
高一致性分散式galera cluster(多主)叢集
何謂Galera Cluster?就是集成了Galera外掛的MySQL叢集,是一種新型的,資料不共享的,高度冗餘的高可用方案,目前Galera Cluster有兩個版本,分別是Percona Xtradb Cluster和MariaDB Cluster,都基於Galera,所以這裡都統稱為Galera Cluster,因為Galera本身具有多主特性,所以Galera Cluster也就是Multi-Master的叢集架構,如圖1所示。
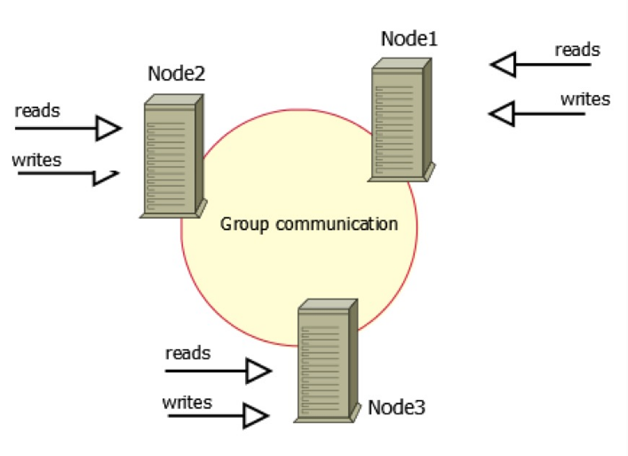
圖1中有三個例項,組成了一個叢集,而這三個節點與普通主從架構不同,都可作為主節點,三個節點對等,這種一般稱為Multi-Master架構,當有客戶端要寫入或讀取資料時,隨便連線哪個例項都一樣,讀到的資料相同,寫入某一節點後,叢集自己會將新資料同步到其他節點上,這種架構不共享任何資料,是一種高冗餘架構。
一般使用方法是,在這個叢集上再搭建一箇中間層,這個中間層的功能包括建立連線,管理連線池,負責使三個例項的負載基本平衡,負責在客戶端與例項的連線斷開之後重連,也可以負責讀寫分離(在機器效能不同的情況下可以做這樣的優化)等,使用這個中間層後,由於這三個例項的架構在客戶端方面是透明的,客戶端只需要指定這個叢集的資料來源地址,連線到中間層即可,中間層會負責客戶端與伺服器例項連線的傳遞工作,由於這個架構支援多點寫入,所以完全避免了主從複製經常出現的資料不一致問題,從而可以做到高度優雅的主從讀寫切換,在不影響使用者的情況下,進行離線維護等工作,MySQL的高可用從此開始,非常完美。
這裡最核心的問題其實是:在三個例項之間,因為它們關係對等,那麼在同時寫入時,如何保證整個叢集資料的一致、完整與正確?
