
SQL常用函式集錦
一、字元轉換函式 1、ASCII() 返回字元表示式最左端字元的ASCII 碼值。在ASCII()函式中,純數字的字串可不用‘’括起來,但含其它字元的字串必須用‘’括起來使用,否則會出錯。 2、CHAR() 將ASCII 碼轉換為字元。如果沒有輸入0 ~ 255 之間的ASCII 碼值,CHAR() 返回NULL 。 3、LOWER()和UPPER() LOWER()將字串全部轉為小寫;UPPER()將字串全部轉為大寫。 4、STR() 把數值型資料轉換為字元型資料。 STR (<float_expression>[,length[, <decimal>]]) length 指定返回的字串的長度,decimal 指定返回的小數位數。如果沒有指定長度,預設的length 值為10, decimal 預設值為0。 當length 或者decimal 為負值時,返回NULL; 當length 小於小數點左邊(包括符號位)的位數時,返回length 個*; 先服從length ,再取decimal ; 當返回的字串位數小於length ,左邊補足空格。二、去空格函式
常用: Select CONVERT(varchar(100), GETDATE(), 8): 10:57:46 Select CONVERT(varchar(100), GETDATE(), 24): 10:57:47 Select CONVERT(varchar(100), GETDATE(), 108): 10:57:49 Select CONVERT(varchar(100), GETDATE(), 12): 060516 Select CONVERT(varchar(100), GETDATE(), 23): 2006-05-16
八、統計函式
AVG ( ) -返回的平均價值 count( ) -返回的行數 first( ) -返回第一個值 last( ) -返回最後一個值 max( ) -返回的最大價值 min( ) -返回最小的價值 total( ) -返回的總和九、數學函式 abs(numeric_expr) 求絕對值 ceiling(numeric_expr) 取大於等於指定值的最小整數 exp(float_expr) 取指數 floor(numeric_expr) 小於等於指定值得最大整數 pi() 3.1415926......... power(numeric_expr,power) 返回power次方 rand([int_expr]) 隨機數產生器 round(numeric_expr,int_expr) 安int_expr規定的精度四捨五入 sign(int_expr) 根據正數,0,負數,,返回+1,0,-1 sqrt(float_expr) 平方根十、系統函式 suser_name() 使用者登入名 user_name() 使用者在資料庫中的名字 user 使用者在資料庫中的名字 show_role() 對當前使用者起作用的規則 db_name() 資料庫名 object_name(obj_id) 資料庫物件名 col_name(obj_id,col_id) 列名 col_length(objname,colname) 列長度 valid_name(char_expr) 是否是有效識別符號 十一、以上函式的部分例項 1:replace 函式 第一個引數你的字串,第二個引數你想替換的部分,第三個引數你要替換成什麼 select replace('lihan','a','b') ----------------------------- lihbn
(所影響的行數為 1 行) ========================================================= 2:substring函式 第一個引數你的字串,第二個是開始替換位置,第三個結束替換位置 select substring('lihan',0,3); ----- li
(所影響的行數為 1 行) ========================================================= 3:charindex函式 第一個引數你要查詢的char,第二個引數你被查詢的字串 返回引數一在引數二的位置 select charindex('a','lihan') ----------- 4
(所影響的行數為 1 行)
=========================================================== 4:ASCII函式 返回字元表示式中最左側的字元的 ASCII 程式碼值。 select ASCII('lihan') ----------- 108
(所影響的行數為 1 行)
================================================================ 5:nchar函式 根據 Unicode 標準的定義,返回具有指定的整數程式碼的 Unicode 字元。 引數是介於 0 與 65535 之間的正整數。如果指定了超出此範圍的值,將返回 NULL。 select nchar(3213) ---- unicode字元
(所影響的行數為 1 行)
========================================================= 6:soundex 返回一個由四個字元組成的程式碼 (SOUNDEX),用於評估兩個字串的相似性。 SELECT SOUNDEX ('lihan'), SOUNDEX ('lihon'); ----- ----- L546 L542
(所影響的行數為 1 行) ========================================================= 7:char 引數為介於 0 和 255 之間的整數。如果該整數表示式不在此範圍內,將返回 NULL 值。 SELECT char(125) ---- }
(所影響的行數為 1 行)
========================================================== 8:str函式 第一個引數必須為數字,第二個引數表示轉化成char型佔的位置,小於引數一位置返回*,大於右對齊 SELECT str(12345,3) ---- ***
