
啟動期間的記憶體管理之初始化過程概述----Linux記憶體管理(九)
在記憶體管理的上下文中, 初始化(initialization)可以有多種含義. 在許多CPU上, 必須顯式設定適用於Linux核心的記憶體模型. 例如在x86_32上需要切換到保護模式, 然後核心才能檢測到可用記憶體和暫存器.
而我們今天要講的boot階段就是系統初始化階段使用的記憶體分配器.
1 前景回顧
1.1 Linux記憶體管理的層次結構
Linux把實體記憶體劃分為三個層次來管理
| 層次 | 描述 |
|---|---|
| 儲存節點(Node) | CPU被劃分為多個節點(node), 記憶體則被分簇, 每個CPU對應一個本地實體記憶體, 即一個CPU-node對應一個記憶體簇bank,即每個記憶體簇被認為是一個節點 |
| 管理區(Zone) | 每個實體記憶體節點node被劃分為多個記憶體管理區域, 用於表示不同範圍的記憶體, 核心可以使用不同的對映方式對映實體記憶體 |
| 頁面(Page) | 記憶體被細分為多個頁面幀, 頁面是最基本的頁面分配的單位 | |
為了支援NUMA模型,也即CPU對不同記憶體單元的訪問時間可能不同,此時系統的實體記憶體被劃分為幾個節點(node), 一個node對應一個記憶體簇bank,即每個記憶體簇被認為是一個節點
首先, 記憶體被劃分為結點. 每個節點關聯到系統中的一個處理器, 核心中表示為
pg_data_t的例項. 系統中每個節點被連結到一個以NULL結尾的pgdat_list連結串列中<而其中的每個節點利用pg_data_tnode_next欄位連結到下一節.而對於PC這種UMA結構的機器來說, 只使用了一個成為contig_page_data的靜態pg_data_t結構.接著各個節點又被劃分為記憶體管理區域, 一個管理區域通過struct zone_struct描述, 其被定義為zone_t, 用以表示記憶體的某個範圍, 低端範圍的16MB被描述為ZONE_DMA, 某些工業標準體系結構中的(ISA)裝置需要用到它, 然後是可直接對映到核心的普通記憶體域ZONE_NORMAL,最後是超出了核心段的實體地址域ZONE_HIGHMEM, 被稱為高階記憶體. 是系統中預留的可用記憶體空間, 不能被核心直接對映.
最後頁幀(page frame)代表了系統記憶體的最小單位, 堆記憶體中的每個頁都會建立一個struct page的一個例項. 傳統上,把記憶體視為連續的位元組,即記憶體為位元組陣列,記憶體單元的編號(地址)可作為位元組陣列的索引. 分頁管理時,將若干位元組視為一頁,比如4K byte. 此時,記憶體變成了連續的頁,即記憶體為頁陣列,每一頁實體記憶體叫頁幀,以頁為單位對記憶體進行編號,該編號可作為頁陣列的索引,又稱為頁幀號.
1.2 記憶體結點pg_data_t
在LINUX中引入一個數據結構struct pglist_data ,來描述一個node,定義在include/linux/mmzone.h 檔案中。(這個結構被typedef pg_data_t)。
對於NUMA系統來講, 整個系統的記憶體由一個node_data的pg_data_t指標陣列來管理
對於PC這樣的UMA系統,使用struct pglist_data contig_page_data ,作為系統唯一的node管理所有的記憶體區域。(UMA系統中中只有一個node)
可以使用NODE_DATA(node_id)來查詢系統中編號為node_id的結點, 而UMA結構下由於只有一個結點, 因此該巨集總是返回全域性的contig_page_data, 而與引數node_id無關.
NODE_DATA(node_id)查詢編號node_id的結點pg_data_t資訊 參見NODE_DATA的定義
extern struct pglist_data *node_data[];
#define NODE_DATA(nid) (node_data[(nid)])- 1
- 2
在UMA結構的機器中, 只有一個node結點即contig_page_data, 此時NODE_DATA直接指向了全域性的contig_page_data, 而與node的編號nid無關, 參照include/linux/mmzone.h?v=4.7, line 858
extern struct pglist_data contig_page_data;
#define NODE_DATA(nid) (&contig_page_data)
- 1
- 2
- 3
1.2 實體記憶體區域
因為實際的計算機體系結構有硬體的諸多限制, 這限制了頁框可以使用的方式. 尤其是, Linux核心必須處理80x86體系結構的兩種硬體約束.