通常在使用MySQL的過程中,也不難實現一種Multi-Master架構,但是一般需要上層應用來配合,比如先要約定每個表必須有自增列,並且如果是2個節點的情況,一個節點只能寫偶數值,而另一個節點只能寫奇數值,同時2個節點之間互相做複製,因為2個節點寫入的東西不同,所以複製不會衝突,在這種約定之下,可以基本實現多Master架構,也可以保證資料的完整性與一致性。但這種方式使用起來還是有限制,同時還會出現複製延遲,且不具有擴充套件性,不是真正意義上的叢集。
Galera的引入
現在已經知道,Galera Cluster是MySQL封裝了具有高一致性,支援多點寫入的同步通訊模組Galera而做的,它建立在MySQL同步基礎之上;使用Galera Cluster時,應用程式可以直接讀、寫某個節點的最新資料,並且可以在不影響應用程式讀寫的情況下,下線某個節點;因為支援多點寫入,使得Failover變得非常簡單。
所有的Galera Cluster,都對Galera所提供的介面API做了封裝,這些API為上層提供了豐富的狀態資訊及回撥函式,通過這些回撥函式,做到了真正的多主叢集、多點寫入和同步複製,這些API被稱作Write-Set Replication API,簡稱wsrep API。
通過這些API,Galera Cluster提供了基於驗證的複製,是一種樂觀的同步複製機制,一個將要被複制的事務(稱為寫集),不僅包括被修改的資料庫行,還包括這個事務產生的所有Binlog,每一個節點在複製事務時,都會拿這些寫集與正在APPLY佇列的寫集做比對,如果沒有衝突,這個事務就可以繼續提交,或APPLY,此時就認為這個事務被提交了,然後在資料庫層面,還需要繼續做事務上的提交操作。
這種方式的複製,也被稱為是虛擬同步複製,實際上是一種邏輯上的同步,因為每個節點的寫入和提交操作還是獨立的,更準確的說是非同步的。Galera Cluster建立在一種樂觀複製的基礎上,假設叢集中的每個節點都同步,加上在寫入時都會做驗證,那麼理論上是不會出現不一致的,當然也不能這麼樂觀,如果出現不一致,比如主庫(相對)插入成功,而從庫則出現主鍵衝突,那說明此時資料庫已經不一致,這種情況下Galera Cluster採取的方式是將出現不一致資料的節點踢出叢集,其實是自己shutdown了。
而通過使用Galera,它在其中通過判斷鍵值的衝突方式實現了真正意義上的Multi-Master,Galera Cluster在MySQL生態中,在高可用方面實現了非常重要的提升,目前Galera Cluster具備的功能包括以下幾個方面:
- 多主架構:真正的多點讀寫叢集,在任何時候讀寫資料,都是最新的。
- 同步複製:叢集不同節點之間資料同步,沒有延遲,在資料庫掛掉後,資料不會丟失。
- 併發複製:從節點APPLY資料時,支援並行執行,有更好的效能表現。
- 故障切換:在出現資料庫故障時,因為支援多點寫入,切換非常容易。
- 熱插拔:在服務期間,如果資料庫掛了,只要監控程式發現得夠快,不可服務時間就會非常少。在節點故障期間,節點本身對叢集的影響非常小。
- 自動節點克隆:在新增節點,或停機維護時,增量資料或者基礎資料不需要人工手動備份提供,Galera Cluster會自動拉取線上節點資料,最終叢集會變為一致。
- 對應用透明:叢集的維護對應用程式是透明的,幾乎感覺不到。
以上幾點,足以說明Galera Cluster是一個既穩健,又在資料一致性、完整性和高效能方面有出色表現的高可用解決方案。
目前熟知的一些特性,或者在運維中需要注意的一些特性,有以下幾個方面:
Galera Cluster寫集內容
Galera Cluster複製的方式,仍基於Binlog,很多人也一直為此困擾,因為目前Percona Xtradb Cluster所實現的版本中,將Binlog關掉後,還可以使用,這誤導了很多人,其實關掉之後,只是不落地了,表象上看上去沒有使用Binlog,實際上內部還是悄悄打開了。除此之外,寫集中還包括事務影響的所有行的主鍵,所有主鍵組成了寫集的KEY,而Binlog組成了寫集的DATA,這樣一個KEY-DATA就是寫集。
