
centos中pipelinedb安裝及初步使用
阿新 • • 發佈:2018-12-14
安裝
下載安裝包
https://www.pipelinedb.com/download
建立系統檔案目錄和日誌目錄

pipelinedb安裝
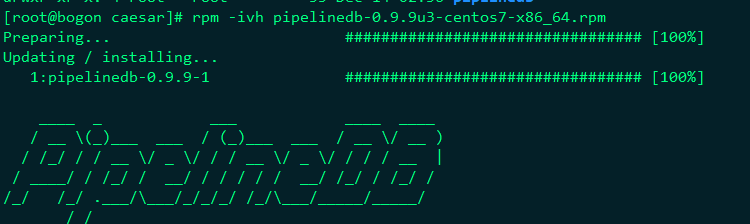
使用非root使用者,初始化pipelinedb
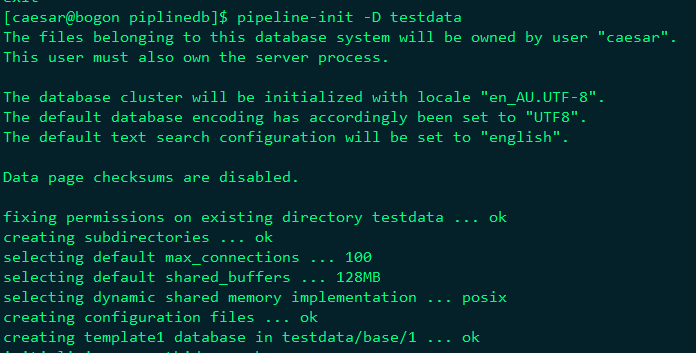
修改配置檔案
vim pipelinedb.conf
vim pg_hba.conf
啟動pipelinedb

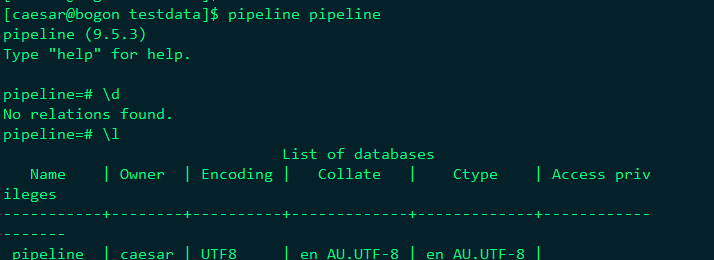
進入pipelinedb客戶端
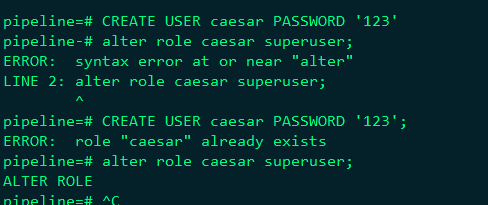
新增使用者
初步使用
建立stream,供資料insert到stream後,各個檢視獲取資料。如下建立一個三個欄位x,y,z 的stream。x 為interger,y為interger,z為text

建立一個continuous view 檢視,該檢視從stream_test1 流中,統計x+y的和
create continuous view v_sum as select sum(x+y) from stream_test1; 其中 as 之後是對流中資料處理,通過select ..(欄位處理分析函式)...from後表示處理的流名稱

對stream_test1插入資料,insert into stream_test1 values (1,2,'A'),(3,4,'B'),(5,6,'C'),(7,8,'D'),(1,2,'A');

查詢檢視中資料:select * from v_sum;
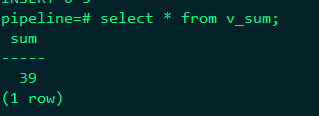
建立一個original 檢視,對流過的原始資料儲存
create continuous view orginal as select x,y,z from stream_test1;

插入資料

查詢檢視中資料
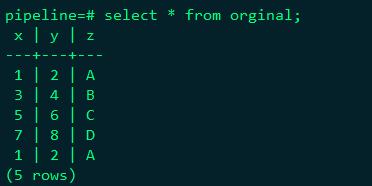
從上面可以看出,pipelinedb對資料只儲存資料中關心的資料進行處理,其他不關心的資料直接丟棄。對一些統計,比如網站流量和top 問題比較有用,如果只是儲存資料,則可能效能並不很好