ISA匯流排的直接記憶體儲存DMA處理器有一個嚴格的限制 : 他們只能對RAM的前16MB進行定址
在具有大容量RAM的現代32位計算機中, CPU不能直接訪問所有的實體地址, 因為線性地址空間太小, 核心不可能直接對映所有實體記憶體到線性地址空間, 我們會在後面典型架構(x86)上記憶體區域劃分詳細講解x86_32上的記憶體區域劃分
因此Linux核心對不同區域的記憶體需要採用不同的管理方式和對映方式, 因此核心將實體地址或者成用zone_t表示的不同地址區域
對於x86_32的機器,管理區(記憶體區域)型別如下分佈
| 型別 | 區域 |
|---|---|
| ZONE_DMA | 0~15MB |
| ZONE_NORMAL | 16MB~895MB |
| ZONE_HIGHMEM | 896MB~實體記憶體結束 |
1.3 物理頁幀
核心把物理頁作為記憶體管理的基本單位. 儘管處理器的最小可定址單位通常是字, 但是, 記憶體管理單元MMU通常以頁為單位進行處理. 因此,從虛擬記憶體的上來看,頁就是最小單位.
頁幀代表了系統記憶體的最小單位, 對記憶體中的每個頁都會建立struct page的一個例項. 核心必須要保證page結構體足夠的小,否則僅struct page就要佔用大量的記憶體.
出於節省記憶體的考慮,struct page中使用了大量的聯合體union.
mem_map是一個struct page的陣列,管理著系統中所有的實體記憶體頁面。在系統啟動的過程中,建立和分配mem_map的記憶體區域, mem_map定義在mm/page_alloc.c?v=4.7, line 6691
UMA體系結構中,free_area_init函式在系統唯一的struct node物件contig_page_data中node_mem_map成員賦值給全域性的mem_map變數
1.6 今日內容(啟動過程中的記憶體初始化)
在初始化過程中, 還必須建立記憶體管理的資料結構, 以及很多事務. 因為核心在記憶體管理完全初始化之前就需要使用記憶體. 在系統啟動過程期間, 使用了額外的簡化悉尼股市的記憶體管理模組, 然後在初始化完成後, 將舊的模組丟棄掉.
因此我們可以把linux核心的記憶體管理分三個階段。
| 階段 | 起點 | 終點 | 描述 |
|---|---|---|---|
| 第一階段 | 系統啟動 | bootmem或者memblock初始化完成 | 此階段只能使用memblock_reserve函式分配記憶體, 早期核心中使用init_bootmem_done = 1標識此階段結束 |
| 第二階段 | bootmem或者memblock初始化完 | buddy完成前 | 引導記憶體分配器bootmem或者memblock接受記憶體的管理工作, 早期核心中使用mem_init_done = 1標記此階段的結束 |
| 第三階段 | buddy初始化完成 | 系統停止執行 | 可以用cache和buddy分配記憶體 |
系統啟動過程中的記憶體管理
首先我們來看看start_kernel是如何初始化系統的, start_kerne定義在init/main.c?v=4.7, line 479
其程式碼很複雜, 我們只截取出其中與記憶體管理初始化相關的部分, 如下所示
asmlinkage __visible void __init start_kernel(void)
{
/* 設定特定架構的資訊
* 同時初始化memblock */
setup_arch(&command_line);
mm_init_cpumask(&init_mm);
setup_per_cpu_areas();
/* 初始化記憶體結點和內段區域 */
build_all_zonelists(NULL, NULL);
page_alloc_init();
/*
* These use large bootmem allocations and must precede
* mem_init();
* kmem_cache_init();
*/
mm_init();
kmem_cache_init_late();
kmemleak_init();
setup_per_cpu_pageset();
rest_init();
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
| 函式 | 功能 |
|---|---|
