
全面瞭解mysql中utf8和utf8mb4的區別
一.簡介
MySQL在5.5.3之後增加了這個utf8mb4的編碼,mb4就是most bytes 4的意思,專門用來相容四位元組的unicode。好在utf8mb4是utf8的超集,除了將編碼改為utf8mb4外不需要做其他轉換。當然,為了節省空間,一般情況下使用utf8也就夠了。
二.內容描述
那上面說了既然utf8能夠存下大部分中文漢字,那為什麼還要使用utf8mb4呢? 原來mysql支援的 utf8 編碼最大字元長度為 3 位元組,如果遇到 4 位元組的寬字元就會插入異常了。三個位元組的 UTF-8 最大能編碼的 Unicode 字元是 0xffff,也就是 Unicode 中的基本多文種平面(BMP)。也就是說,任何不在基本多文字平面的 Unicode字元,都無法使用 Mysql 的 utf8 字符集儲存。包括 Emoji 表情(Emoji 是一種特殊的 Unicode 編碼,常見於 ios 和 android 手機上),和很多不常用的漢字,以及任何新增的 Unicode 字元等等。
三.問題根源
最初的 UTF-8 格式使用一至六個位元組,最大能編碼 31 位字元。最新的 UTF-8 規範只使用一到四個位元組,最大能編碼21位,正好能夠表示所有的 17個 Unicode 平面。 utf8 是 Mysql 中的一種字符集,只支援最長三個位元組的 UTF-8字元,也就是 Unicode 中的基本多文字平面。 Mysql 中的 utf8 為什麼只支援持最長三個位元組的 UTF-8字元呢?可能是因為 Mysql 剛開始開發那會,Unicode 還沒有輔助平面這一說呢。那時候,Unicode 委員會還做著 “65535 個字元足夠全世界用了”的美夢。Mysql 中的字串長度算的是字元數而非位元組數,對於 CHAR 資料型別來說,需要為字串保留足夠的長。當使用 utf8 字符集時,需要保留的長度就是 utf8 最長字元長度乘以
四.utf8升級utf8mb4問題
utf8mb4 字符集(4位元組 UTF-8 Unicode 編碼) UTF-8字符集每個字元最多使用三個位元組,並且只包含基本多語言面 (Basic Multilingual Plane,BMP)字元。 utf8mb4 字符集使用最多每字元四個位元組支援補充字元: 對於 BMP字元 UTF8 和 utf8mb4 具有相同的儲存特性:相同的程式碼值,相同的編碼,相同的長度。 對於補充字元,UTF8不能儲存所有的字元,而utf8mb4需要四個位元組來儲存它。因為UTF8不能儲存所有的字元,你的 utf8 列中都沒有補充字元,因此從舊版本的MySQL UTF8 升級資料時 不用擔心字元轉換或丟失資料。 utf8mb4 是 utf8 的超集,所以像下面的連線字串操作,其結果字符集是 utf8mb4 排序規則(一組規則,定義如何對字串進行比較和排序)是 utf8mb4_col:
SELECT CONCAT(utf8_col, utf8mb4_col); 同樣,下面的 WHERE 子句中的內容比較根據 utf8mb4_col 規則:
SELECT * FROM utf8_tbl, utf8mb4_tbl
WHERE utf8_tbl.utf8_col = utf8mb4_tbl.utf8mb4_col; 如上面所說到的: 要使用 utf8mb4 節省空間,使用 VARCHAR 替換 CHAR。否則,MySQL必須為使用 utf8mb4字符集的列的每一個字元保留四位元組的空間,因為其最大長度可能是四位元組。例如,MySQL必須為一個使用 utf8mb4 字符集的 char(10)的列保留40位元組空間。
五.utf8升級utf8mb4具體步驟
首先將我們資料庫預設字符集由utf8 更改為utf8mb4,對應的表預設字符集也更改為utf8mb4 已經儲存表情的欄位預設字符集也做了相應的調整。
SQL 語句
1 # 修改資料庫:
2 ALTER DATABASE database_name CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci;
3 # 修改表:
4 ALTER TABLE table_name CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
5 # 修改表字段:
6 ALTER TABLE table_name CHANGE column_name column_name VARCHAR(191) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci; 修改MySQL配置檔案
新增如下引數:
default-character-set = utf8mb4
default-character-set = utf8mb4
character-set-client-handshake = FALSE
character-set-server = utf8mb4
collation-server = utf8mb4_unicode_ci
