
併發程式設計3:執行緒池的使用與執行流程
併發程式設計系列的文章醞釀好久了,但由於沒有時間和毅力去寫那麼多練習 demo,很多文章寫了一半就停止了。
在寫某一系列的過程中總有其他想寫的內容蹦出來,想忍住不分散精力太難了,所以我很佩服那些能專心研究、總結一個專題的人,他們是有毅力的人!
關於學習的方式我也困惑過很久,究竟是知識體系驅動還是專案驅動比較好呢?
- 知識體系驅動即一條道走到頭的學習(逮住某個專題深入研究,直到整個過一遍)
- 專案驅動即以完成專案為目的,中間需要用到什麼再去研究什麼
很多人建議專案驅動,因為那樣可以理論和實踐結合。但我嘗試了一下就放棄了,因為在不瞭解整個知識體系前,你遇到問題也不知道該如何選型,中間耽擱的時間可能更多。
於是想出了新的學習方式 – 開源專案分析型:
以分析常用的開源專案為匯流排,瞭解這些專案使用什麼技術、這個技術是什麼、有什麼需要注意的地方,在遇到自己不熟悉的就學習總結一下,這樣就可以有的放矢,不至於太過漫長看不到結尾。
好了言歸正傳,這篇文章將介紹下併發程式設計中最常使用的執行緒池。
關聯文章:
讀完本文你將瞭解:
什麼是執行緒池
執行緒池的概念大家應該都很清楚,幫我們重複管理執行緒,避免建立大量的執行緒增加開銷。
除了降低開銷以外,執行緒池也可以提高響應速度,瞭解點 JVM 的同學可能知道,一個物件的建立大概需要經過以下幾步:
- 檢查對應的類是否已經被載入、解析和初始化
- 類載入後,為新生物件分配記憶體
- 將分配到的記憶體空間初始為 0
- 對物件進行關鍵資訊的設定,比如物件的雜湊碼等
- 然後執行 init 方法初始化物件
建立一個物件的開銷需要經過這麼多步,也是需要時間的嘛,那可以複用已經建立好的執行緒的執行緒池,自然也在提高響應速度上做了貢獻。
執行緒池的處理流程
建立執行緒池需要使用 ThreadPoolExecutor 類,它的建構函式引數如下:
public ThreadPoolExecutor(int corePoolSize, //核心執行緒的數量
int maximumPoolSize, //最大執行緒數量
long - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
引數介紹如註釋所示,要了解這些引數左右著什麼,就需要了解執行緒池具體的執行方法ThreadPoolExecutor.execute:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
//1.當前池中執行緒比核心數少,新建一個執行緒執行任務
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
//2.核心池已滿,但任務佇列未滿,新增到佇列中
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command)) //如果這時被關閉了,拒絕任務
reject(command);
else if (workerCountOf(recheck) == 0) //如果之前的執行緒已被銷燬完,新建一個執行緒
addWorker(null, false);
}
//3.核心池已滿,佇列已滿,試著建立一個新執行緒
else if (!addWorker(command, false))
reject(command); //如果建立新執行緒失敗了,說明執行緒池被關閉或者執行緒池完全滿了,拒絕任務
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
可以看到,執行緒池處理一個任務主要分三步處理,程式碼註釋裡已經介紹了,我再用通俗易懂的例子解釋一下:
(執行緒比作員工,執行緒池比作一個團隊,核心池比作團隊中核心團隊員工數,核心池外的比作外包員工)
- 有了新需求,先看核心員工數量超沒超出最大核心員工數,還有名額的話就新招一個核心員工來做
- 需要獲取全域性鎖
- 核心員工已經最多了,HR 不給批 HC 了,那這個需求只好攢著,放到待完成任務列表吧
- 如果列表已經堆滿了,核心員工基本沒機會搞完這麼多工了,那就找個外包吧
- 需要獲取全域性鎖
- 如果核心員工 + 外包員工的數量已經是團隊最多能承受人數了,沒辦法,這個需求接不了了
結合這張圖,這回流程你明白了嗎?