| 是一個特定於體系結構的設定函式, 其中一項任務是負責初始化自舉分配器 | |
| 函式(檢視定義)給每個CPU分配記憶體,並拷貝.data.percpu段的資料. 為系統中的每個CPU的per_cpu變數申請空間.在SMP系統中, setup_per_cpu_areas初始化原始碼中(使用per_cpu巨集)定義的靜態per-cpu變數, 這種變數對系統中每個CPU都有一個獨立的副本. 此類變數儲存在核心二進位制影像的一個獨立的段中, setup_per_cpu_areas的目的就是為系統中各個CPU分別建立一份這些資料的副本在非SMP系統中這是一個空操作 | |
| 建立了核心的記憶體分配器, 其中通過mem_init停用bootmem分配器並遷移到實際的記憶體管理器(比如夥伴系統)然後呼叫kmem_cache_init函式初始化核心內部用於小塊記憶體區的分配器 | |
| 在kmem_cache_init之後, 完善分配器的快取機制, 當前3個可用的核心記憶體分配器slab, slob, slub都會定義此函式 | |
| Kmemleak工作於核心態,Kmemleak 提供了一種可選的核心洩漏檢測,其方法類似於跟蹤記憶體收集器。當獨立的物件沒有被釋放時,其報告記錄在 /sys/kernel/debug/kmemleak中, Kmemcheck能夠幫助定位大多數記憶體錯誤的上下文 | |
| 初始化CPU快取記憶體行, 為pagesets的第一個陣列元素分配記憶體, 換句話說, 其實就是第一個系統處理器分配由於在分頁情況下,每次儲存器訪問都要存取多級頁表,這就大大降低了訪問速度。所以,為了提高速度,在CPU中設定一個最近存取頁面的快取記憶體硬體機制,當進行儲存器訪問時,先檢查要訪問的頁面是否在快取記憶體中. |
2 第一階段(啟動過程中的記憶體管理)
記憶體管理是作業系統資源管理的重點, 但是在作業系統初始化的初期, 作業系統只是獲取到了記憶體的基本資訊, 但是記憶體管理的資料結構都沒有建立, 而我們這些資料結構建立的過程本身就是一個記憶體分配的過程, 那麼就出現一個問題
我們還沒有一個記憶體管理器去負責分配和回收記憶體, 而我們又不可能將所有的記憶體資訊都靜態建立並初始化, 那麼我們怎麼分配記憶體管理器所需要的記憶體呢? 現在我們進入了一個先有雞還是先有蛋的怪圈, 這種問題的一般解決方法是, 我們先實現一個滿足要求的但是可能效率不高的笨傢伙(記憶體管理器), 用它來負責系統初始化初期的記憶體管理, 最重要的, 用它來初始化我們記憶體的資料結構, 直到我們真正的記憶體管理器被初始化完成並能投入使用, 我們將舊的記憶體管理器丟掉
即因此在系統啟動過程期間, 核心使用了一個額外的簡化形式的記憶體管理模組早期的引導記憶體分配器(boot memory allocator–bootmem分配器)或者memblock, 用於在啟動階段早期分配記憶體, 而在系統初始化完成後, 該分配器被核心拋棄, 然後初始化了一套新的更加完善的記憶體分配器.
2.1 引導記憶體分配器bootmem
在啟動過程期間, 儘管記憶體管理尚未初始化, 但是核心仍然需要分配記憶體以建立各種資料結構, 早期的核心中負責初始化階段的記憶體分配器稱為引導記憶體分配器(boot memory allocator–bootmem分配器), 在耳熟能詳的夥伴系統建立前記憶體都是利用分配器來分配的,夥伴系統框架建立起來後,bootmem會過度到夥伴系統. 顯然, 對該記憶體分配器的需求集中於簡單性方面, 而不是效能和通用性, 它僅用於初始化階段. 因此核心開發者決定實現一個最先適配(first-first)分配器用於在啟動階段管理記憶體. 這是可能想到的最簡單的方式.
引導記憶體分配器(boot memory allocator–bootmem分配器)基於最先適配(first-first)分配器的原理(這兒是很多系統的記憶體分配所使用的原理), 使用一個位圖來管理頁, 以點陣圖代替原來的空閒連結串列結構來表示儲存空間, 點陣圖的位元位的數目與系統中實體記憶體頁面數目相同. 若點陣圖中某一位是1, 則標識該頁面已經被分配(已用頁), 否則表示未被佔有(未用頁).
在需要分配記憶體時, 分配器逐位的掃描點陣圖, 直至找到一個能提供足夠連續頁的位置, 即所謂的最先最佳(first-best)或最先適配位置.該分配機制通過記錄上一次分配的頁面幀號(PFN)結束時的偏移量來實現分配大小小於一頁的空間, 連續的小的空閒空間將被合併儲存在一頁上.
