
馬士兵老師JVM調優
JVM調優
目標:調整Java虛擬機器的引數使得效能達到最優。
原則:無監控不調優。
Java記憶體結構
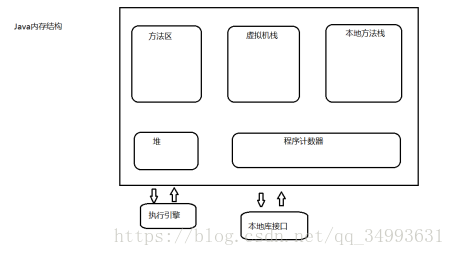
虛擬機器棧:存放區域性變數,每起一個方法都會在棧記憶體中起一個棧針。所有的區域性變數都方法在這個棧針中。所有new出來的東西都放在堆裡面。這裡面的棧針也可以認為是某一個執行緒的,每起一個執行緒就會在棧記憶體裡分配一個棧空間,在這個執行緒上沒起一個方法就會起一個棧針。棧針中存放著區域性變數。不同的棧針中的區域性變數是不會衝突的。總結起來就是一個執行緒一個棧,一個棧針。
本地方法棧:Java訪問C語言等其它語言所用到的棧,我們訪問不了。調優不了。
堆:是最大的記憶體。
方法區:
我們能夠優化的地方只有堆,堆也是JVM記憶體最大的儲存區域。
堆記憶體和方法區都是執行緒所共享的。
棧記憶體和本地方法棧,PC計數器,每個執行緒所獨有的。
堆記憶體
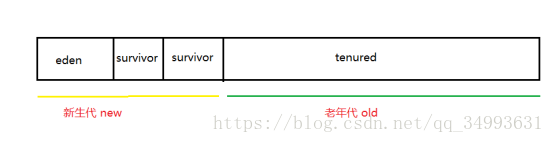
Eden伊甸園:
Survivor:倖存者
新生代比例經驗值:8 :1 :1
Tenured:老年代
總體比例:1 : 2 或者是 3 :7
流程:當我們第一次new出一個物件來的時候特別大的物件會放在老年代,其它的普通物件直接放在新生代。每次的survivor之間進行copy的時候另一個survivor會被回收,也就是時時刻刻都有一個survivor為空。由於這個演算法是基於記憶體的複製所以效率很高。
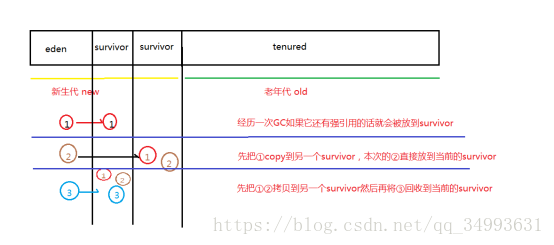
如果經歷了很多次的GC都沒有回收的話就會被放入老年代。
GC
什麼是垃圾?
引用計數演算法
沒有引用指向的物件就是垃圾?不完全是,比如說環形垃圾互相引用的物件。
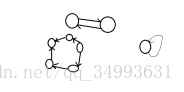
所以使用迴圈引用的方法去判斷垃圾是不行的。
正向可達演算法
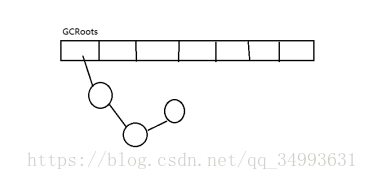
首先要得到在堆記憶體中一定不是垃圾的根物件,我們稱之為GCRoots。順著GCRoots的引用往下找順藤摸瓜摸到的就是好瓜,摸不到的就是爛瓜(垃圾)。
垃圾收集演算法
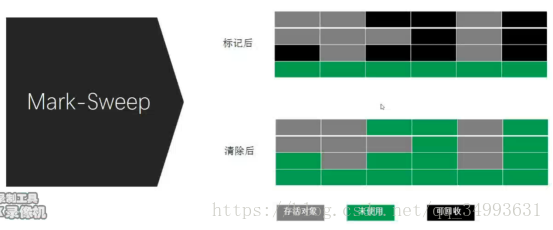
Mark-Sweep(標記清除演算法)
演算法本身只是標記而不是清除,被標記可用的記憶體區域會在新new物件的時候可以直接佔用。缺點是記憶體的不連續。當來了一個大的物件的時候記憶體中會由於碎片化而裝不下這時會進行fullGC(全回收),把離散的區域壓縮到一片連續的區域這時才可以放下,這樣的話效率就會略低。
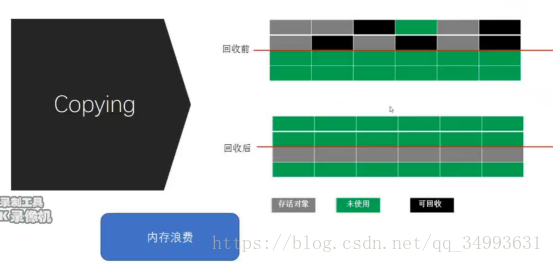
Copying(拷貝)
Copy會把記憶體區域分為兩個部分A、B而且肯定有一個區域為空(假設B區域為空)。在垃圾回收的時候首先會用正向可達演算法將所有的存活物件找到。然後會把A中的所有存活物件拷貝到B區域並且壓縮。最後回收A區中的垃圾。在洗一次GC之前,產生的新物件會被放到B區域來如此往復。它的效率非常之高。這個演算法的缺點就是浪費記憶體,永遠會浪費掉一半的記憶體。
為什麼eden的區域比survivor大。就是因為在eden中的物件大多數會被回收所以存活下來的物件會比較少這時就比較適合使用拷貝演算法(拷貝的量比較少)。
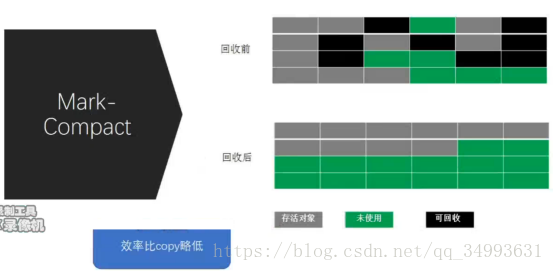
Mark-Compact(標記壓縮)
首先將倖存的物件壓縮到一端然後再進行GC這樣的話也會得到連續的可用的空間。效率比copy略低。這個演算法常常用於老年代,在新生代用的是copy的演算法。
JVM使用分代演算法
New
存活物件少,使用copying佔用的記憶體空間也不大,效率也高。
Old
垃圾少,一般使用mark-compact標記壓縮。
除此之外還有Mark-cleaning(標記清理)。
補充:
當堆記憶體的使用率超過70%的時候,GC才會啟動回收。
發生在新生代的回收 --- minor gc 初代回收
發生在老生代的回收 --- full gc 完全回收
當new出來的物件比較小的時候回方到eden區域,如果new出來的物件比較大的時候那麼就會放到tenured區去。
JVM引數
- 標準引數所有的JVM都應該支援。
-X非標準引數,每個JVM都應該實現。
-XX不穩定引數(擴充套件引數),下一個版本可能會取消。
JVM垃圾收集器
Serial Collector
XX + UseSerialGC 序列化垃圾收集器,一個單執行緒的收集器,實際中使用的並不多。
Parallel Collector
併發量大,但是在每次垃圾收集的時候回導致JVM停頓。
CMS
併發收集,分割槽處理。停頓時間短,在垃圾收集的時候,JVM還可以執行。
G1
不僅停頓時間短(這是一個平衡點)而且併發量大。
Java物件的分配
當new出一個物件來JVM會經歷這樣的幾個分配過程。
棧上分配(這個很顛覆)
當new出一個小的物件來的時候那麼會優先分配到棧(執行緒棧)上面去。JavaServer模式預設會開啟棧優化。因為棧中的物件會在方法結束之後棧針就會銷燬,因此它就根本無需垃圾回收(它本身就有垃圾回收的特質)。
無逃逸如果在方法的外面有一個引用指向了方法內部那麼此時這個方法就逃逸了。
標量替換,將一成員變數拿出來當做普通的資料型別往棧上存。
無需調整
執行緒本地分配(TLAB Thread Local Allacation Buffer)
當棧上分配不了也就是棧空間滿了會來到執行緒本地分配。每一個執行緒在執行的時候會給自己分配一塊自己專用的記憶體,叫做執行緒本地記憶體。(一個?)執行緒本地記憶體預設佔用eden記憶體的1%。如果每一個執行緒都要放入eden的同一塊區域那麼這個區域就要進行加鎖,但是每個執行緒的資料都有自己的一塊獨立的區域那麼就不需要加鎖了,不加鎖就提高了訪問效率。
無需調整
老年代
當上述兩種都分配不了那麼就先看看自己是否是一個大物件,如果是就分配到老年代。
Eden
如果自己是一個不太大的物件就分配到eden區來。
垃圾回收效率的提高
使用TLAB會提升一截,使用逃逸分析和標量替換效能又能夠提升一截。
在eclipse中的run configuration中配置:
-XX:DoEscapeAnalysis //不做逃逸分析 與棧上分配有關
-XX:-EliminateAllocations //不做標量提換 與棧上分配有關
-XX:UseTLAB// 不使用本地快取
-XX:+PrintGC // 列印GC過程
在實際的環境中我們要權衡併發的數量和併發的深度的關係。


