
ElasticSearch中分詞器以及分詞原理:聽課筆記(38講-45講)
第38講

第39講
第40講


第41講
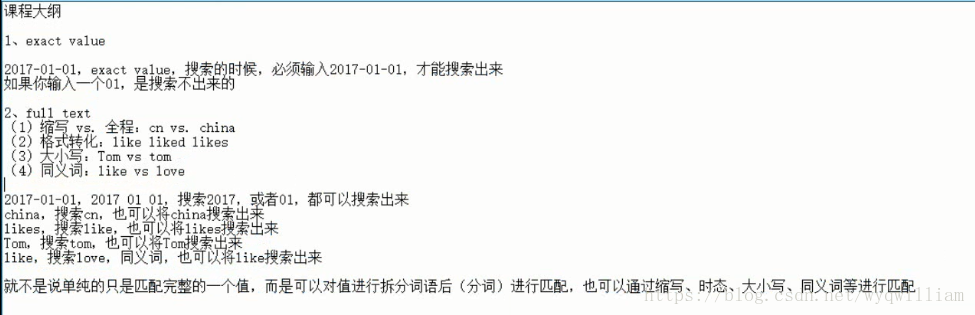
分詞器:拆分詞語,做normalization(時態轉換,單複數轉換,同義詞,大小寫的轉換)

預設情況下是standard狀態,分詞的時候會將連詞and ,介詞a the an等詞幹掉
第42講


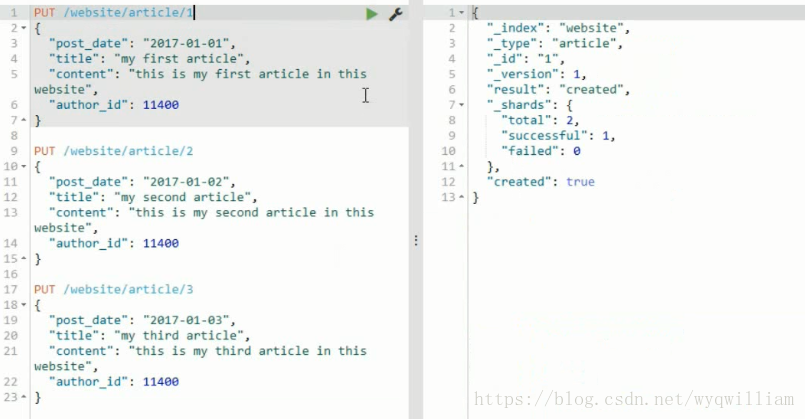
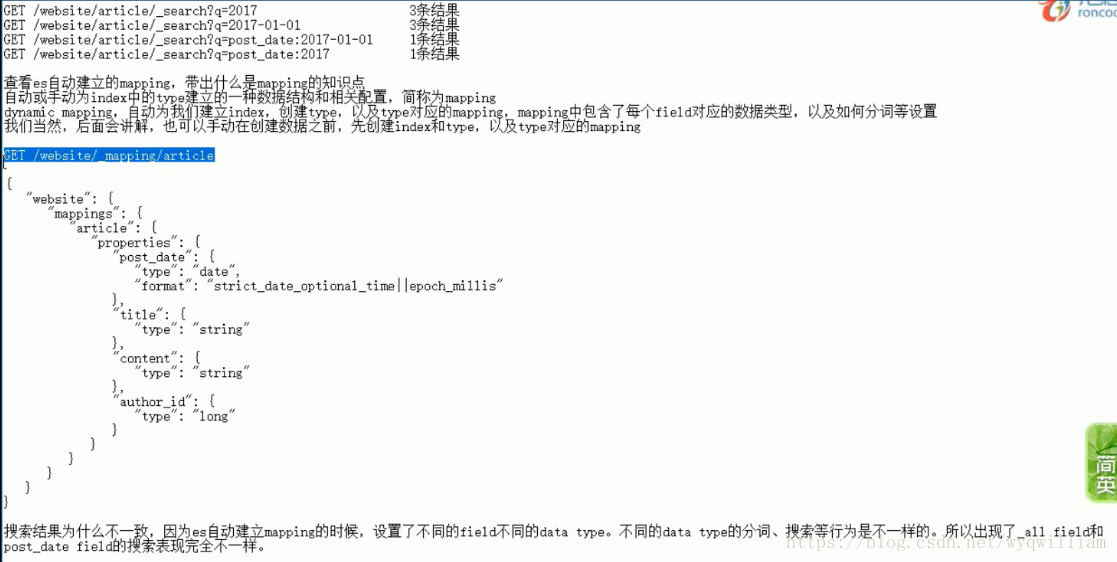
date建立倒排索引的時候,會按照精準查詢來匹配。
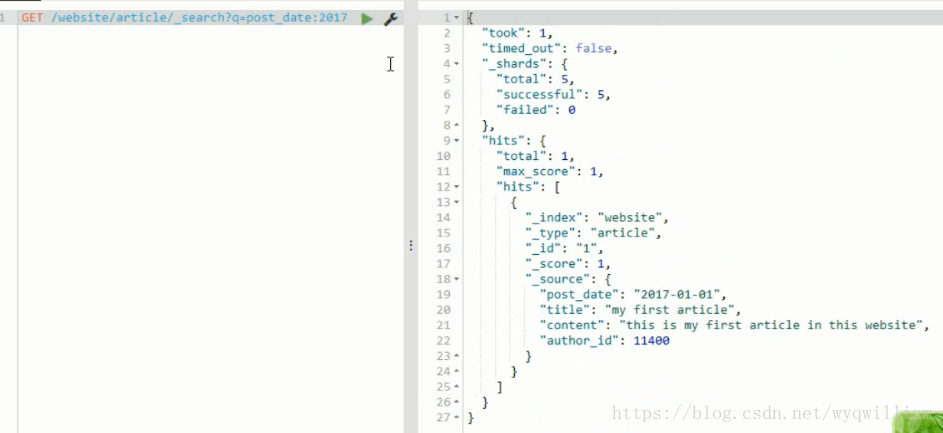
post date內部做了一部分優化
測試分詞器的方法:
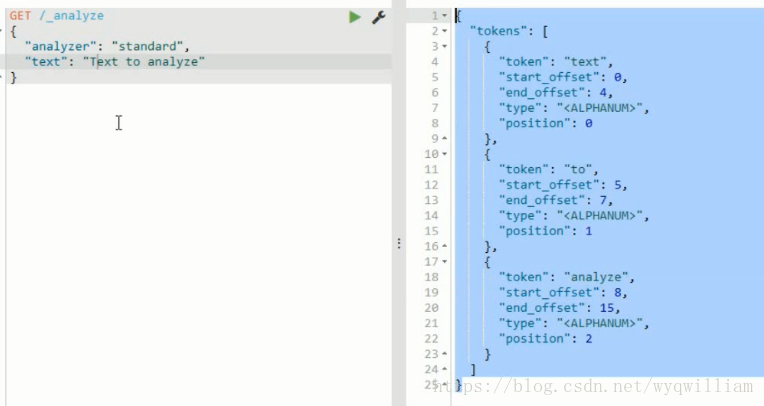
第43講

第44講

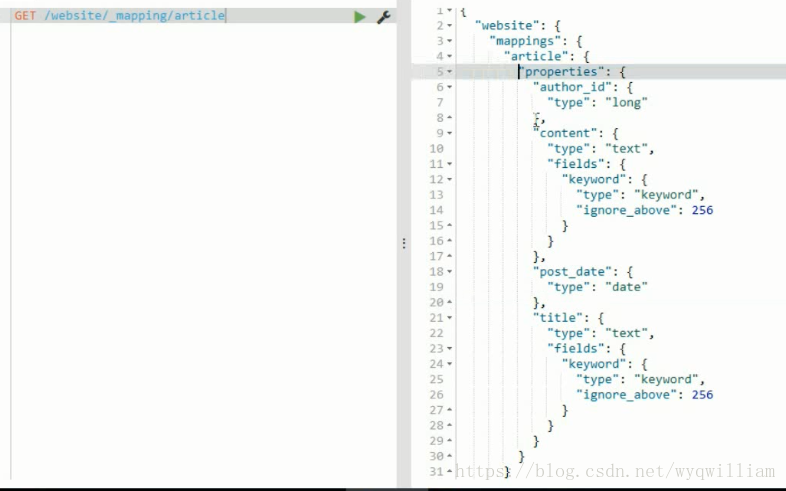
第45講

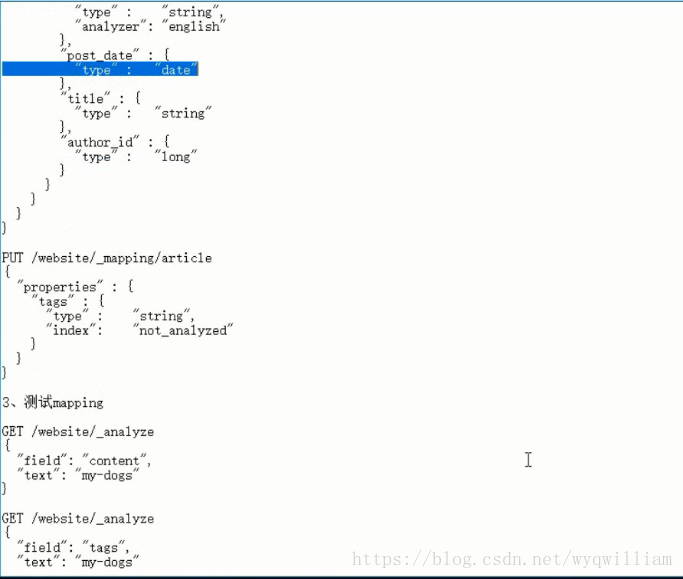
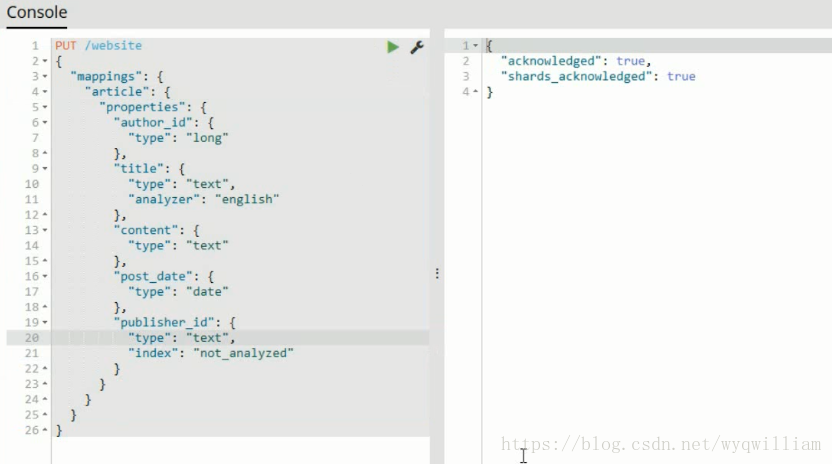
修改會報錯
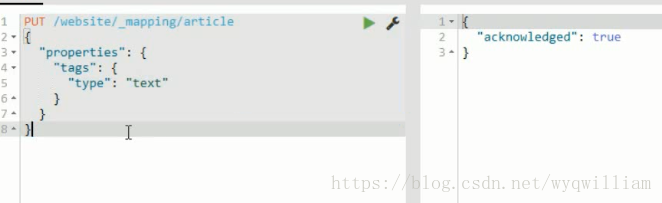
field的mapping不能修改,只能進行新增。
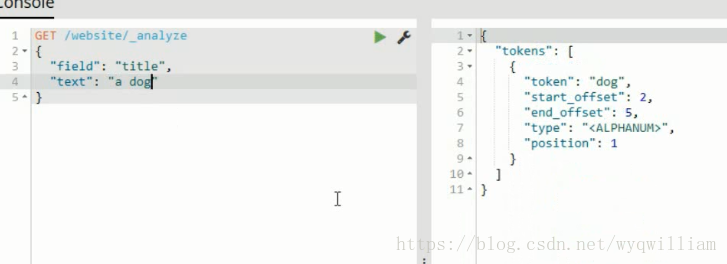
英文分詞器會把冠詞去掉
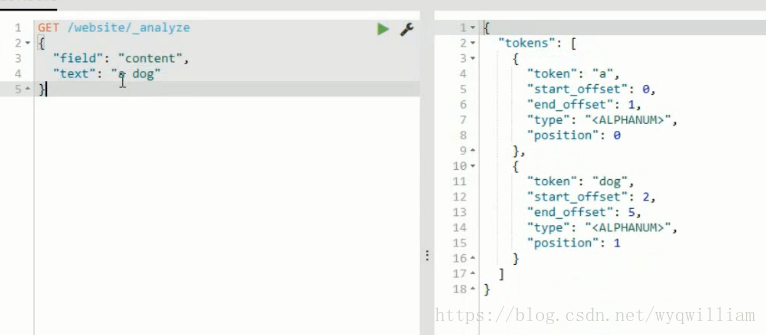
中文分詞器會把冠詞保留
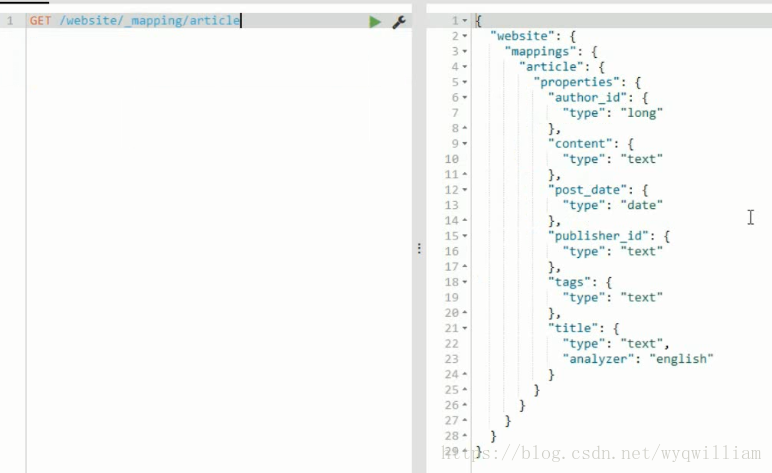
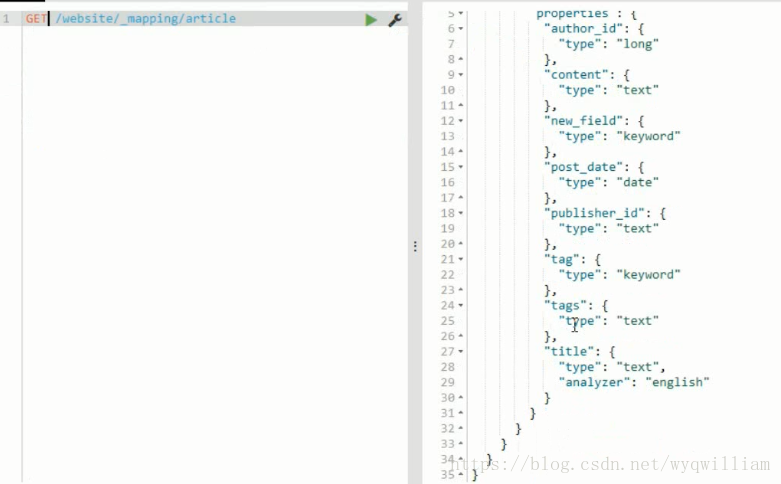
檢查對映(key word是不會進行分詞的)