即使是初始化用的最先適配分配器也必須使用一些資料結構存, 核心為系統中每一個結點都提供了一個struct bootmem_data結構的例項, 用於bootmem的記憶體管理. 它含有引導記憶體分配器給結點分配記憶體時所需的資訊. 當然, 這時候記憶體管理還沒有初始化, 因而該結構所需的記憶體是無法動態分配的, 必須在編譯時分配給核心.
在UMA系統上該分配的實現與CPU無關, 而NUMA系統記憶體結點與CPU相關聯, 因此採用了特定體系結構的解決方法.
關於引導記憶體分配器的具體內容, 請參見另外一篇博文
2.2 memblock記憶體分配器
但是bootmem也有很多問題. 最明顯的就是外碎片的問題, 因此核心維護了memblock記憶體分配器, 同時用memblock實現了一份bootmem相同的相容API, 即nobootmem, Memblock以前被定義為Logical Memory Block( 邏輯記憶體塊), 但根據Yinghai Lu的補丁, 它被重新命名為memblock. 並最終替代bootmem成為初始化階段的記憶體管理器
關於引導記憶體分配器的具體內容, 請參見另外一篇博文
2.3 兩者的區別與聯絡
bootmem是通過點陣圖來管理,點陣圖存在地地址段, 而memblock是在高地址管理記憶體, 維護兩個連結串列, 即memory和reserved
memory連結串列維護系統的記憶體資訊(在初始化階段通過bios獲取的), 對於任何記憶體分配, 先去查詢memory連結串列, 然後在reserve連結串列上記錄(新增一個節點,或者合併)
兩者都可以分配小於一頁的記憶體;
兩者都是就近查詢可用的記憶體, bootmem是從低到高找, memblock是從高往低找;
在boot傳遞給kernel memory bank相關資訊後,kernel這邊會以memblcok的方式儲存這些資訊,當buddy system 沒有起來之前,在kernel中也是要有一套機制來管理memory的申請和釋放.
Kernel可以選擇nobootmem 或者bootmem 來在buddy system起來之前管理memory. 這兩種機制對提供的API是一致的,因此對使用者是透明的
ifdef CONFIG_NO_BOOTMEM
obj-y += nobootmem.o
else
obj-y += bootmem.o
endif- 1
- 2
- 3
- 4
- 5
由於介面是一致的, 那麼他們共同使用一份
2.4 memblock的初始化(arm64架構)
前面我們的核心從start_kernel開始, 進入setup_arch(), 並完成了早期記憶體分配器的初始化和設定工作.
void __init setup_arch(char **cmdline_p)
{
/* 初始化memblock */
arm64_memblock_init( );
/* 分頁機制初始化 */
paging_init();
bootmem_init();
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
其中arm64_memblock_init就完成了arm64架構下的memblock的初始化
3 第二階段(初始化buddy記憶體管理)
在arm64架構下, 核心在start_kernel()->setup_arch()函式中依次完成了如下工作
前面我們的核心從start_kernel開始, 進入setup_arch(), 並完成了早期記憶體分配器的初始化和設定工作.
void __init setup_arch(char **cmdline_p)
{
/* 初始化memblock */
arm64_memblock_init( );
/* 分頁機制初始化 */
paging_init();
bootmem_init();
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
其中arm64_memblock_init就完成了arm64架構下的memblock的初始化.
而setup_arch則主要完成如下工作
呼叫arm64_memblock_init來完成了memblock的初始化
paging_init初始化記憶體的分頁機制
bootmem_init初始化記憶體管理
3.1 初始化流程
下面我們就以arm64架構來分析bootmem初始化記憶體結點和記憶體域的過程, 在講解的過程中我們會兼顧的考慮arm64架構下的異同
在setup_arch函式內, 通過paging_init函式初始化了分頁機制和頁表的資訊
接著paging_init函式通過bootmem_init開始進行初始化工作
arm64在整個初始化的流程上並沒有什麼不同, 但是有細微的差別
由於arm是在後期才開始加入了MMU記憶體管理單元的, 因此核心必須實現mmu和nonmmu兩套不同的程式碼, 這主要是提現在分頁機制的不同上, 因而paging_init分別定義了arch/arm/mm/nommu.c和arch/arm/mm/mmu.c兩個版本, 但是它們均呼叫了bootmem_init來完成初始化
也是因為上面的原因, arm上paging_init有兩份程式碼(mmu和nonmmu), 為了降低程式碼的耦合性, arm通過setup_arch呼叫paging_init函式, 後者進一步呼叫了bootmem_init來完成, 而arm64上不存在這樣的問題, 則在setup_arch中順序的先用paging_init初始化了頁表, 然後setup_arch又呼叫bootmem_init來完成了bootmem的初始化
3.2 paging_init初始化分頁機制
paging_init負責建立只能用於核心的頁表, 使用者空間是無法訪問的. 這對管理普通應用程式和核心訪問記憶體的方式,有深遠的影響
因此在仔細考察其實現之前,很重要的一點是解釋該函式的目的。
在x86_32系統上核心通常將總的4GB可用虛擬地址空間按3:1的比例劃分給使用者空間和核心空間, 虛擬地址空間的低端3GB 用於使用者狀態應用程式, 而高階的1GB則專用於核心. 儘管在分配核心的虛擬地址空間時, 當前系統上下文是不相干的, 但每個程序都有自身特定的地址空間.