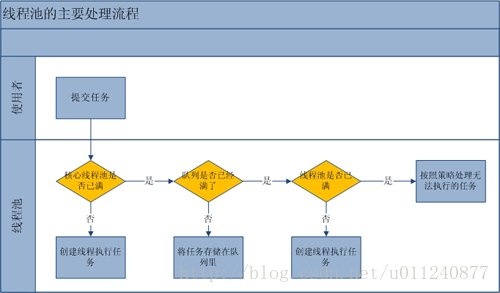
由於 1 和 3 新建執行緒時需要獲取全域性鎖,這將嚴重影響效能。因此 ThreadPoolExecutor 這樣的處理流程是為了在執行 execute() 方法時儘量少地執行 1 和 3,多執行 2。
在
ThreadPoolExecutor完成預熱後(當前執行緒數不少於核心執行緒數),幾乎所有的execute()都是在執行步驟 2。
前面提到的 ThreadPoolExecutor 建構函式的引數,分別影響以下內容:
corePoolSize:核心執行緒池數量- 線上程數少於核心數量時,有新任務進來就新建一個執行緒,即使有的執行緒沒事幹
- 等超出核心數量後,就不會新建執行緒了,空閒的執行緒就得去任務佇列裡取任務執行了
maximumPoolSize:最大執行緒數量- 包括核心執行緒池數量 + 核心以外的數量
- 如果任務佇列滿了,並且池中執行緒數小於最大執行緒數,會再建立新的執行緒執行任務
keepAliveTime:核心池以外的執行緒存活時間,即沒有任務的外包的存活時間- 如果給執行緒池設定
allowCoreThreadTimeOut(true),則核心執行緒在空閒時頭上也會響起死亡的倒計時 - 如果任務是多而容易執行的,可以調大這個引數,那樣執行緒就可以在存活的時間裡有更大可能接受新任務
- 如果給執行緒池設定
workQueue:儲存待執行任務的阻塞佇列- 不同的任務型別有不同的選擇,下一小節介紹
threadFactory:每個執行緒建立的地方- 可以給執行緒起個好聽的名字,設定個優先順序啥的
handler:飽和策略,大家都很忙,咋辦呢,有四種策略CallerRunsPolicy:只要執行緒池沒關閉,就直接用呼叫者所線上程來執行任務AbortPolicy:直接丟擲RejectedExecutionException異常DiscardPolicy:悄悄把任務放生,不做了DiscardOldestPolicy:把佇列裡待最久的那個任務扔了,然後再呼叫execute()試試看能行不- 我們也可以實現自己的
RejectedExecutionHandler介面自定義策略,比如如記錄日誌什麼的
儲存待執行任務的阻塞佇列
當執行緒池中的核心執行緒數已滿時,任務就要儲存到佇列中了。
執行緒池中使用的佇列是 BlockingQueue 介面,常用的實現有如下幾種:
- ArrayBlockingQueue:基於陣列、有界,按 FIFO(先進先出)原則對元素進行排序
- LinkedBlockingQueue:基於連結串列,按FIFO (先進先出) 排序元素
- 吞吐量通常要高於 ArrayBlockingQueue
- Executors.newFixedThreadPool() 使用了這個佇列
- SynchronousQueue:不儲存元素的阻塞佇列
- 每個插入操作必須等到另一個執行緒呼叫移除操作,否則插入操作一直處於阻塞狀態
- 吞吐量通常要高於 LinkedBlockingQueue
- Executors.newCachedThreadPool使用了這個佇列
- PriorityBlockingQueue:具有優先順序的、無限阻塞佇列
建立自己的執行緒池
瞭解上面的內容後,我們就可以建立自己的執行緒池了。
①先定義執行緒池的幾個關鍵屬性的值:
private static final int CORE_POOL_SIZE = Runtime.getRuntime().availableProcessors() * 2; // 核心執行緒數為 CPU 數*2
private static final int MAXIMUM_POOL_SIZE = 64; // 執行緒池最大執行緒數
private static final int KEEP_ALIVE_TIME = 1; // 保持存活時間 1秒- 1
- 2
- 3
- 設定核心池的數量為 CPU 數的兩倍,一般是 4、8,好點的 16 個執行緒
- 最大執行緒數設定為 64
- 空閒執行緒的存活時間設定為 1 秒
②然後根據處理的任務型別選擇不同的阻塞佇列
如果是要求高吞吐量的,可以使用 SynchronousQueue 佇列;如果對執行順序有要求,可以使用 PriorityBlockingQueue;如果最大積攢的待做任務有上限,可以使用 LinkedBlockingQueue。
private final BlockingQueue<Runnable> mWorkQueue = new LinkedBlockingQueue<>(128);- 1
③然後建立自己的 ThreadFactory
在其中為每個執行緒設定個名稱:
private final ThreadFactory DEFAULT_THREAD_FACTORY = new ThreadFactory() {
private final AtomicInteger mCount = new AtomicInteger(1);
public Thread newThread(Runnable r) {
Thread thread = new Thread(r, TAG + " #" + mCount.getAndIncrement());
thread.setPriority(Thread.NORM_PRIORITY);
return thread;
}
};- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
④然後就可以建立執行緒池了
private ThreadPoolExecutor mExecutor = new ThreadPoolExecutor(CORE_POOL_SIZE, MAXIMUM_POOL_SIZE, KEEP_ALIVE_TIME,