--------------------- 本文來自 wyqwilliam 的CSDN 部落格 ,全文地址請點選:https://blog.csdn.net/wyqwilliam/article/details/82951553?utm_source=copy
相關推薦
ElasticSearch中分詞器以及分詞原理:聽課筆記(38講-45講)
第38講 第39講 第40講 第41講 分詞器:拆分詞語,做normalization(時態轉換,單複數轉換,同義詞,大小寫的轉換) 預設情況下是standard狀態,分詞的時候會將連詞and ,介詞a the an等詞幹掉 第42講
ElasticSearch最佳入門實踐(六十一)修改分詞器以及定製自己的分詞器
1、預設的分詞器 standard 其餘: standard tokenizer:以單詞邊界進行切分 standard token filter:什麼都不做 lowercase token filter:將所有字母轉換為小寫 stop token filer
Elasticsearch 之(12)query string的分詞,修改分詞器以及自定義分詞器
query string分詞query string必須以和index建立時相同的analyzer進行分詞query string對exact value和full text的區別對待 (第10節中詳細闡述過)date:exact value_all:full text比如我
ES:修改分詞器以及定製自己的分詞器
1、預設的分詞器 standard standard tokenizer:以單詞邊界進行切分 standard token filter:什麼都不做 lowercase token filter:將所有字母轉換為小寫 stop token filer(預設被禁用
Elasticsearch5.x安裝IK分詞器以及使用