這些劃分主要的動機如下所示
在使用者應用程式的執行切換到核心態時(這總是會發生,例如在使用系統呼叫或發生週期性的時鐘中斷時),核心必須裝載在一個可靠的環境中。因此有必要將地址空間的一部分分配給核心專用.
實體記憶體頁則對映到核心地址空間的起始處,以便核心直接訪問,而無需複雜的頁表操作.
如果所有實體記憶體頁都對映到使用者空間程序能訪問的地址空間中, 如果在系統上有幾個應用程式在執行, 將導致嚴重的安全問題. 每個應用程式都能夠讀取和修改其他程序在實體記憶體中的記憶體區. 顯然必須不惜任何代價防止這種情況出現.
雖然用於使用者層程序的虛擬地址部分隨程序切換而改變,但是核心部分總是相同的
3.3 虛擬地址空間(以x86_32位系統為例)
出於記憶體保護等一系列的考慮, 核心將整個程序的虛擬執行空間劃分為核心虛擬執行空間和核心虛擬執行空間
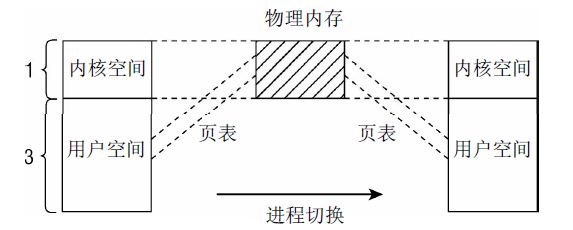
按3:1的比例劃分地址空間, 只是約略反映了核心中的情況,核心地址空間作為核心的常駐虛擬地址空間, 自身又分為各個段
地址空間的第一段用於將系統的所有實體記憶體頁對映到核心的虛擬地址空間中。由於核心地址空間從偏移量0xC0000000開始,即經常提到的3 GiB,每個虛擬地址x都對應於物理地址x—0xC0000000,因此這是一個簡單的線性平移。
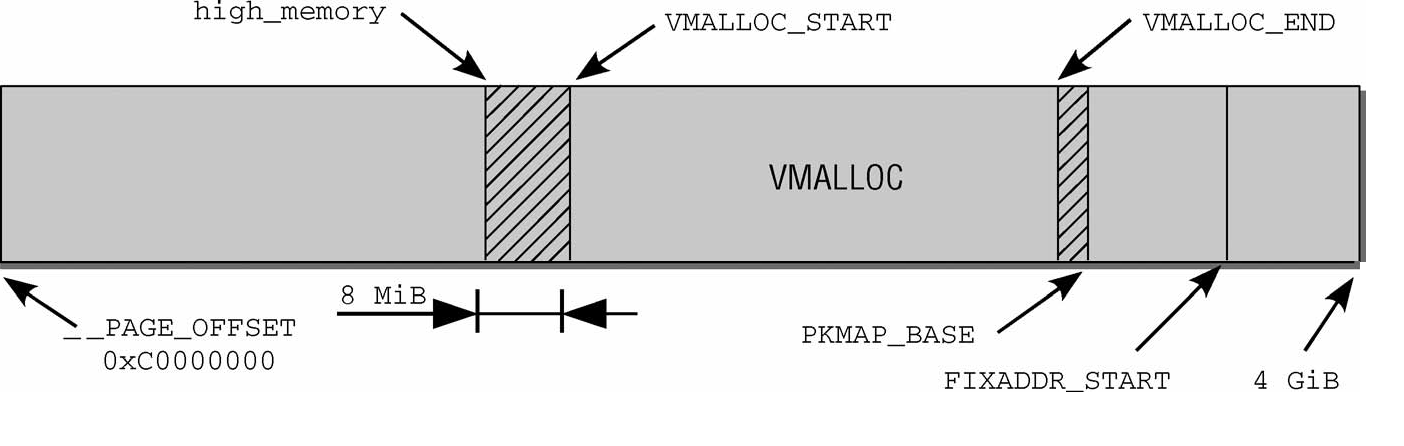
直接對映區域從0xC0000000到high_memory地址,high_memory準確的數值稍後討論。第1章提到過,這種方案有一問題。由於核心的虛擬地址空間只有1 GiB,最多隻能對映1 GiB實體記憶體。IA-32系統(沒有PAE)最大的記憶體配置可以達到4 GiB,引出的一個問題是,如何處理剩下的記憶體?
