
HBase最佳實踐-列族設計優化
轉載
https://blog.csdn.net/javastart/article/details/51820212?tdsourcetag=s_pctim_aiomsg
問題導讀:
1.BLOCKSIZE屬性在不同場景下應該如何設定?
2.COMPRESSION屬性和DATA_BLOCK_ENCODING屬性的區別是什麼?
3.Hbase需要注意哪些設計原則?
![]()
隨著大資料的越來越普及,HBase也變得越來越流行。會用HBase現在已經變的並不困難,然而,怎麼把它用的更好卻並不簡單。那怎麼定義‘用的好’呢?很簡單,在保證系統穩定性、可用性的基礎上能夠用最少的系統資源(CPU,IO等)獲得最好的效能(吞吐量,讀寫延遲)就是’用的好’。HBase是一個龐大的體系,涉及到很多方面,很多因素都會影響到系統性能和系統資源使用率,根據場景對這些配置進行優化會很大程度上提升系統的效能。筆者總結至少有如下幾個方面:HDFS相關配置優化,HBase伺服器端優化(GC優化、Compaction優化、硬體配置優化),列族設計優化,客戶端優化等,其中客戶端優化在前面已經通過超時機制、重試機制講過,後面筆者會繼續分別介紹其他三個優化重點。
本節重點介紹列族設計優化,HBase中基本屬性都是以列族為單位進行設定的,如下示例,使用者建立了一張稱為‘ NewsClickFeedback’的表,表中只有一個列族’Toutiao’,緊接著的屬性都是對此列族進行的設定。這些屬性基本都會或多或少地影響該表的讀寫效能,但有些屬性使用者只需要理解其意義就知道如何設定,而有些屬性卻需要根據場景、根據業務來設定,比如BLOCKSIZE屬性在不同場景下應該如何設定?還有COMPRESSION屬性和DATA_BLOCK_ENCODING屬性,兩者都可以提供壓縮功能,那到底應該選擇哪個,還是兩個都需要進行設定?本文就重點介紹這三個屬性的設計原則。
[Plain Text] 純文字檢視 複製程式碼
| 1 |
|
BlockSize設定
塊大小是HBase的一個重要配置選項,預設塊大小為64M。對於不同的業務資料,塊大小的合理設定對讀寫效能有很大的影響。而對塊大小的調整,主要取決於兩點:
1. 使用者平均讀取資料的大小。理論上講,如果使用者平均讀取資料的大小較小,建議將塊大小設定較小,這樣可以使得記憶體可以快取更多block,讀效能自然會更好。相反,建議將塊大小設定較大。
為了更好說明上述原理,筆者使用YCSB做了一個測試,分別在Get、Scan兩種場景下測試不同BlockSize大小(16K,64K,128K)對效能的影響。測試結果分別如下面兩圖:

隨著BlockSize的增大,系統隨機讀的吞吐量不斷降低,延遲不斷增大。64K大小比16K大小的吞吐量大約降低13%,延遲增大13%。同樣的,128K大小比64K大小的吞吐量降低約22%,延遲增大27%。因此,對於以隨機讀為主的業務,可以適當調低BlockSize的大小,以獲得更好的讀效能。
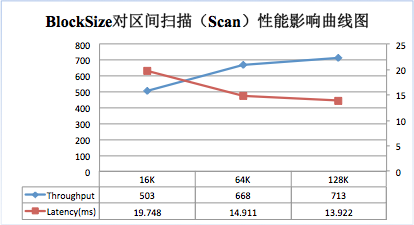
隨著BlockSize增大,scan的吞吐量逐漸增大,延遲不斷降低。64K大小BlockSize比16K大小的吞吐量增加了33%,延遲降低了24%;128K大小比64K大小吞吐量增加了7%,延遲降低了7%;因此,對於以scan為主的業務,可以適當增大BlockSize的大小,以獲得更好的讀效能。
可見,如果業務請求以Get請求為主,可以考慮將塊大小設定較小;如果以Scan請求為主,可以將塊大小調大;預設的64M塊大小是在Scan和Get之間取得的一個平衡。
2. 資料平均鍵值對規模。可以使用HFile命令檢視平均鍵值對規模,如下:
[Plain Text] 純文字檢視 複製程式碼
| 01 02 03 04 05 06 07 08 09 10 11 12 |
|
從上面輸出的資訊可以看出,該HFile的平均鍵值對規模為62B + 93B = 155B,相對較小,在這種情況下可以適當將塊大小調小(例如32KB)。這樣可以使得一個block內不會有太多kv,kv太多會增大塊內定址的延遲時間,因為HBase在讀資料時,一個block內部的查詢是順序查詢。