Elasticsearch中,內建了很多分詞器(analyzers),例如standard (標準分詞器)、english (英文分詞)和chinese (中文分詞)。其中standard 就是無腦的一個一個詞(漢字)切分,所以適用範圍廣,但是精準度低;english 對英文
ElasticSearch50:索引管理_快速上機動手實戰修改分詞器以及定製自己的分詞器
1.預設的分詞器 standard standard tokenizer:以單詞的邊界進行切分 standard token filter:什麼都不做 lowercase token filter:將所有字母轉換成小寫 stop token filter(預設被禁用),移除
安裝ik分詞器以及版本和ES版本的相容性
一.檢視自己ES的版本號與之對應的IK分詞器版本 https://github.com/medcl/elasticsearch-analysis-ik/blob/master/README.md 二.下載與之對應的版本 https://github.com/medcl/elasticse
Lucene筆記20-Lucene的分詞-實現自定義同義詞分詞器-實現分詞器(良好設計方案)
一、目前存在的問題 在getSameWords()方法中,我們使用map臨時存放了兩個鍵值對用來測試,實際開發中,往往需要很多的這種鍵值對來處理,比如從某個同義詞詞典裡面獲取值之類的,所以說,我們需要一個類,根據key提供近義詞。 為了能更好的適應應用場景,我們先定義一個介面,其中定義一
Lucene筆記19-Lucene的分詞-實現自定義同義詞分詞器-實現分詞器
一、同義詞分詞器的程式碼實現 package com.wsy; import com.chenlb.mmseg4j.Dictionary; import com.chenlb.mmseg4j.MaxWordSeg; import com.chenlb.mmseg4j.analysis.MM