這裡有個壞訊息。如果實體記憶體超過896 MiB,則核心無法直接對映全部實體記憶體。該值甚至比此前提到的最大限制1 GiB還小,因為核心必須保留地址空間最後的128 MiB用於其他目的,我會稍後解釋。將這128 MiB加上直接對映的896 MiB記憶體,則得到核心虛擬地址空間的總數為1 024 MiB = 1GiB。核心使用兩個經常使用的縮寫normal和highmem,來區分是否可以直接對映的頁幀.
核心地址空間的最後128 MiB用於何種用途呢?如圖3-15所示,該部分有3個用途.
虛擬記憶體中連續、但實體記憶體中不連續的記憶體區,可以在vmalloc區域分配。該機制通常用於使用者過程,核心自身會試圖盡力避免非連續的實體地址。核心通常會成功,因為大部分大的記憶體塊都在啟動時分配給核心,那時記憶體的碎片尚不嚴重。但在已經運行了很長時間的系統上,在核心需要實體記憶體時,就可能出現可用空間不連續的情況。此類情況,主要出現在動態載入模組時
持久對映用於將高階記憶體域中的非持久頁對映到核心中
固定對映是與實體地址空間中的固定頁關聯的虛擬地址空間項,但具體關聯的頁幀可以自由 選擇。它與通過固定公式與實體記憶體關聯的直接對映頁相反,虛擬固定對映地址與實體記憶體位置之間 的關聯可以自行定義,關聯建立後核心總是會注意到的
同樣我們的使用者空間, 也被劃分為幾個段, 包括從高地址到低地址分別為 :
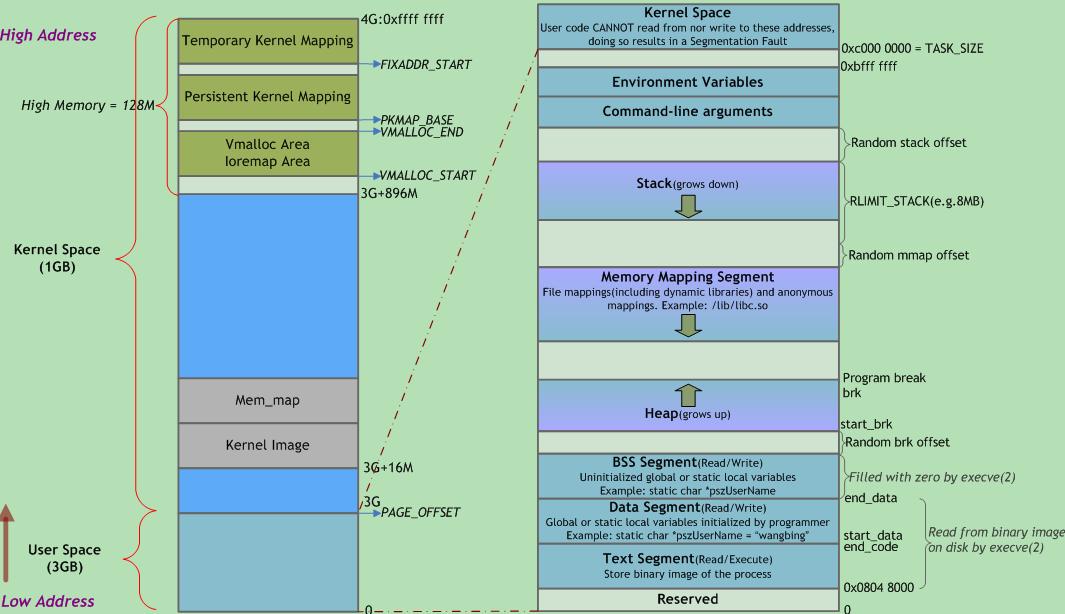
| 區域 | 儲存內容 |
|---|---|
| 棧 | 區域性變數, 函式引數, 返回地址等 |
| 堆 | 動態分配的記憶體 |
| BSS段 | 未初始化或初值為0的全域性變數和靜態區域性變數 |
| 資料段 | 一初始化且初值非0的全域性變數和靜態區域性變數 |
| 程式碼段 | 可執行程式碼, 字串面值, 只讀變數 |
3.4 bootmem_init初始化記憶體的基礎資料結構(結點pg_data, 記憶體域zone, 頁面page)
在paging_init之後, 系統的頁幀已經建立起來, 然後通過bootmem_init中, 系統開始完成bootmem的初始化工作.