注意: 預設塊大小適用於多種資料使用模式,調整塊大小是比較高階的操作。配置錯誤將對效能產生負面影響。因此建議在調整之後進行測試,根據測試結果決定是否可以線上使用。
資料編碼/壓縮
Compress/DeCompress
資料壓縮是HBase提供的另一個特性,HBase在寫入資料塊到HDFS之前會首先對資料塊進行壓縮,再落盤,從而可以減少磁碟空間使用量。而在讀資料的時候首先從HDFS中加載出block塊之後進行解壓縮,然後再快取到BlockCache,最後返回給使用者。寫路徑和讀路徑分別如下:
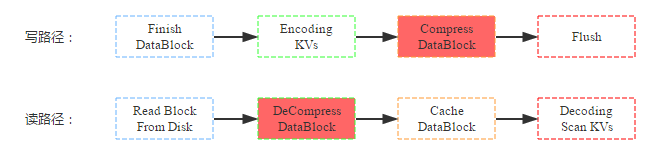
結合上圖,來看看資料壓縮對資源使用情況以及讀寫效能的影響:
(1) 資源使用情況:壓縮最直接、最重要的作用即是減少資料硬碟容量,理論上snappy壓縮率可以達到5:1,但是根據測試資料不同,壓縮率可能並沒有理論上理想;壓縮/解壓縮無疑需要大量計算,需要大量CPU資源;根據讀路徑來看,資料讀取到快取之前block塊會先被解壓,快取到記憶體中的block是解壓後的,因此和不壓縮情況相比,記憶體前後基本沒有任何影響。
(2) 讀寫效能:因為資料寫入是先將kv資料值寫到快取,最後再統一flush的硬碟,而壓縮是在flush這個階段執行的,因此會影響flush的操作,對寫效能本身並不會有太大影響;而資料讀取如果是從HDFS中讀取的話,首先需要解壓縮,因此理論上讀效能會有所下降;如果資料是從快取中讀取,因為快取中的block塊已經是解壓後的,因此效能不會有任何影響;一般情況下大多數讀都是熱點讀,快取讀佔大部分比例,壓縮並不會對讀有太大影響。
可見,壓縮特性就是使用CPU資源換取磁碟空間資源,對讀寫效能並不會有太大影響。HBase目前提供了三種常用的壓縮方式:GZip | LZO | Snappy,下面表格是官方分別從壓縮率,編解碼速率三個方面對其進行對比:

綜合來看,Snappy的壓縮率最低,但是編解碼速率最高,對CPU的消耗也最小,目前一般建議使用Snappy。
Encode/Decode
除了資料壓縮之外,HBase還提供了資料編碼功能。和壓縮一樣,資料在落盤之前首先會對KV資料進行編碼;但又和壓縮不同,資料塊在快取前並沒有執行解碼,因此即使後續命中快取的查詢也是編碼的資料塊,需要解碼後才能獲取到具體的KV資料。寫路徑和讀路徑分別如下:

同樣,來看看資料壓縮對資源使用情況以及讀寫效能的影響:
(1) 資源使用情況:和壓縮一樣,編碼最直接、最重要的作用也是減少資料硬碟容量,但是資料壓縮率一般沒有資料壓縮的壓縮率高,理論上只有5:2;編碼/解碼一般也需要大量計算,需要大量CPU資源;根據讀路徑來看,資料讀取到快取之前block塊並沒有被解碼,快取到記憶體中的block是編碼後的,因此和不編碼情況相比,相同資料block快佔用記憶體更少,即記憶體利用率更高。
(2) 讀寫效能:和資料壓縮相同,資料編碼也是在資料flush到hdfs階段執行的,因此並不會直接影響寫入過程;前面講到,資料塊是以編碼形式快取到blockcache中的,因此同樣大小的blockcache可以快取更多的資料塊,這有利於讀效能。另一方面,使用者從快取中加載出來資料塊之後並不能直接獲取KV,而需要先解碼,這卻不利於讀效能。可見,資料編碼在記憶體充足的情況下會降低讀效能,而在記憶體不足的情況下需要經過測試才能得出具體結論。
HBase目前提供了四種常用的編碼方式:Prefix | Diff | Fast_Diff | Prefix_Tree。下圖是Prefix_Tree編碼演算法作者做的一個測試結果:
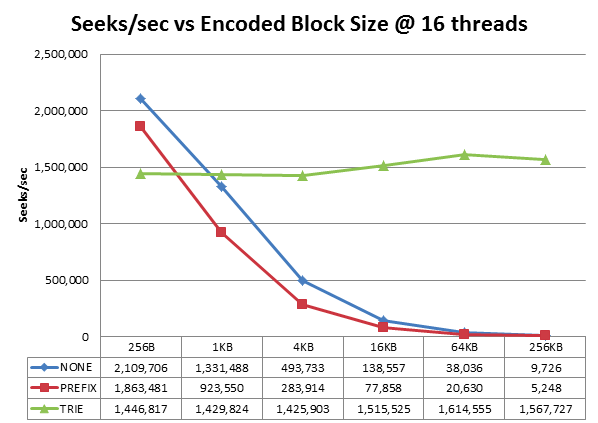
可見,prefix_tree壓縮演算法在不同的block size下效能都比較穩定,而另外兩種壓縮演算法的查詢效能會隨著blocksize直線下降。對於我們預設的64K的block大小,效能相差40+倍。另外,阿里天梧大牛之前在一篇博文裡面做過測試證明了PREFIX_TREE演算法的優越性,見《HBase-0.96中新BlockEncoding演算法-PREFIX_TREE壓縮的初步探究及測試》,因此一般建議使用PREFIX_TREE編碼壓縮。
選擇哪一個?Why?