(所影響的行數為 1 行)
SELECT str(12345,12) ------------ 12345
(所影響的行數為 1 行) =========================================================== 9:difference函式 返回一個整數值,指示兩個字元表示式的 SOUNDEX 值之間的差異。 返回的整數是 SOUNDEX 值中相同字元的個數。返回的值從 0 到 4 不等:0 表示幾乎不同或完全不同,4 表示幾乎相同或完全相同。 SELECT difference('lihan','liha') ----------- 3
(所影響的行數為 1 行)
================================================================== 10:stuff函式(四個引數) 函式將字串插入另一字串。它在第一個字串中從開始位置刪除指定長度的字元;然後將第二個字串插入第一個字串的開始位置。 SELECT stuff('lihan',2,3,'lihan') -------- llihann
(所影響的行數為 1 行) ===============================================================
11:left函式 返回最左邊N個字元,由引數決定 select left('lihan',4) ----- liha
(所影響的行數為 1 行) ================================================================
12 right函式 返回最右邊N個字元,由引數決定 select right('lihan',4) ----- ihan
(所影響的行數為 1 行) ================================================================
13:replicate函式 我的認為是把引數一複製引數二次 select replicate('lihan',4) -------------------- lihanlihanlihanlihan
(所影響的行數為 1 行)
================================================================
14:len函式 返回引數長度 select len('lihan') ----------- 5
(所影響的行數為 1 行)
================================================================ 15:reverse函式 反轉字串 select reverse('lihan') ----- nahil
(所影響的行數為 1 行)
=================================================================
16:lower和upper函式 引數大小寫轉化 select lower(upper('lihan')) -------------------- lihan
(所影響的行數為 1 行)
====================================================================
17:ltrim和rtrim函式 刪除左邊空格和右面空格 select ltrim(' lihan ') -------------------------- lihan
(所影響的行數為 1 行) select rtrim(' lihan') --------- lihan
(所影響的行數為 1 行)
追加: 排名函式是SQL Server2005新加的功能。在SQL Server2005中有如下四個排名函式: 1. row_number 2. rank 3. dense_rank 4. ntile 下面分別介紹一下這四個排名函式的功能及用法。在介紹之前假設有一個t_table表,表結構與表中的資料如圖1所示:
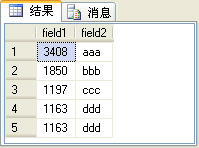 圖1
圖1
其中field1欄位的型別是int,field2欄位的型別是varchar
一、row_number
row_number函式的用途是非常廣泛,這個函式的功能是為查詢出來的每一行記錄生成一個序號。row_number函式的用法如下面的SQL語句所示:
select row_number() over(order by field1) as row_number,* from t_table
上面的SQL語句的查詢結果如圖2所示。
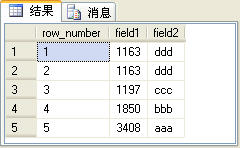 圖2
圖2
其中row_number列是由row_number函式生成的序號列。在使用row_number函式是要使用over子句選擇對某一列進行排序,然後才能生成序號。
實際上,row_number函式生成序號的基本原理是先使用over子句中的排序語句對記錄進行排序,然後按著這個順序生成序號。over子句中的order by子句與SQL語句中的order by子句沒有任何關係,這兩處的order by 可以完全不同,如下面的SQL語句所示:
select row_number() over(order by field2 desc) as row_number,* from t_table order by field1 desc
上面的SQL語句的查詢結果如圖3所示。
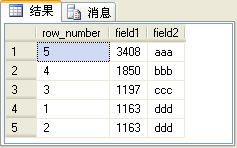 圖3
圖3
我們可以使用row_number函式來實現查詢表中指定範圍的記錄,一般將其應用到Web應用程式的分頁功能上。下面的SQL語句可以查詢t_table表中第2條和第3條記錄:
with t_rowtable as ( select row_number() over(order by field1) as row_number,* from t_table ) select * from t_rowtable where row_number>1 and row_number < 4 order by field1