不同的體系結構bootmem_init的實現, 沒有很大的區別, 但是在初始化的過程中, 其中的很多函式, 依據系統是NUMA還是UMA結構則有不同的定義
bootmem_init函式的實現如下
3.5 build_all_zonelists初始化每個記憶體節點的zonelists
核心setup_arch的最後通過bootmem_init中完成了記憶體資料結構的初始化(包括記憶體結點pg_data_t, 記憶體管理域zone和頁面資訊page), 資料結構已經基本準備好了, 在後面為記憶體管理做得一個準備工作就是將所有節點的管理區都鏈入到zonelist中,便於後面記憶體分配工作的進行.
記憶體節點pg_data_t中將記憶體節點中的記憶體區域zone按照某種組織層次儲存在一個zonelist中, 即pglist_data->node_zonelists成員資訊
// http://lxr.free-electrons.com/source/include/linux/mmzone.h?v=4.7#L626
typedef struct pglist_data
{
struct zone node_zones[MAX_NR_ZONES];
struct zonelist node_zonelists[MAX_ZONELISTS];
}- 1
- 2
- 3
- 4
- 5
- 6
核心定義了記憶體的一個層次結構關係, 首先試圖分配廉價的記憶體,如果失敗,則根據訪問速度和容量,逐漸嘗試分配更昂貴的記憶體.
高階記憶體最廉價, 因為核心沒有任何部分依賴於從該記憶體域分配的記憶體, 如果高階記憶體用盡, 對核心沒有副作用, 所以優先分配高階記憶體
普通記憶體域的情況有所不同, 許多核心資料結構必須儲存在該記憶體域, 而不能放置到高階記憶體域, 因此如果普通記憶體域用盡, 那麼核心會面臨記憶體緊張的情況
DMA記憶體域最昂貴,因為它用於外設和系統之間的資料傳輸。 舉例來講,如果核心指定想要分配高階記憶體域。它首先在當前結點的高階記憶體域尋找適當的空閒記憶體段,如果失敗,則檢視該結點的普通記憶體域,如果還失敗,則試圖在該結點的DMA記憶體域分配。如果在3個本地記憶體域都無法找到空閒記憶體,則檢視其他結點。這種情況下,備選結點應該儘可能靠近主結點,以最小化訪問非本地記憶體引起的效能損失。
4 總結
4.1 start_kernel啟動流程
start_kernel()
|---->page_address_init()
| 考慮支援高階記憶體
| 業務:初始化page_address_pool連結串列;
| 將page_address_maps陣列元素按索引降序插入
| page_address_pool連結串列;
| 初始化page_address_htable陣列.
|
|---->setup_arch(&command_line);
| 初始化特定體系結構的內容
|---->arm64_memblock_init( ); [參見memblock和bootmem]
| 初始化引導階段的記憶體分配器memblock
|
|---->paging_init(); [參見分頁機制初始化paging_init]
| 分頁機制初始化
|
|---->bootmem_init(); [與build_all_zonelist共同完成記憶體資料結構的初始化]
| 初始化記憶體資料結構包括記憶體節點和記憶體域
|
|---->setup_per_cpu_areas();
| 為per-CPU變數分配空間
|
|---->build_all_zonelist() [bootmem_init初始化資料結構, 該函式初始化zonelists]
| 為系統中的zone建立後備zone的列表.
| 所有zone的後備列表都在
| pglist_data->node_zonelists[0]中;
|
| 期間也對per-CPU變數boot_pageset做了初始化.
