
Mysql 語句執行順序
1.Mysql語法順序,即當sql中存在下面的關鍵字時,它們要保持這樣的順序:
select[distinct] from join on where group by having union order by limit
2.Mysql執行順序,即在執行時sql按照下面的順序進行執行:
from
on
join
where
group by
having
select
distinct
union
order by
sql的執行順序對sql的效能優化很有幫助,是很重要的。在建立複合索引的時候需要考慮到這點。
舉一個例子:
在tb_student中建立一個複合索引 idx_school_grade:

然後有兩個sql 看下解釋的結果:
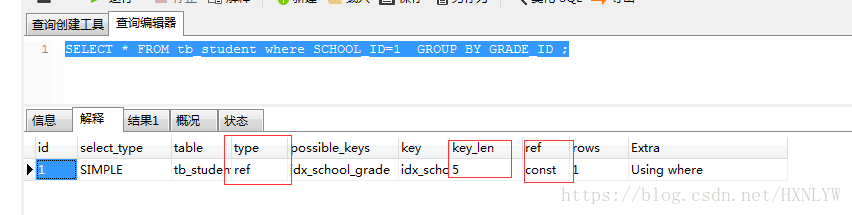

1)在當前索引下,哪一個sql索引利用率高?
第一個sql執行的順序是先執行了 where後的 school_id 然後執行了 group by 後的 grade_id,順序是和索引的順序是一致的,type等級為ref
而第二個sql是先執行了 where後的 grade_id 然後執行了 group by 後的 school_id,順序是和索引的順序是不一致的,type等級為index,從解釋結果看,第一條的sql索引利用率高於第二條的。
2)怎麼優化
如果業務中用到第二個sql,那麼就需要調整索引的順序和sql執行順序一致。
通過explain可以知道mysql是如何處理語句,分析出查詢或是表結構的效能瓶頸。通過expalin可以得到:
1. 表的讀取順序 2.表的讀取操作的操作型別 3.哪些索引可以使用 4. 哪些索引被實際使用 5.表之間的引用 6.每張表有多少行被優化器查詢
Id: MySQL QueryOptimizer 選定的執行計劃中查詢的序列號。表示查詢中執行select 子句或操作表的順序,id 值越大優先順序越高,越先被執行。id 相同,執行順序由上至下。
Select_type:一共有9中型別,只介紹常用的4種:
SIMPLE: 簡單的 select 查詢,不使用 union 及子查詢
PRIMARY: 最外層的 select 查詢
UNION: UNION 中的第二個或隨後的 select 查詢,不 依賴於外部查詢的結果集
DERIVED: 用於 from 子句裡有子查詢的情況。 MySQL 會 遞迴執行這些子查詢, 把結果放在臨時表裡。
Table:輸出行所引用的表
Type: 從有到差的順序如下:
System-->const-->eq_ref-->ref-->ref_or_null-->index_merge-->unique_subquery-->index_subquery-->range-->index-->all.
各自的含義如下:
system: 表僅有一行(=系統表)。這是 const 連線型別的一個特例。
const: const 用於用常數值比較 PRIMARY KEY 時。當 查詢的表僅有一行時,使用 System。
eq_ref: 從前面的表中,對每一個記錄的聯合都從表中讀取一個記錄,它在查詢使用了索引為主鍵或惟一鍵的全部時使用
ref: 連線不能基於關鍵字選擇單個行,可能查詢 到多個符合條件的行。 叫做 ref 是因為索引要 跟某個參考值相比較。這個參考值或者是一個常數,或者是來自一個表裡的多表查詢的 結果值。
ref_or_null: 如同 ref, 但是 MySQL 必須在初次查詢的結果裡找出 null 條目,然後進行二次查詢。
index_merge: 說明索引合併優化被使用了。
unique_subquery: 在某些 IN 查詢中使用此種類型,而不是常規的 ref:valueIN (SELECT primary_key FROM single_table WHERE some_expr)
index_subquery: 在 某 些 IN 查 詢 中 使 用 此 種 類 型 , 與unique_subquery 類似,但是查詢的是非唯一 性索引
range: 只檢索給定範圍的行,使用一個索引來選擇 行。key列顯示使用了哪個索引。當使用=、 <>、>、>=、<、<=、IS NULL、<=>、BETWEEN 或者 IN 操作符,用常量比較關鍵字列時,可 以使用 range。
index: 全表掃描,只是掃描表的時候按照索引次序 進行而不是行。主要優點就是避免了排序, 但是開銷仍然非常大。
all: 最壞的情況,從頭到尾全表掃描。
possible_keys : 指出能在該表中使用哪些索引有助於 查詢。如果為空,說明沒有可用的索引。
key:實際從 possible_key 選擇使用的索引。 如果為 NULL,則沒有使用索引。很少的情況 下,MYSQL 會選擇優化不足的索引。這種情 況下,可以在 SELECT語句中使用 USE INDEX (indexname)來強制使用一個索引或者用IGNORE INDEX(indexname)來強制 MYSQL 忽略索引
key_len: 使用的索引的長度。在不損失精確性的情況 下,長度越短越好。
ref: 顯示索引的哪一列被使用了
rows: 認為必須檢查的用來返回請求資料的行數
extra: 中出現以下 2 項意味著 根本不能使用索引,效率會受到重大影響。應儘可能對此進行優化。
Using filesort: 表示 會對結果使用一個外部索引排序,而不是從表裡按索引次序讀到相關內容。可能在記憶體或者磁碟上進行排序。無法利用索引完成的排序操作稱為“檔案排序”
Using temporary:表示對查詢結果排序時使用臨時表。常見於排序 order by 和分組查詢group by。
其中重要的幾個就是 key、type 、rows、extra,其中key為null時,說明沒有使用到索引,需要調整索引,type為all的地方,都是需要進行優化的地方.一般需要達到 ref級別,範圍查詢需要達到 range,extra有Using filesort、Using temporary 的一定需要優化,根據rows可以直觀看出優化結果。