TimeUnit.SECONDS, mWorkQueue, DEFAULT_THREAD_FACTORY,
new ThreadPoolExecutor.DiscardOldestPolicy());- 1
- 2
- 3
這裡我們選擇的飽和策略為 DiscardOldestPolicy,你可以可以建立自己的。
⑤完整程式碼:
public class ThreadPoolManager {
private final String TAG = this.getClass().getSimpleName();
private static final int CORE_POOL_SIZE = Runtime.getRuntime().availableProcessors() * 2; // 核心執行緒數為 CPU數*2
private static final int MAXIMUM_POOL_SIZE = 64; // 執行緒佇列最大執行緒數
private static final int KEEP_ALIVE_TIME = 1; // 保持存活時間 1秒
private final BlockingQueue<Runnable> mWorkQueue = new LinkedBlockingQueue<>(128);
private final ThreadFactory DEFAULT_THREAD_FACTORY = new ThreadFactory() {
private final AtomicInteger mCount = new AtomicInteger(1);
public Thread newThread(Runnable r) {
Thread thread = new Thread(r, TAG + " #" + mCount.getAndIncrement());
thread.setPriority(Thread.NORM_PRIORITY);
return thread;
}
};
private ThreadPoolExecutor mExecutor = new ThreadPoolExecutor(CORE_POOL_SIZE, MAXIMUM_POOL_SIZE, KEEP_ALIVE_TIME,
TimeUnit.SECONDS, mWorkQueue, DEFAULT_THREAD_FACTORY,
new ThreadPoolExecutor.DiscardOldestPolicy());
private static volatile ThreadPoolManager mInstance = new ThreadPoolManager();
public static ThreadPoolManager getInstance() {
return mInstance;
}
public void addTask(Runnable runnable) {
mExecutor.execute(runnable);
}
@Deprecated
public void shutdownNow() {
mExecutor.shutdownNow();
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
這樣我們就有了自己的執行緒池。
JDK 提供的執行緒池及使用場景
JDK 為我們內建了五種常見執行緒池的實現,均可以使用 Executors 工廠類建立。
1.newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}- 1
- 2
- 3
- 4
- 5
不招外包,有固定數量核心成員的正常網際網路團隊。
可以看到,FixedThreadPool 的核心執行緒數和最大執行緒數都是指定值,也就是說當執行緒池中的執行緒數超過核心執行緒數後,任務都會被放到阻塞佇列中。
此外 keepAliveTime 為 0,也就是多餘的空餘執行緒會被立即終止(由於這裡沒有多餘執行緒,這個引數也沒什麼意義了)。
而這裡選用的阻塞佇列是 LinkedBlockingQueue,使用的是預設容量 Integer.MAX_VALUE,相當於沒有上限。
因此這個執行緒池執行任務的流程如下:
- 執行緒數少於核心執行緒數,也就是設定的執行緒數時,新建執行緒執行任務
- 執行緒數等於核心執行緒數後,將任務加入阻塞佇列
- 由於佇列容量非常大,可以一直加加加
- 執行完任務的執行緒反覆去佇列中取任務執行
FixedThreadPool 用於負載比較重的伺服器,為了資源的合理利用,需要限制當前執行緒數量。
2.newSingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}- 1
- 2
- 3
- 4
- 5
- 6
不招外包,只有一個核心成員的創業團隊。
從引數可以看出來,SingleThreadExecutor 相當於特殊的 FixedThreadPool,它的執行流程如下:
- 執行緒池中沒有執行緒時,新建一個執行緒執行任務
- 有一個執行緒以後,將任務加入阻塞佇列,不停加加加
- 唯一的這一個執行緒不停地去佇列裡取任務執行
聽起來很可憐的樣子 - -。
SingleThreadExecutor 用於序列執行任務的場景,每個任務必須按順序執行,不需要併發執行。
3.newCachedThreadPool
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}- 1
- 2
- 3
- 4
- 5
全部外包,沒活最多待 60 秒的外包團隊。
可以看到,CachedThreadPool 沒有核心執行緒,非核心執行緒數無上限,也就是全部使用外包,但是每個外包空閒的時間只有 60 秒,超過後就會被回收。