基於spring boot架構和word分詞器的分詞檢索,排序,分頁實現
本文不適合Java初學者,適合對spring boot有一定了解的同學。 文中可能涉及到一些實體類、dao類、工具類文中沒有這些類大家不必在意,不影響本文的核心內容,本文重在對方法的梳理。 word分詞器maven依賴<dependency>
solr 的分析器,分詞器和分詞過濾器
(一) 分詞基本概念 概覽 當對一個文件(document是一系列field的集合)進行索引時,其中的每個field(document和file都是lucene中的概念)中的資料都會經歷分析,分詞和多步的分詞過濾等操作。這一系列的動作是什麼呢?直觀的理解是,
ElasticSearch中search after處理深分頁介紹
原文地址:https://www.elastic.co/guide/en/elasticsearch/reference/5.5/search-request-search-after.html Search Afteredit Pagination o
7 Django分頁器文章分頁
src http 技術分享 alt .com bsp 9.png image png 1 2 3 4 5 7 Django分頁器文章分頁
django -----分頁器元件 分頁器元件
分頁器元件 本文目錄 1 Django的分頁器(paginator)簡介 2 應用View層 3 模版層 index.html 4 擴充套件 回到目錄
element-ui表格+分頁器資料分頁展示
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Document</title> <link rel=
在程式設計競賽中,有6個評委為參賽選手打分,分數為0-100的整數分。 選手的最後得分為:去掉一個最高分和一個最低分的4個評委平均值 * 請寫程式碼實現(不考慮小數部分)
