
ARM aarch64彙編學習筆記(九):使用Neon指令(一)
阿新 • • 發佈:2018-12-14
NEON是一種基於SIMD思想的ARM技術。 SIMD, Single Instruction Multiple Data,是一種單條指令處理多個數據的並行處理技術,相比於一條指令處理一個數據,運算速度將會大大提高。
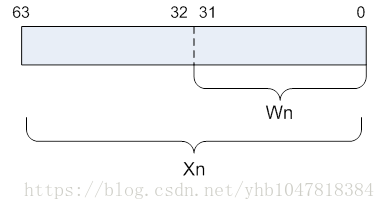
ARMv8 有31 個64位暫存器,1個不同名字的特殊暫存器,用途取決於上下文, 因此我們可以看成 31個64位的X暫存器或者31個32位的W暫存器(X暫存器的低32位)

以一個簡單的例子來說明使用Neon帶來的收益。 比如, 現在有一個很簡單的需求, 有2組資料, 每組資料有16 x 1024個整型數, 讓它們按順序一一相加,得到相加的和(每組資料的數不超過255,相加的和如果大於255,則返回255).
如果用C語言實現:
#include <stdio.h> #include <time.h> #define MAX_LEN 16 * 1024 * 1024 typedef unsigned char uint_8t; typedef unsigned short uint_16t; int main() { double start_time; double end_time; uint_8t *dist1 = (uint_8t *)malloc(sizeof(uint_8t) * MAX_LEN); uint_8t *dist2 = (uint_8t *)malloc(sizeof(uint_8t) * MAX_LEN); uint_16t *ref_out = (uint_16t *)malloc(sizeof(uint_16t) * MAX_LEN); // 2組資料隨機賦值 for (int i = 0; i < MAX_LEN; i++) { dist1[i] = rand() % 256; dist2[i] = rand() % 256; } start_time = clock(); for (int i = 0; i < MAX_LEN; i++) { ref_out[i] = dist1[i] + dist2[i]; if (ref_out[i] > 255) { ref_out[i] = 255; } } end_time = clock(); printf("C use time %f s\n", end_time - start_time); return 0; }
因為C語言的實現每次相加都只操作了一個暫存器,由於每一個輸入和輸出都不大於255, 可以用8bit的暫存器儲存,對於暫存器而言造成了浪費。 如果使用Neon進行加速:
.text
.global asm_add_neon
asm_add_neon:
LOOP:
LDR Q0, [X0], #0x10
LDR Q1, [X1], #0x10
UQADD V0.16B, V0.16B, V1.16B
STR Q0, [X2], #0x10
SUBS X3, X3, #0x10
B.NE LOOP
RET
Q0代表陣列A, Q1代表陣列B, 每次讀128bit (16個), 利用ARM vector無飽和相加指令UQADD進行計算,得到的結果儲存在X2暫存器。
比較C語言和ARM NEON加速後實現的效能:
#include <stdio.h>
#include <time.h>
#define MAX_LEN 16 * 1024 * 1024
typedef unsigned char uint_8t;
typedef unsigned short uint_16t;
extern int asm_add_neon(uint_8t *dist1, uint_8t *dist2, uint_8t *out, int len);
int main()
{
double start_time;
double end_time;
uint_8t *dist1 = (uint_8t *)malloc(sizeof(uint_8t) * MAX_LEN);
uint_8t *dist2 = (uint_8t *)malloc(sizeof(uint_8t) * MAX_LEN);
uint_8t *out = (uint_8t *)malloc(sizeof(uint_8t) * MAX_LEN);
uint_16t *ref_out = (uint_16t *)malloc(sizeof(uint_16t) * MAX_LEN);
for (int i = 0; i < MAX_LEN; i++)
{
dist1[i] = rand() % 256;
dist2[i] = rand() % 256;
}
start_time = clock();
for (int i = 0; i < MAX_LEN; i++)
{
ref_out[i] = dist1[i] + dist2[i];
if (ref_out[i] > 255)
{
ref_out[i] = 255;
}
//printf("%d dist1[%d] dist2[%d] refout[%d] \n", i,dist1[i], dist2[i], ref_out[i]);
}
end_time = clock();
printf("C use time %f s\n", end_time - start_time);
start_time = clock();
asm_add_neon(dist1, dist2, out, MAX_LEN);
end_time = clock();
printf("asm use time %f s\n", end_time - start_time);
for (int i = 0; i < MAX_LEN; i++)
{
if (out[i] != ref_out[i])
{
printf("ERROR:%d\n", i);
return -1;
}
}
printf("PASS!\n");
return 0;
}
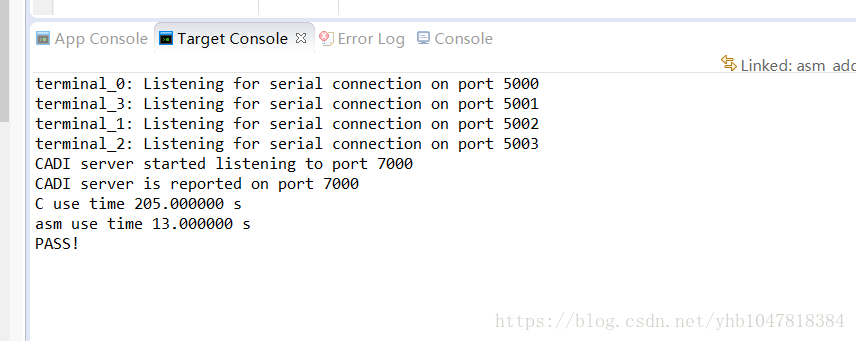
arm neon彙編實現的效能正好大約是純C語言實現的16倍。