CachedThreadPool 使用的佇列是 SynchronousQueue,這個佇列的作用就是傳遞任務,並不會儲存。
因此當提交任務的速度大於處理任務的速度時,每次提交一個任務,就會建立一個執行緒。極端情況下會建立過多的執行緒,耗盡 CPU 和記憶體資源。
它的執行流程如下:
- 沒有核心執行緒,直接向
SynchronousQueue中提交任務 - 如果有空閒執行緒,就去取出任務執行;如果沒有空閒執行緒,就新建一個
- 執行完任務的執行緒有 60 秒生存時間,如果在這個時間內可以接到新任務,就可以繼續活下去,否則就拜拜
由於空閒 60 秒的執行緒會被終止,長時間保持空閒的 CachedThreadPool 不會佔用任何資源。
CachedThreadPool 用於併發執行大量短期的小任務,或者是負載較輕的伺服器。
4.newScheduledThreadPool
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE,
DEFAULT_KEEPALIVE_MILLIS, MILLISECONDS,
new DelayedWorkQueue());
}
private static final long DEFAULT_KEEPALIVE_MILLIS = 10L;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
定期維護的 2B 業務團隊,核心與外包成員都有。
ScheduledThreadPoolExecutor 繼承自 ThreadPoolExecutor, 最多執行緒數為 Integer.MAX_VALUE ,使用 DelayedWorkQueue 作為任務佇列。
ScheduledThreadPoolExecutor 新增任務和執行任務的機制與ThreadPoolExecutor 有所不同。
ScheduledThreadPoolExecutor 新增任務提供了另外兩個方法:
scheduleAtFixedRate():按某種速率週期執行scheduleWithFixedDelay():在某個延遲後執行
它倆的程式碼如下:
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,
long initialDelay,
long period,
TimeUnit unit) {
if (command == null || unit == null)
throw new NullPointerException();
if (period <= 0L)
throw new IllegalArgumentException();
ScheduledFutureTask<Void> sft =
new ScheduledFutureTask<Void>(command,
null,
triggerTime(initialDelay, unit),
unit.toNanos(period),
sequencer.getAndIncrement());
RunnableScheduledFuture<Void> t = decorateTask(command, sft);
sft.outerTask = t;
delayedExecute(t);
return t;
}
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command,
long initialDelay,
long delay,
TimeUnit unit) {
if (command == null || unit == null)
throw new NullPointerException();
if (delay <= 0L)
throw new IllegalArgumentException();
ScheduledFutureTask<Void> sft =
new ScheduledFutureTask<Void>(command,
null,
triggerTime(initialDelay, unit),
-unit.toNanos(delay),
sequencer.getAndIncrement());
RunnableScheduledFuture<Void> t = decorateTask(command, sft);
sft.outerTask = t;
delayedExecute(t);
return t;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
可以看到,這兩種方法都是建立了一個 ScheduledFutureTask 物件,呼叫 decorateTask() 方法轉成 RunnableScheduledFuture 物件,然後新增到佇列中。
看下 ScheduledFutureTask 的主要屬性:
private class ScheduledFutureTask<V>
extends FutureTask<V> implements RunnableScheduledFuture<V> {
//新增到佇列中的順序
private final long sequenceNumber;
//何時執行這個任務
private volatile long time;
//執行的間隔週期
private final long period;
//實際被新增到佇列中的 task
RunnableScheduledFuture<V> outerTask = this;
//在 delay queue 中的索引,便於取消時快速查詢
int heapIndex;
//...