init_connect='SET NAMES utf8mb4'檢查環境變數 和測試 SQL 如下:
SHOW VARIABLES WHERE Variable_name LIKE 'character\_set\_%' OR Variable_name LIKE 'collation%'; 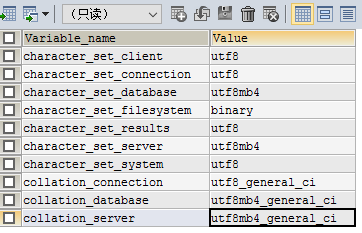 注意:MySQL版本必須為5.5.3以上版本,否則不支援字符集utf8mb4
注意:MySQL版本必須為5.5.3以上版本,否則不支援字符集utf8mb4
六.建議
建議普通表使用utf8, 如果這個表需要支援emoji就使用utf8mb4 新建mysql庫或者表的時候還有一個排序規則 utf8_unicode_ci比較準確,utf8_general_ci速度比較快。通常情況下 utf8_general_ci的準確性就夠我們用的了,在我看過很多程式原始碼後,發現它們大多數也用的是utf8_general_ci,所以新建資料 庫時一般選用utf8_general_ci就可以了 如果是utf8mb4那麼對應的就是 utf8mb4_general_ci utf8mb4_unicode_ci
七.utf8_unicode_ci與utf8_general_ci的區別
當前,utf8_unicode_ci校對規則僅部分支援Unicode校對規則演算法。一些字元還是不能支援。並且,不能完全支援組合的記號。這主要影響越南和俄羅斯的一些少數民族語言,如:Udmurt 、Tatar、Bashkir和Mari。
utf8_unicode_ci的最主要的特色是支援擴充套件,即當把一個字母看作與其它字母組合相等時。例如,在德語和一些其它語言中‘ß’等於‘ss’。
utf8_general_ci是一個遺留的 校對規則,不支援擴充套件。它僅能夠在字元之間進行逐個比較。這意味著utf8_general_ci校對規則進行的比較速度很快,但是與使用utf8_unicode_ci的校對規則相比,比較正確性較差)。
例如,使用utf8_general_ci和utf8_unicode_ci兩種 校對規則下面的比較相等:
Ä = A
Ö = O
Ü = U
兩種校對規則之間的區別是,對於utf8_general_ci下面的等式成立:
ß = s
但是,對於utf8_unicode_ci下面等式成立:
ß = ss
對於一種語言僅當使用utf8_unicode_ci排序做的不好時,才執行與具體語言相關的utf8字符集 校對規則。例如,對於德語和法語,utf8_unicode_ci工作的很好,因此不再需要為這兩種語言建立特殊的utf8校對規則。
utf8_general_ci也適用與德語和法語,除了‘ß’等於‘s’,而不是‘ss’之外。如果你的應用能夠接受這些,那麼應該使用utf8_general_ci,因為它速度快。否則,使用utf8_unicode_ci,因為它比較準確。
八.案例
查詢:CREATE TABLE test_session ( sessionId varchar(255) NOT NULL, userId int(10) unsigned DEFAULT NULL, createAt datetime DEFAULT NULL,...
錯誤程式碼: 1071
Specified key was too long; max key length is 767 bytes如上,報錯,當使用utf8mb4編碼後,主鍵id的長度設定255,太長,只能設定小於191的
其中:
max key length is 767 bytes
utf8: 767/3=255.6666666666667
utf8mb4: 767/4=191.75九.深入Mysql字符集設定
基本概念
• 字元(Character)是指人類語言中最小的表義符號。例如’A'、’B'等;
• 給定一系列字元,對每個字元賦予一個數值,用數值來代表對應的字元,這一數值就是字元的編碼(Encoding)。例如,我們給字元’A'賦予數值0,給字元’B'賦予數值1,則0就是字元’A'的編碼;
• 給定一系列字元並賦予對應的編碼後,所有這些字元和編碼對組成的集合就是字符集(Character Set)。例如,給定字元列表為{‘A’,'B’}時,{‘A’=>0, ‘B’=>1}就是一個字符集;
• 字元序(Collation)是指在同一字符集內字元之間的比較規則;
• 確定字元序後,才能在一個字符集上定義什麼是等價的字元,以及字元之間的大小關係;
• 每個字元序唯一對應一種字符集,但一個字符集可以對應多種字元序,其中有一個是預設字元序(Default Collation);
• MySQL中的字元序名稱遵從命名慣例:以字元序對應的字符集名稱開頭;以_ci(表示大小寫不敏感)、_cs(表示大小寫敏感)或_bin(表示按編碼值比較)結尾。例如:在字元序“utf8_general_ci”下,字元“a”和“A”是等價的;
MySQL字符集設定
• 系統變數:
– character_set_server:預設的內部操作字符集
– character_set_client:客戶端來源資料使用的字符集
– character_set_connection:連線層字符集
– character_set_results:查詢結果字符集
– character_set_database:當前選中資料庫的預設字符集
– character_set_system:系統元資料(欄位名等)字符集
– 還有以collation_開頭的同上面對應的變數,用來描述字元序。
• 用introducer指定文字字串的字符集:
– 格式為:[_charset] ‘string’ [COLLATE collation]
– 例如:
• SELECT _latin1 ‘string’;
• SELECT _utf8 ‘你好’ COLLATE utf8_general_ci;
– 由introducer修飾的文字字串在請求過程中不經過多餘的轉碼,直接轉換為內部字符集處理。
MySQL中的字符集轉換過程
1. MySQL Server收到請求時將請求資料從character_set_client轉換為character_set_connection;
2. 進行內部操作前將請求資料從character_set_connection轉換為內部操作字符集,其確定方法如下:
• 使用每個資料欄位的CHARACTER SET設定值;
• 若上述值不存在,則使用對應資料表的DEFAULT CHARACTER SET設定值(MySQL擴充套件,非SQL標準);
• 若上述值不存在,則使用對應資料庫的DEFAULT CHARACTER SET設定值;
• 若上述值不存在,則使用character_set_server設定值。
3. 將操作結果從內部操作字符集轉換為character_set_results。
常見問題解析
• 向預設字符集為utf8的資料表插入utf8編碼的資料前沒有設定連線字符集,查詢時設定連線字符集為utf8
– 插入時根據MySQL伺服器的預設設定,character_set_client、character_set_connection和character_set_results均為latin1;
– 插入操作的資料將經過latin1=>latin1=>utf8的字符集轉換過程,這一過程中每個插入的漢字都會從原始的3個位元組變成6個位元組儲存;
– 查詢時的結果將經過utf8=>utf8的字符集轉換過程,將儲存的6個位元組原封不動返回,產生亂碼……
• 向預設字符集為latin1的資料表插入utf8編碼的資料前設定了連線字符集為utf8
– 插入時根據連線字符集設定,character_set_client、character_set_connection和character_set_results均為utf8;
– 插入資料將經過utf8=>utf8=>latin1的字符集轉換,若原始資料中含有\u0000~\u00ff範圍以外的Unicode字 符,會因為無法在latin1字符集中表示而被轉換為“?”(0x3F)符號,以後查詢時不管連線字符集設定如何都無法恢復其內容了。
檢測字符集問題的一些手段
• SHOW CHARACTER SET;
• SHOW COLLATION;
• SHOW VARIABLES LIKE ‘character%’;
• SHOW VARIABLES LIKE ‘collation%’;
• SQL函式HEX、LENGTH、CHAR_LENGTH
• SQL函式CHARSET、COLLATION
使用MySQL字符集時的建議
• 建立資料庫/表和進行資料庫操作時儘量顯式指出使用的字符集,而不是依賴於MySQL的預設設定,否則MySQL升級時可能帶來很大困擾;
• 資料庫和連線字符集都使用latin1時雖然大部分情況下都可以解決亂碼問題,但缺點是無法以字元為單位來進行SQL操作,一般情況下將資料庫和連線字符集都置為utf8是較好的選擇;
• 使用mysql C API時,初始化資料庫控制代碼後馬上用mysql_options設定MYSQL_SET_CHARSET_NAME屬性為utf8,這樣就不用顯式地用 SET NAMES語句指定連線字符集,且用mysql_ping重連斷開的長連線時也會把連線字符集重置為utf8;
• 對於mysql PHP API,一般頁面級的PHP程式總執行時間較短,在連線到資料庫以後顯式用SET NAMES語句設定一次連線字符集即可;但當使用長連線時,請注意保持連線通暢並在斷開重連後用SET NAMES語句顯式重置連線字符集。
其他注意事項
• my.cnf中的default_character_set設定隻影響mysql命令連線伺服器時的連線字符集,不會對使用libmysqlclient庫的應用程式產生任何作用!
• 對欄位進行的SQL函式操作通常都是以內部操作字符集進行的,不受連線字符集設定的影響。
• SQL語句中的裸字串會受到連線字符集或introducer設定的影響,對於比較之類的操作可能產生完全不同的結果,需要小心!