
rownumber() over(partition by col1 order by col2)
今天在使用多欄位去重時,由於某些欄位有多種可能性,只需根據部分欄位進行去重,在網上看到了rownumber() over(partition by col1 order by col2)去重的方法,很不錯,在此記錄分享下:
row_number() OVER ( PARTITION BY COL1 ORDER BY COL2) 表示根據COL1分組,在分組內部根據 COL2排序,而此函式計算的值就表示每組內部排序後的順序編號(組內連續的唯一的).
與rownum的區別在於:使用rownum進行排序的時候是先對結果集加入偽列rownum然後再進行排序,而此函式在包含排序從句後是先排序再計算行號碼.
- row_number()和rownum差不多,功能更強一點(可以在各個分組內從1開時排序).
- rank()是跳躍排序,有兩個第二名時接下來就是第四名(同樣是在各個分組內).
- dense_rank()l是連續排序,有兩個第二名時仍然跟著第三名。相比之下row_number是沒有重複值的.
- lag(arg1,arg2,arg3):
- arg1是從其他行返回的表示式
- arg2是希望檢索的當前行分割槽的偏移量。是一個正的偏移量,是一個往回檢索以前的行的數目。
- arg3是在arg2表示的數目超出了分組的範圍時返回的值。
函式語法:
OPAP函式語法四部分:
1.function 本身用於對視窗中的資料進行操作;
2.partitioning clause 用於將結果集分割槽;
3.order by clause 用於對分割槽中的資料進行排序;
4.windowing clause 用於定義function在其上操作的行的集合,即function所影響的範圍;
----1. ROW_NUMBER() OVER(PARTITION BY COL1 ORDER BY COL2)
---查詢所有姓名,如果同名,則按年齡降序
SELECT NAME ,AGE,DETAILS,ROW_NUMBER() OVER(PARTITION BY NAME ORDER BY AGE DESC) FROM TEST_Y;
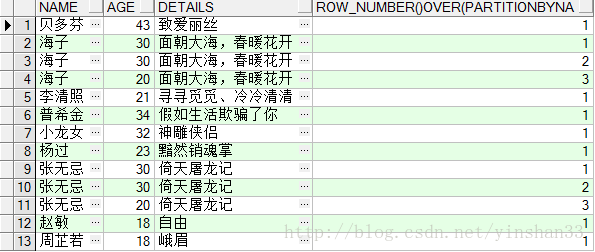
----通過上面的語句可知,ROW_NUMBER() OVER(PARTITION BY COL1 ORDER BY COL2)中是按照NAME欄位分組,按AGE欄位排序的。
----如果只需查詢出不重複的姓名即可,則可使用如下的語句
SELECT * FROM (SELECT NAME,AGE,DETAILS ,ROW_NUMBER() OVER( PARTITION BY NAME ORDER BY AGE DESC)RN FROM TEST_Y )WHERE RN= 1;
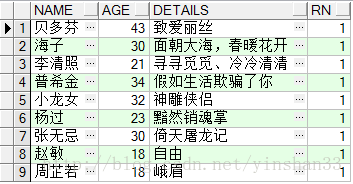
----由查詢結果可知,姓名相同年齡小的資料被過濾掉了;可以使用ROW_NUMBER() OVER(PARTITION BY COL1 ORDER BY COL2)對部分子彈進行去重處理