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
DelayQueue 中封裝了一個優先順序佇列,這個佇列會對佇列中的 ScheduledFutureTask 進行排序,兩個任務的執行 time 不同時,time 小的先執行;否則比較新增到佇列中的順序 sequenceNumber ,先提交的先執行。
ScheduledThreadPoolExecutor 的執行流程如下:
- 呼叫上面兩個方法新增一個任務
- 執行緒池中的執行緒從 DelayQueue 中取任務
- 然後執行任務
具體執行任務的步驟也比較複雜:
- 執行緒從 DelayQueue 中獲取 time 大於等於當前時間的 ScheduledFutureTask
DelayQueue.take()
- 執行完後修改這個 task 的 time 為下次被執行的時間
- 然後再把這個 task 放回佇列中
DelayQueue.add()
ScheduledThreadPoolExecutor 用於需要多個後臺執行緒執行週期任務,同時需要限制執行緒數量的場景。
兩種提交任務的方法
ExecutorService 提供了兩種提交任務的方法:
execute():提交不需要返回值的任務submit():提交需要返回值的任務
execute
void execute(Runnable command);- 1
execute() 的引數是一個 Runnable,也沒有返回值。因此提交後無法判斷該任務是否被執行緒池執行成功。
ExecutorService executor = Executors.newCachedThreadPool();
executor.execute(new Runnable() {
@Override
public void run() {
//do something
}
});- 1
- 2
- 3
- 4
- 5
- 6
- 7
submit
<T> Future<T> submit(Callable<T> task);
<T> Future<T> submit(Runnable task, T result);
Future<?> submit(Runnable task);- 1
- 2
- 3
submit() 有三種過載,引數可以是 Callable 也可以是 Runnable。
同時它會返回一個 Funture 物件,通過它我們可以判斷任務是否執行成功。
獲得執行結果呼叫 Future.get() 方法,這個方法會阻塞當前執行緒直到任務完成。
提交一個 Callable 任務時,需要使用 FutureTask 包一層:
FutureTask futureTask = new FutureTask(new Callable<String>() { //建立 Callable 任務
@Override
public String call() throws Exception {
String result = "";
//do something
return result;
}
});
Future<?> submit = executor.submit(futureTask); //提交到執行緒池
try {
Object result = submit.get(); //獲取結果
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
關閉執行緒池
執行緒池即使不執行任務也會佔用一些資源,所以在我們要退出任務時最好關閉執行緒池。
有兩個方法關閉執行緒池:
1.`shutdown()
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess(); //獲取許可權
advanceRunState(SHUTDOWN); //修改執行狀態
interruptIdleWorkers(); //遍歷停止未開啟的執行緒
onShutdown(); // 目前空實現
} finally {
mainLock.unlock();
}
tryTerminate();
}
private void interruptIdleWorkers(boolean onlyOne) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
for (Worker w : workers) { //遍歷所有執行緒
Thread t = w.thread;
//多了一個條件w.tryLock(),表示拿到鎖後就中斷
if (!t.isInterrupted() && w.tryLock()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
} finally {
w.unlock();
}
}
if (onlyOne)
break;
}
} finally {
mainLock.unlock();
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
將執行緒池的狀態設定為 SHUTDOWN,然後中斷所有 沒有執行 的執行緒,無法再新增執行緒。
2.shutdownNow()
public List<Runnable> shutdownNow() {
List<Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
advanceRunState(STOP); //修改執行狀態
interruptWorkers(); //中斷所有
tasks = drainQueue();
} finally {
mainLock.unlock();
}
tryTerminate();
return tasks;
}
private void interruptWorkers() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
for (Worker w : workers) //中斷全部執行緒,不管是否在執行
w.interruptIfStarted();
} finally {
mainLock.unlock();
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
將執行緒池設定為 STOP,然後嘗試停止 所有執行緒,並返回等待執行任務的列表。
它們的不同點是:shutdown() 只結束未執行的任務;shutdownNow() 結束全部。
共同點是:都是通過遍歷執行緒池中的執行緒,逐個呼叫 Thread.interrup() 來中斷執行緒,所以一些無法響應中斷的任務可能永遠無法停止(比如 Runnable)。
如何合理地選擇或者配置
瞭解 JDK 提供的幾種執行緒池實現,在實際開發中如何選擇呢?
根據任務型別決定。 前面已經介紹了,這裡再小節一下:
CachedThreadPool用於併發執行大量短期的小任務,或者是負載較輕的伺服器。FixedThreadPool用於負載比較重的伺服器,為了資源的合理利用,需要限制當前執行緒數量。SingleThreadExecutor用於序列執行任務的場景,每個任務必須按順序執行,不需要併發執行。ScheduledThreadPoolExecutor用於需要多個後臺執行緒執行週期任務,同時需要限制執行緒數量的場景。
自定義執行緒池時,如果任務是 CPU 密集型(需要進行大量計算、處理),則應該配置儘量少的執行緒,比如 CPU 個數 + 1,這樣可以避免出現每個執行緒都需要使用很長時間但是有太多執行緒爭搶資源的情況; 如果任務是 IO密集型(主要時間都在 I/O,CPU 空閒時間比較多),則應該配置多一些執行緒,比如 CPU 數的兩倍,這樣可以更高地壓榨 CPU。
為了錯誤避免建立過多執行緒導致系統奔潰,建議使用有界佇列。因為它在無法新增更多工時會拒絕任務,這樣可以提前預警,避免影響整個系統。
執行時間、順序有要求的話可以選擇優先順序佇列,同時也要保證低優先順序的任務有機會被執行。
總結
這篇文章簡單介紹了 Java 中執行緒池的工作原理和一些常見執行緒池的使用,在實際開發中最好使用執行緒池來統一管理非同步任務,而不是直接 new 一個執行緒執行任務。