
『TensorFlow』分散式訓練_其三_多機分散式
一、基本概念
Cluster、Job、task概念:三者可以簡單的看成是層次關係,task可以看成每臺機器上的一個程序,多個task組成job;job又有:ps、worker兩種,分別用於引數服務、計算服務,組成cluster。
同步更新
各個用於平行計算的電腦,計算完各自的batch 後,求取梯度值,把梯度值統一送到ps服務機器中,由ps服務機器求取梯度平均值,更新ps伺服器上的引數。
如下圖所示,可以看成有四臺電腦,第一臺電腦用於儲存引數、共享引數、共享計算,可以簡單的理解成記憶體、計算共享專用的區域,也就是ps job;另外三臺電腦用於平行計算的,也就是worker task。
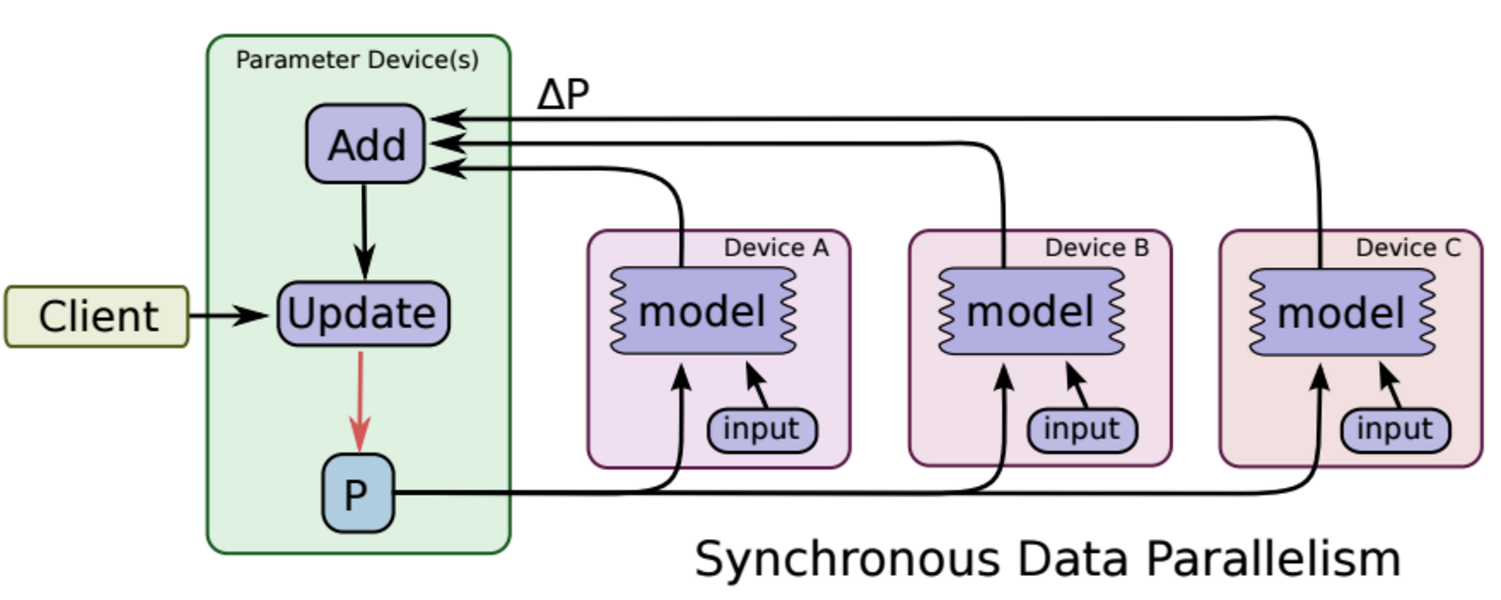
這種計算方法存在的缺陷是:每一輪的梯度更新,都要等到A、B、C三臺電腦都計算完畢後,才能更新引數,也就是迭代更新速度取決與A、B、C三臺中,最慢的那一臺電腦,所以採用同步更新的方法,建議A、B、C三臺的計算能力都不想。
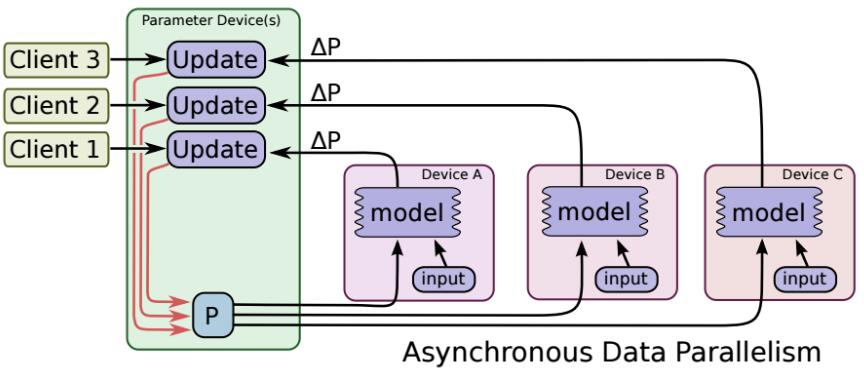
非同步更新
ps伺服器收到只要收到一臺機器的梯度值,就直接進行引數更新,無需等待其它機器。這種迭代方法比較不穩定,收斂曲線震動比較厲害,因為當A機器計算完更新了ps中的引數,可能B機器還是在用上一次迭代的舊版引數值。
二、抽象介面
1、定義分散式叢集物件
tf.train.ClusterSpec
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
=tf.train.ClusterSpec({
|
然後我們需要寫四分程式碼,這四分程式碼檔案大部分相同,但是有幾行程式碼是各不相同的(可以通過命令列引數使得字面相同各自選擇if分支不同)。
2、在各臺機器上,定義server
比如A機器上的程式碼server要定義如下:
|
1 |
|
3、在程式碼中,指定device
device不僅可以指定卡,還可以將計算圖中的不同節點指定不同機器
|
1 2 3 4 5 6 7 8 9 10 |
|
不過在深度學習訓練圖計算中,對於每個worker task來說,計算任務都是相同的,所以我們會把所有圖計算、變數定義等程式碼,都寫到下面這個語句下:
|
1 |
|
函式replica_deviec_setter會自動把變數引數定義部分定義到ps服務中(如果ps有多個任務,那麼自動分配)。
下面舉個例子,假設現在有兩臺機器A、B,A用於計算服務,B用於引數服務,那麼程式碼如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
|
把該程式碼在機器A上執行,程式會進入等候狀態,等候用於ps引數服務的機器啟動,才會執行。
因此接著我們需要在機器B上執行如下程式碼:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
|
附錄1:分散式訓練需要熟悉的函式
附錄2:分散式訓練例程
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 |
|