|
|---->page_alloc_init()
|---->hotcpu_notifier(page_alloc_cpu_notifier, 0);
| 不考慮熱插拔CPU
|
|---->pidhash_init()
| 詳見下文.
| 根據低端記憶體頁數和雜湊度,分配hash空間,並賦予pid_hash
|
|---->vfs_caches_init_early()
|---->dcache_init_early()
| dentry_hashtable空間,d_hash_shift, h_hash_mask賦值;
| 同pidhash_init();
| 區別:
| 雜湊度變化了(13 - PAGE_SHIFT);
| 傳入alloc_large_system_hash的最後引數值為0;
|
|---->inode_init_early()
| inode_hashtable空間,i_hash_shift, i_hash_mask賦值;
| 同pidhash_init();
| 區別:
| 雜湊度變化了(14 - PAGE_SHIFT);
| 傳入alloc_large_system_hash的最後引數值為0;
|- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
4.2 體系結構相關的初始化工作setup_arch
setup_arch(char **cmdline_p)
|---->arm64_memblock_init( );
| 初始化引導階段的記憶體分配器memblock
|
|
|---->paging_init();
| 分頁機制初始化
|
|
|---->bootmem_init();
| 初始化記憶體資料結構包括記憶體節點和記憶體域
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
4.3 bootmem_init初始化記憶體的基礎資料結構(結點pg_data, 記憶體域zone, 頁面page)
bootmem_init(void)
|---->min = PFN_UP(memblock_start_of_DRAM());
|---->max = PFN_DOWN(memblock_end_of_DRAM());
|
|
|---->arm64_numa_init();
| 支援numa架構
|---->arm64_numa_init();
| 支援numa架構
|
|
|---->zone_sizes_init(min, max);
來初始化節點和管理區的一些資料項
|
|---->free_area_init_node
| 初始化記憶體節點
|
|
|---->free_area_init_core初始化zone
|
|
|---->memmap_init初始化page頁面
|
|
|
|---->memblock_dump_all();
| 初始化完成, 顯示memblock的保留的所有記憶體資訊- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
4.4 build_all_zonelists初始化每個記憶體節點的zonelists
void build_all_zonelists(void)
|---->set_zonelist_order()
|---->current_zonelist_order = ZONELIST_ORDER_ZONE;
|
|---->__build_all_zonelists(NULL);
| Memory不支援熱插拔, 為每個zone建立後備的zone,
| 每個zone及自己後備的zone,形成zonelist
|
|---->pg_data_t *pgdat = NULL;
| pgdat = &contig_page_data;(單node)
|
|---->build_zonelists(pgdat);
| 為每個zone建立後備zone的列表
|
|---->struct zonelist *zonelist = NULL;
| enum zone_type j;
| zonelist = &pgdat->node_zonelists[0];
|
|---->j = build_zonelists_node(pddat, zonelist, 0, MAX_NR_ZONES - 1);
| 為pgdat->node_zones[0]建立後備的zone,node_zones[0]後備的zone
| 儲存在node_zonelist[0]內,對於node_zone[0]的後備zone,其後備的zone
| 連結串列如下(只考慮UMA體系,而且不考慮ZONE_DMA):
| node_zonelist[0]._zonerefs[0].zone = &node_zones[2];
| node_zonelist[0]._zonerefs[0].zone_idx = 2;
| node_zonelist[0]._zonerefs[1].zone = &node_zones[1];
| node_zonelist[0]._zonerefs[1].zone_idx = 1;
| node_zonelist[0]._zonerefs[2].zone = &node_zones[0];
| node_zonelist[0]._zonerefs[2].zone_idx = 0;
|
| zonelist->_zonerefs[3].zone = NULL;
| zonelist->_zonerefs[3].zone_idx = 0;
|
|---->build_zonelist_cache(pgdat);
|---->pdat->node_zonelists[0].zlcache_ptr = NULL;
| UMA體系結構
|
|---->for_each_possible_cpu(cpu)
| setup_pageset(&per_cpu(boot_pageset, cpu), 0);
|詳見下文
|---->vm_total_pages = nr_free_pagecache_pages();
| 業務:獲得所有zone中的present_pages總和.
|
|---->page_group_by_mobility_disabled = 0;
| 對於程式碼中的判斷條件一般不會成立,因為頁數會最夠多(記憶體較大)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44