綜上上面分析,資料壓縮和資料編碼使命基本相同:消耗CPU資源壓縮資料大小,可以認為是一種時間換空間的做法。但,同時開啟兩個功能會不會更好?如果只需要開啟一個,優先選擇哪一個?
為了更加深刻地認識資料壓縮編碼,回答上面兩個問題,本人在測試環境使用YCSB做了一個簡單的測試,分別在四種場景下(無壓縮無編碼、僅壓縮、僅編碼、既壓縮既編碼)對隨機讀以及掃描讀的操作延時、CPU使用率以及對應的壓縮率進行了測試。
測試條件:
資料:6000w條記錄,一個列族,每個列族10個列,單條記錄總共1K大小;
硬體:單RegionServer,3G BlockCache,CPU: 32 Intel(R) Xeon(R) CPU E5-2650 v2 @ 2.60GHz
測試結果:
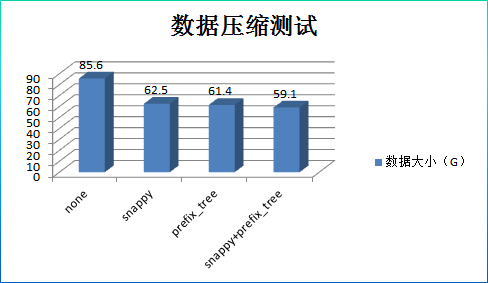
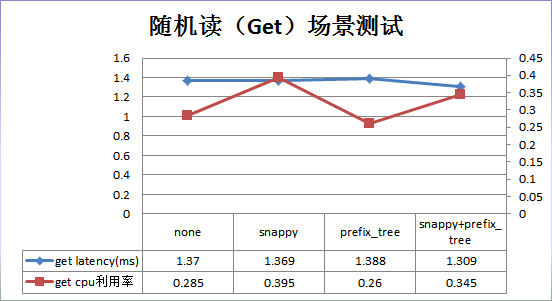

結果分析:
1. 資料壓縮率並沒有理論上0.2那麼高,只有0.7左右,這和資料結構有關係。其中壓縮、編碼、壓縮+編碼三種方式的壓縮率基本相當。
2. 隨機讀場景:和預設配置相比,snappy壓縮在效能上沒有提升,CPU開銷卻上升了38%;prefix_tree效能上沒有提升,CPU利用率也基本相當;snappy+prefix_tree效能沒有提升,CPU開銷上升了38%。
3. 區間掃描場景:和預設配置相比,snappy壓縮在效能上略有10%的提升,但是CPU開銷卻上升了23%;prefix_tree效能上略有4%左右的下降,但是CPU開銷也下降了5%;
snappy+prefix_tree在效能上基本沒有提升,CPU開銷卻上升了23%;
設計原則:
1. 在任何場景下開啟prefix_tree編碼都是安全的
2. 在任何場景下都不要同時開啟snappy壓縮和prefix_tree編碼
3. 通常情況下snappy壓縮並不能比prefix_tree編碼獲得更好的優化結果,如果需要使用snappy需要針對業務資料進行實際測試
到此為止,本文主要介紹了HBase的一個優化方向:列族設計優化。其中重點介紹了BlockSize在不同場景下對讀寫效能的影響,以及Compress與Data_Block_Encoding的設計原則。希望看官能夠根據上述對HBase的列族優化有一個更好的認識,並且能夠更多地通過測試來鞏固認知。需要說明的是,這裡的設計原則對大多數應用業務都是有效的,也有可能對於某些特殊場景並不適用,因此對於比較敏感的業務,還是以實際測試為準。後期筆者將會繼續分析HBase優化這個專題,接著介紹HBase體系中另一個非常非常重要的概念-Compaction,敬請期待~