KEY和DATA分別具有不同的作用,KEY用來驗證與其它事務沒有衝突,而DATA則在驗證通過後做APPLY。
Galera Cluster的併發控制
從前文可以得知,Galera Cluster可以實現叢集中資料的高度一致性,並且在每個節點上生成的Binlog順序都一樣,這與Galera內部實現的併發控制機制是分不開的。所有的上層到下層的同步、複製、執行、提交都通過併發控制機制來管理。這樣才能保證上層的邏輯性,下層資料的完整性等。
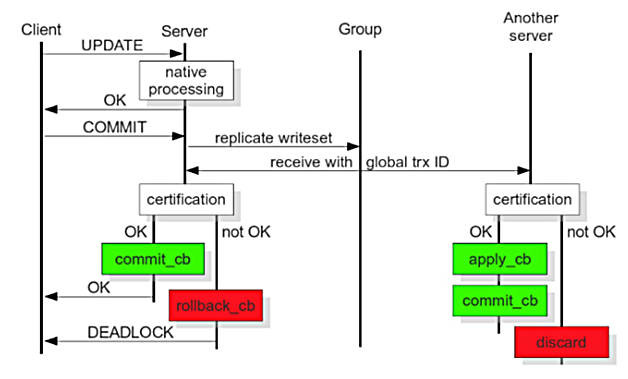
圖2擷取自官方手冊,從圖中可以大概看出,從事務執行開始,到本地執行,再到寫集傳送,再到寫集驗證,再到寫集提交的整個過程,以及從節點(相對)收到寫集後,所做的寫集驗證、寫集APPLY和寫集提交操作,通過對比該圖,可以很好地理解每一個階段的意義及效能等,下面就每一個階段以及其併發控制行為做一個簡單介紹:
- 本地執行
這個階段,是事務執行的最初階段,可以說,這個階段的執行過程,與單點MySQL執行沒什麼區別,併發控制當然就是資料庫的併發控制,而不是Galera Cluster的併發控制。
- 寫集傳送
執行完之後,就到了提交階段,提交之前首先將產生的寫集廣播出去,而為了保證全域性資料的一致性,在寫集傳送時,需要序列,這就屬於Galera Cluster併發控制的一部分。
- 寫集驗證
這個階段,就是我們通常說的Galera Cluster的驗證,驗證是將當前事務與本地寫集驗證快取集做驗證,通過比對寫集中被影響的資料庫KEYS,來發現有沒有相同的,來確定是不是可以驗證通過,那麼這個過程,也是序列的。
- 寫集提交
這個階段,是一個事務執行的最後一個階段,驗證完成後,就可以進入提交階段,因為此時已經執行完,而提交操作的併發控制可以通過引數來控制其行為,即參repl.commit_order,如果設定為3,表示提交就是序列的,而這也是本人所推薦的(預設值)一種設定,因為這樣的結果是,叢集中不同節點產生的Binlog完全一樣,運維中帶來了不少好處和方便。
- 寫集APPLY
這個階段,與上面的幾個在流程上不太一樣,這個階段是從節點做的事情,從節點只包括兩個階段,即寫集驗證和寫集APPLY,寫集APPLY的併發控制與引數wsrep_slave_threads有關,本身在驗證之後,確定相互的依賴關係,如果確定沒有關係,就可以並行,而並行度就是引數wsrep_slave_threads的事情了。wsrep_slave_threads可以參照引數wsrep_cert_deps_distance來設定。
流量控制
在PXC中,有一個引數叫fc_limit,它的作用是什麼呢?如果一套叢集中,某個節點,或者某幾個節點的硬體資源較差,或由於節點壓力大,導致複製效率低下等各種原因,其結果是:從節點APPLY時,速度非常慢,也就是說,主庫在1秒鐘之內做的操作,從庫有可能會用2秒才能完成,那麼這種情況下,就會導致從節點執行任務的堆積,接收佇列的堆積。
假設從節點真的堆積了,那麼Galera會讓它一直堆積下去嗎?這樣延遲會越來越嚴重,Galera Cluster將變成一個主從架構的叢集,已經失去了強一致狀態的屬性,那麼很明顯,Galera是不會讓這種事情發生的。此時就說回到開頭提到的引數gcs.fc_limit,這個引數在MySQL引數wsrep_provider_options中配置,是Galera的一個引數集合。有關於Flow Control的,還包括gcs.fc_factor,這兩個引數的意義是,當從節點堆積的事務數量超過gcs.fc_limit的值時,從節點發起一個Flow Control,而當從節點堆積的事務數小於gcs.fc_limit * gcs.fc_factor時,發起Flow Control的從節點再發起一個解除的訊息,讓整個叢集再恢復。