import java.util.Scanner; /* * 需求:在程式設計競賽中,有6個評委為參賽選手打分,分數為0-100的整數分。 * 選手的最後得分為:去掉一個最高分和一個最低分的4個評委平均值 * 請寫程式碼實現(不考慮小數部分) * *
webpack中loader載入器的使用及原理(常用的loader載入器)
webpack的loaders是一塊很重要的組成部分。我們都知道webpack是用於資源打包的,裡面的所有資源都是“模組”,內部實現了對模組資源進行載入的機制。但是Webpack本身只能處理 js模組,如果要處理其他型別的檔案,就需要使用 loader 進行轉換。 Loader 可以理解
Guava中關於字串處理以及加強版集合的使用記錄(個人學習筆記)
Guava中關於字串的處理 Strings工具類的使用 // 獲取共同的字首 String commonPrefix = Strings.commonPrefix("fenglang", "fengyue"); System.out.printl
網絡編程中的常見陷阱之 0x十六進制數(C++字面值常量)
十六進制 aid word 網絡編程 情況 技術分享 fill 截斷 常見 十六進制數相等的推斷 請問例如以下程序的輸出是神馬? #include <iostream> #include <string> using namespace std
delphi中WebBrowser的parent改變時變成空白問題的解決(覆蓋CreateWnd和DestroyWnd)
classes panel replace orm cat art topic alt 解決 這段時間在做一個delphi界面打開網頁的功能,且此網頁所在窗口可完整顯示,可縮小到另一個窗口的panel上顯示 可是在改變網頁所在窗口時,WebBrowser控件變成了空白