一個檢測的例項
在實務上我們需要通過一些工具來判斷在程式中造成記憶體溢位的原因,這裡就介紹一個例項
程式碼如下:
-
package test; -
import java.util.ArrayList; -
import java.util.List; -
public class Test { -
public static void main(String[] args) { -
List<Object> list = new ArrayList<Object>(); -
for (int i = 0; i < 100000000; i++) { -
list.add(new byte[1024*1024]); -
} -
} -
}
引數如下(在Run Configuration的時候來在VMarguments中進行設定):
-
-XX:+HeapDumpOnOutOfMemoryError -
-XX:HeapDumpPath=C:\tmp\jvm.dump (生成堆記憶體相關的檔案) -
-XX:+PrintGCDetails (列印GC的詳細過程) -
-Xms10M (初始堆大小) -
-Xmx10M (最大堆大小)
最後會在c盤的tmp目錄下面生成一個jvm.dump的檔案。將jvm.dump匯入到jdk資料夾下的bin目錄中的jvisualvm.exe中。然後我們觀測到了造成記憶體溢位的是由byte[]造成的,如下圖所示。

Tomcat的優化配置
改動tomcat-->bin-->contalina.bat下面的的set JAVA_OPTS引數

使用Jmeter工具啟動多個執行緒來對tomcat進行效能測試觀察配置引數之前(也就是將set JAVA_OPTS中的配置註釋掉)與解開註釋前後每一秒併發數量的多少來判斷效能的提升。
最後,在實務上我們不推薦手動使用gc()來垃圾回收,這樣會破壞我們的設定回收策略。
最後,特地感謝馬老師一個真正做教育的老師!
--------------------- 本文來自 主流7 的CSDN 部落格 ,全文地址請點選:https://blog.csdn.net/qq_34993631/article/details/81673033?utm_source=copy