上面的SQL語句的查詢結果如圖4所示。
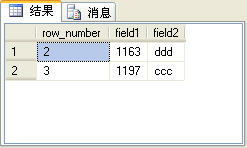 圖4
圖4
上面的SQL語句使用了CTE,關於CTE的介紹將讀者參閱《SQL Server2005雜談(1):使用公用表表達式(CTE)簡化巢狀SQL》。 另外要注意的是,如果將row_number函式用於分頁處理,over子句中的order by 與排序記錄的order by 應相同,否則生成的序號可能不是有續的。 當然,不使用row_number函式也可以實現查詢指定範圍的記錄,就是比較麻煩。一般的方法是使用顛倒Top來實現,例如,查詢t_table表中第2條和第3條記錄,可以先查出前3條記錄,然後將查詢出來的這三條記錄按倒序排序,再取前2條記錄,最後再將查出來的這2條記錄再按倒序排序,就是最終結果。SQL語句如下:
select * from (select top 2 * from( select top 3 * from t_table order by field1) a order by field1 desc) b order by field1
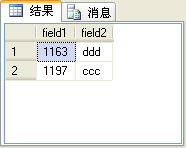 圖5
上面的SQL語句查詢出來的結果如圖5所示。
圖5
上面的SQL語句查詢出來的結果如圖5所示。
這個查詢結果除了沒有序號列row_number,其他的與圖4所示的查詢結果完全一樣。
二、rank
rank函式考慮到了over子句中排序欄位值相同的情況,為了更容易說明問題,在t_table表中再加一條記錄,如圖6所示。
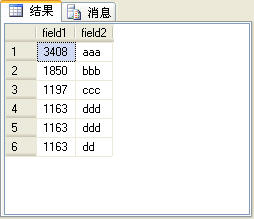 圖6
在圖6所示的記錄中後三條記錄的field1欄位值是相同的。如果使用rank函式來生成序號,這3條記錄的序號是相同的,而第4條記錄會根據當前的記錄 數生成序號,後面的記錄依此類推,也就是說,在這個例子中,第4條記錄的序號是4,而不是2。rank函式的使用方法與row_number函式完全相 同,SQL語句如下:
圖6
在圖6所示的記錄中後三條記錄的field1欄位值是相同的。如果使用rank函式來生成序號,這3條記錄的序號是相同的,而第4條記錄會根據當前的記錄 數生成序號,後面的記錄依此類推,也就是說,在這個例子中,第4條記錄的序號是4,而不是2。rank函式的使用方法與row_number函式完全相 同,SQL語句如下:
select rank() over(order by field1),* from t_table order by field1
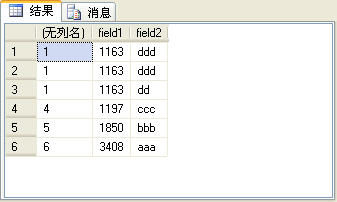 圖7
圖7
上面的SQL語句的查詢結果如圖7所示。
三、dense_rank
dense_rank函式的功能與rank函式類似,只是在生成序號時是連續的,而rank函式生成的序號有可能不連續。如上面的例子中如果使用dense_rank函式,第4條記錄的序號應該是2,而不是4。如下面的SQL語句所示:
select dense_rank() over(order by field1),* from t_table order by field1
上面的SQL語句的查詢結果如圖8所示。
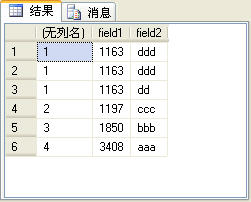 圖8
圖8
讀者可以比較圖7和圖8所示的查詢結果有什麼不同
四、ntile ntile函式可以對序號進行分組處理。這就相當於將查詢出來的記錄集放到指定長度的陣列中,每一個數組元素存放一定數量的記錄。ntile函式為每條記 錄生成的序號就是這條記錄所有的陣列元素的索引(從1開始)。也可以將每一個分配記錄的陣列元素稱為“桶”。ntile函式有一個引數,用來指定桶數。下 面的SQL語句使用ntile函式對t_table表進行了裝桶處理:
select ntile(4) over(order by field1) as bucket,* from t_table
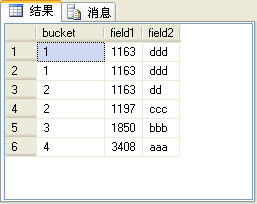 圖9
圖9
上面的SQL語句的查詢結果如圖9所示。
由於t_table表的記錄總數是6,而上面的SQL語句中的ntile函式指定了桶數為4。
也許有的讀者會問這麼一個問題,SQL Server2005怎麼來決定某一桶應該放多少記錄呢?可能t_table表中的記錄數有些少,那麼我們假設t_table表中有59條記錄,而桶數是5,那麼每一桶應放多少記錄呢?
實際上通過兩個約定就可以產生一個演算法來決定哪一個桶應放多少記錄,這兩個約定如下:
1. 編號小的桶放的記錄不能小於編號大的桶。也就是說,第1捅中的記錄數只能大於等於第2桶及以後的各桶中的記錄。
2. 所有桶中的記錄要麼都相同,要麼從某一個記錄較少的桶開始後面所有捅的記錄數都與該桶的記錄數相同。也就是說,如果有個桶,前三桶的記錄數都是10,而第4捅的記錄數是6,那麼第5桶和第6桶的記錄數也必須是6。
根據上面的兩個約定,可以得出如下的演算法:
// mod表示取餘,div表示取整 if(記錄總數 mod 桶數 == 0) { recordCount = 記錄總數 div 桶數; 將每桶的記錄數都設為recordCount } else { recordCount1 = 記錄總數 div 桶數 + 1; int n = 1; // n表示桶中記錄數為recordCount1的最大桶數 m = recordCount1 * n; while(((記錄總數 - m) mod (桶數 - n)) != 0 ) { n++; m = recordCount1 * n; } recordCount2 = (記錄總數 - m) div (桶數 - n); 將前n個桶的記錄數設為recordCount1 將n + 1個至後面所有桶的記錄數設為recordCount2 }
根據上面的演算法,如果記錄總數為59,桶數為5,則前4個桶的記錄數都是12,最後一個桶的記錄數是11。
如果記錄總數為53,桶數為5,則前3個桶的記錄數為11,後2個桶的記錄數為10。
就拿本例來說,記錄總數為6,桶數為4,則會算出recordCount1的值為2,在結束while迴圈後,會算出recordCount2的值是1,因此,前2個桶的記錄是2,後2個桶的記錄是1。