從中挖掘出有利資訊來影響使用者的生活消費。
-
京東、淘寶等電商網站利用使用者畫像做個性化商品推薦;
-
今日頭條、一點資訊利用演算法做個性化內容推薦;
-
支付寶、宜信等網際網路金融公司通過識別高危行為的特徵實施風險控制;
這類企業對大資料、資料探勘相關人才的需求非常之大,導致行業內人才的供給嚴重不足。
因此,大資料、資料探勘、人工智慧相關人才薪資都非常高,大資料平臺/開發工程師(Hadoop)的起薪也在25K/月,像AI工程師平均年薪要在40-60萬。

這也正是普通程式設計師的職場機遇。
那如何學習才能順利入行並拿到30萬+年薪呢?
下面給大家介紹詳細的學習方案:
第一階段:語言基礎
1.Java
掌握JavaSE知識,不需要深入;
2.Linux
系統安裝、基本命令、Shell指令碼等;
3.Python
基礎語法、資料結構等。
Python是人工智慧領域最主流的程式語言,學習Python大資料技術有利於無縫轉AI。
第二階段:Hadoop生態架構技術
1.環境準備
在windows電腦搭建完全分散式,1主2從。
需要用到:VMware虛擬機器、Linux系統(Centos6.5)、Hadoop安裝包。
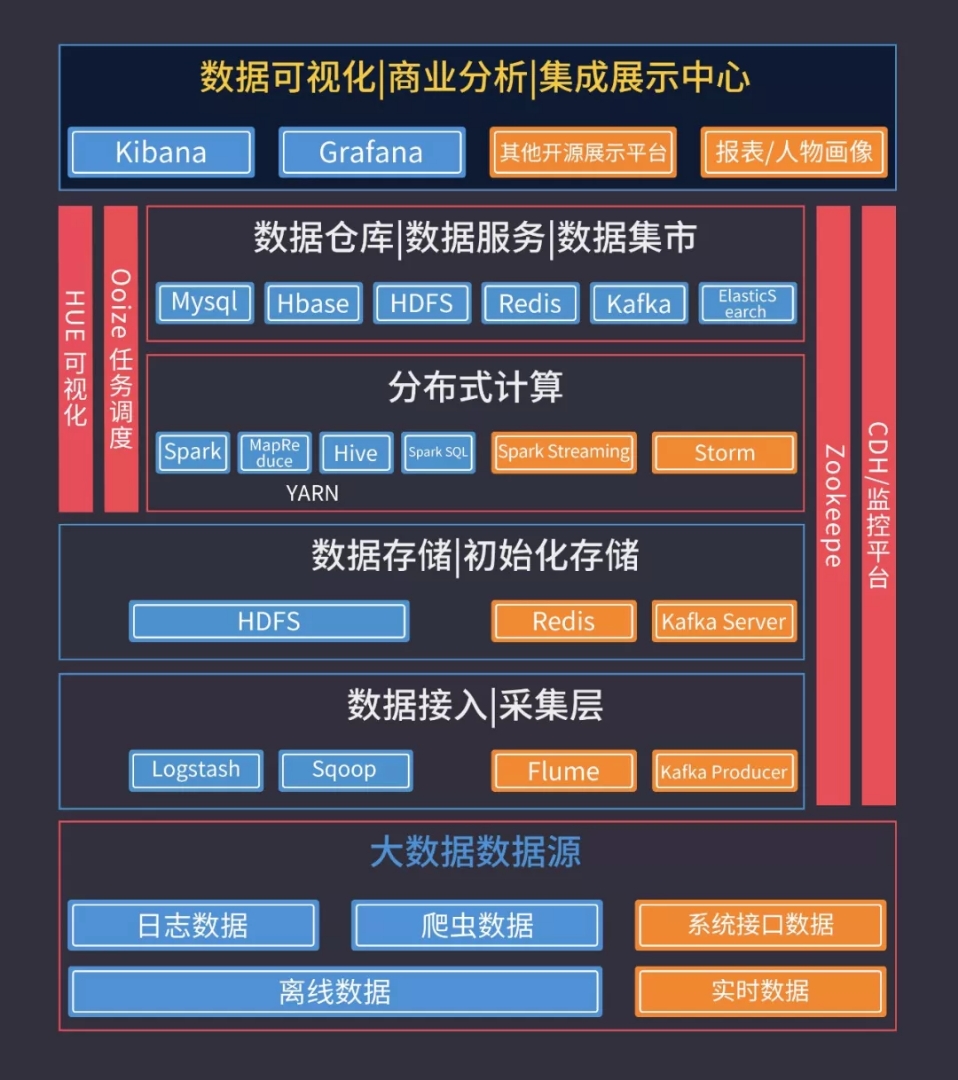
2.Map Reduce
主要適用於大批量的叢集任務,時效性偏低。
3.HDFS1.0/2.0
Hadoop分散式檔案系統(HDFS)能提供高吞吐量的資料訪問。
4.Yarn(Hadoop2.0)
Yarn是一個資源排程平臺,主要負責給任務分配資源。
5.Hive
Hive是一個數據倉庫,所有的資料都儲存在HDFS上。
使用Hive主要是寫Hql,底層執行的是Map Redce程式。
6.Spark
Spark 是基於記憶體的迭代式計算,繼承了Map Reduce 的優點,而且在時效性上有了很大提高。
7.Spark Streaming
Spark Streaming是實時處理框架,資料是一批一批的處理。
8.Spark Hive
Spark作為Hive的計算引擎,可以提高Hive查詢的效能。
9.Storm
Storm是一個實時計算框架,對實時新增的每一條資料進行處理,是一條一條的處理。
10.Zookeeper
Zookeeper是很多大資料框架的基礎,它是叢集的管理者。
11.Hbase
Hbase是一個Nosql 資料庫,適用於非結構化的資料儲存,底層的資料儲存在HDFS上。
12.Kafka
kafka是一個訊息中介軟體,作為一箇中間緩衝層。
13.Flume
Flume是一個日誌採集工具,常見的就是採集應用產生的日誌檔案中的資料。
按照上述順序學習,並掌握後就可以從事Hadoop開發工程師、Spark開發工程師等職位。
第三階段:資料探勘、機器學習演算法
1.中文分詞
開源分詞庫的離線和線上應用;
2.自然語言處理
文字相關性演算法;
3.推薦演算法
基於CB、CF,歸一法,Mahout應用;
4.分類演算法
NB、SVM;
5.迴歸演算法
LR、Decision Tree;
6.聚類演算法
層次聚類、Kmeans;
7.神經網路與深度學習
NN、Tensorflow;
按照上述順序學習,並掌握後就可以從事資料探勘相關的職位。
這也是普通程式設計師轉行演算法、機器學習相關工程師最簡單的職位,而且這個職位非常利於後期向AI工程師發展。
--------------------- 本文來自 撲滿心 的CSDN 部落格 ,全文地址請點選:https://blog.csdn.net/sinat_38648491/article/details/79912837?utm_source=copy