但我們關心的是如何解決,下面有幾個一般所採用的方法:
- 傳送FC訊息的節點,硬體有可能出現了問題,比如I/O寫不進去,很慢,CPU異常高等。
- 傳送FC訊息的節點,本身資料庫壓力太高,比如當前節點承載太多的讀,導致機器Load高,I/O壓力大等。
- 傳送FC訊息的節點,硬體壓力都沒有太大問題,但做得比較慢,一般原因是主庫併發高,但從節點的併發跟不上主庫,那麼此時可能需要觀察這兩個節點的併發度大小,可以參考狀態引數wsrep_cert_deps_distance的值,來調整從節點的wsrep_slave_threads,此時應該可以解決或緩解,這個問題可以這樣去理解,假設叢集每個節點的硬體資源都相當,那麼主庫可以執行完,從庫為什麼做不過來?那麼一般思路就是像處理主從複製的延遲問題一樣。
- 檢查存不存在沒有主鍵的表,因為Galera的複製是行模式的,所以如果存在這樣的表,主節點通過語句來修改,比如一個更新語句,更新了全表。而從節點收到之後,就會針對每一行的Binlog做一次全表掃描,這樣導致這個事務在從節點執行,比在主節點執行慢十倍,或者百倍,從而導致從節點堆積進而產生FC。
有很多坑?
有很多同學,在使用過Galera Cluster之後,發現很多問題,最大的比如DDL執行、大事務等,導致服務不友好,這也是很多人放棄的原因。
-
DDL執行卡死傳說:在Galera Cluster中執行一個大的改表操作,會導致整個叢集在一段時間內完全寫入不了任何事務,都卡死在那裡。這個情況確實很嚴重,導致線上完全不可服務,原因還是併發控制,因為提交操作設定為序列,DDL執行是一個提交過程,那麼序列執行改表,當然執行多久,就卡多久,直到改表執行完,其它事務也就可以繼續操作了。這個問題現在沒辦法解決,但我們長期使用下來發現,小表可以這樣直接操作,大一點或者更大的,都是通過OSC(pt-online-schema-change)來做。
-
擋我者死:由於Galera Cluster在執行DDL時,是Total Ordered Isolation(wsrep_OSU_method=TOI)的,所以必須要保證每個節點都同時執行,當然對於不是DDL的,也是Total Order的,因為每一個事務都具有同一個GTID值,DDL也不例外。而DDL涉及到的是表鎖,MDL鎖(Meta Data Lock),只要在執行過程中,遇到了MDL鎖的衝突,所有情況下,都是DDL優先,將所有使用到這個物件的事務,統統殺死。不管是讀事務,還是寫事務,被殺的事務都會報出死鎖異常。不過這點現在確實沒有辦法解決,也無法避免,不過其影響尚能接受,可以先忍忍。
-
不死之身:繼上面的“擋我者死”,如果叢集真的被一個DDL卡死了,導致整個叢集都動不了,所有的寫請求都Hang住了,那麼可能會有人想一個妙招——趕緊殺死,直接在每個節點上面輸入kill connection_id等類似的操作,那麼將報出很不願意看到的資訊:You are not owner of thread connection_id。此時可能有些同學要哭了,不過這種情況下,確實沒有什麼好的解決方法(其實這個時候,一個故障已經發生,一年的KPI也許已經沒有了,就看是否敢下狠手),其一是等DDL執行完成(所有這個資料庫上面的業務都處於不可服務狀態),否則就將資料庫直接Kill掉,快速重啟,趕緊恢復一個節點提交線上服務,然後再考慮叢集其它節點資料增量的同步等,這也是Galera Cluster中最大的一個坑,需要非常小心。
--------------------- 本文來自 jaryle 的CSDN 部落格 ,全文地址請點選:https://blog.csdn.net/jaryle/article/details/77848913?utm_source=copy