
【技術綜述】如何Finetune一個小網路到移動端(時空效能分析篇)
本文首發於龍鵬的知乎專欄《有三AI學院》
https://zhuanlan.zhihu.com/p/34455109
00 引言
現在很多的影象演算法都是離線計算的,而學術界刷榜單那些模型,什麼vgg16,resnet152是不能直接拿來用的,所以,對於一個深度學習演算法工程師來說,如果在這些模型的基礎上,設計出一個又小又快的滿足業務需求的模型,是必備技能,今天就來簡單討論一下這個問題。
首先,祭出一個baseline,來自Google的mobilenet,算是學術界祭出的真正有意義的移動端模型。
當然,這裡我們要稍微修改一下,畢竟原始的mobilenet是分類模型過於簡單無法展開更多,我們以更加複雜通用的一個任務開始,分割,同時修改一下初始輸入尺度,畢竟224這個尺度在移動端不一定被採用,我們以更小的一個尺度開始,以MacBookPro為計算平臺。
在原有mobilenet的基礎上新增反捲積,輸入網路尺度160*160,網路結構參考mobilenet,只是在最後加上反捲積如下

如果誰有可以視覺化caffe網路結構圖並儲存成高清圖片的方法,請告訴我一下,netscope不能儲存圖,graphviz的圖又效果很差,所以這裡沒有放完整結構圖。
不過,大家可以去參考mobilenet,然後我們在mac上跑一遍,看看時間代價如下:
其中黃色高亮是統計的每一個module的時間和。
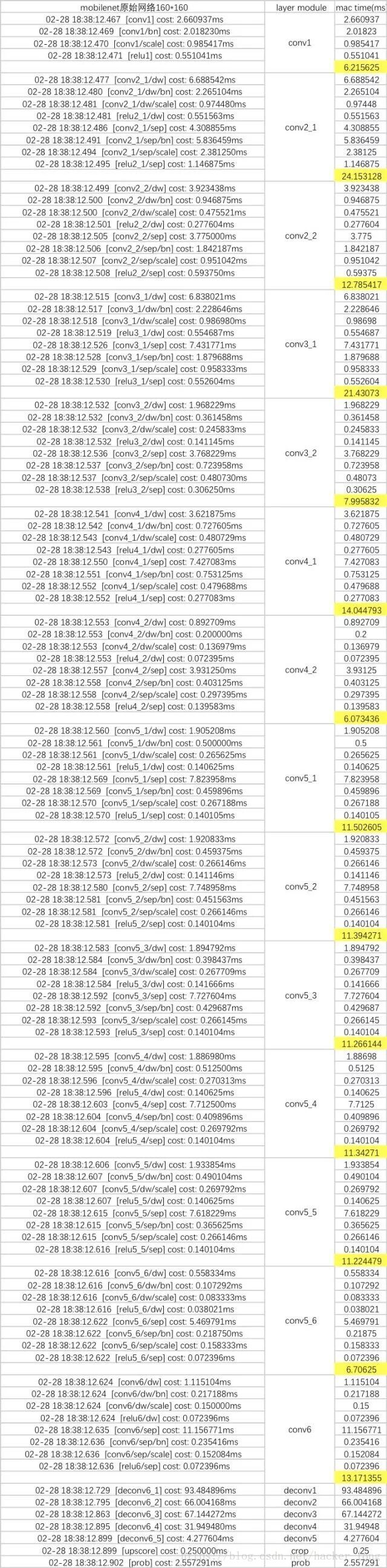
準備工作完畢,接下來開始幹活。
01 分析網路的效能瓶頸
1.1 執行時間和計算代價分析
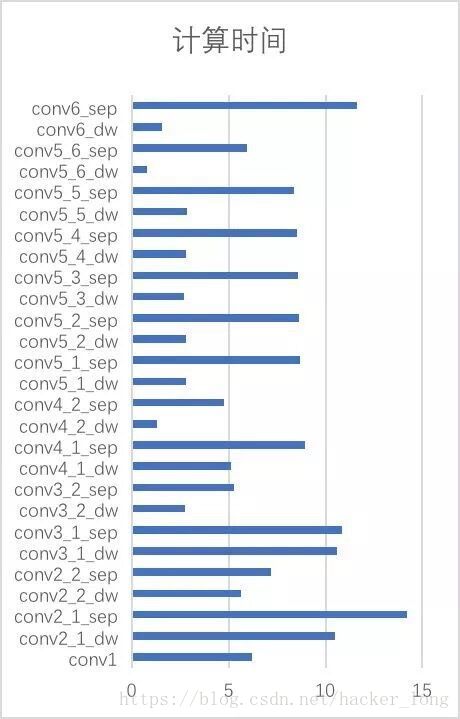

上面兩圖分別是網路的計算時間和計算量,從上面我們總結幾條規律:
(1) 耗時前5,conv2_1_sep,conv6_sep,conv3_1_sep,conv3_1_dw,conv2_1_dw。
我們看看為什麼,
conv2_1_dw計算量,32*80*80*3*3*1=1843200
conv2_1_sep計算量,32*80*80*1*1*64=13107200
conv3_1_dw計算量,128*40*40*3*3*1=1843200
conv3_1_sep計算量,128*40*40*1*1*128=26214400
conv6_sep計算量,1024*5*5*1*1*1024=26214400
上面可以看出,計算量最大的是conv6_sep,conv2_1_sep,理論上conv2_1_dw計算量與conv2_1_sep不在一個量級,但是實際上相當,這是庫實現的問題。
(2) 從conv5_1到conv5_5,由於尺度不發生變化,通道數不發生變化,所以耗時都是接近的,且dw模組/sep模組耗時比例約為1:3。
前者計算量:512*10*10*3*3
後者計算量:512*10*10*1*1*512
這一段網路結構是利用網路深度增加了非線性,所以對於複雜程度不同的問題,我們可以縮減這一段的深度。
1.2 網路引數量分析

從上面我們可以看出,引數量集中在conv6_sep,conv5_6_sep,conv5_1~5_5,所以要壓縮模型,應該從這裡地方入手。
當我們想設計更小的mobilenet網路時,有3招是基本的,一定要用。
(1) 降低輸入解析度,根據實際問題來設定。
(2) 調整網路寬度,也就是channel數量。
(3) 調整網路深度,比如從conv4_2到conv5_6這一段,都可以先去試一試。
02開始調整網路
在做這件事之前,我們先看看經典網路結構的一些東西,更具體可以參考之前的文章。

從上面的表看,主流網路第一個卷積,kernel=3,stride=2,featuremap=64,mobilenet系列已經降到了32。
第1層是提取邊緣等資訊的,當然是featuremap數量越大越好,但是其實邊緣檢測方向是有限的,很多資訊是冗餘的, 由於mobilenet優異的效能,事實證明,最底層的卷積featuremap channel=32已經夠用。
實際的任務中,大家可以看conv1佔據的時間來調整,不過大部分情況下只需要選擇好輸入尺度大小做訓練,然後套用上面的引數即可,畢竟這一層佔據的時間和引數,都不算多,32已經足夠好足夠優異,不太需要去調整的。
自從任意的卷積可以採用3*3替代且計算量更小後,網路結構中現在只剩下3*3和1*1的卷積,其他的尺寸可以先不考慮。
採用80*80輸入,砍掉conv5_6和conv6,得到的模型各層花費時間如下
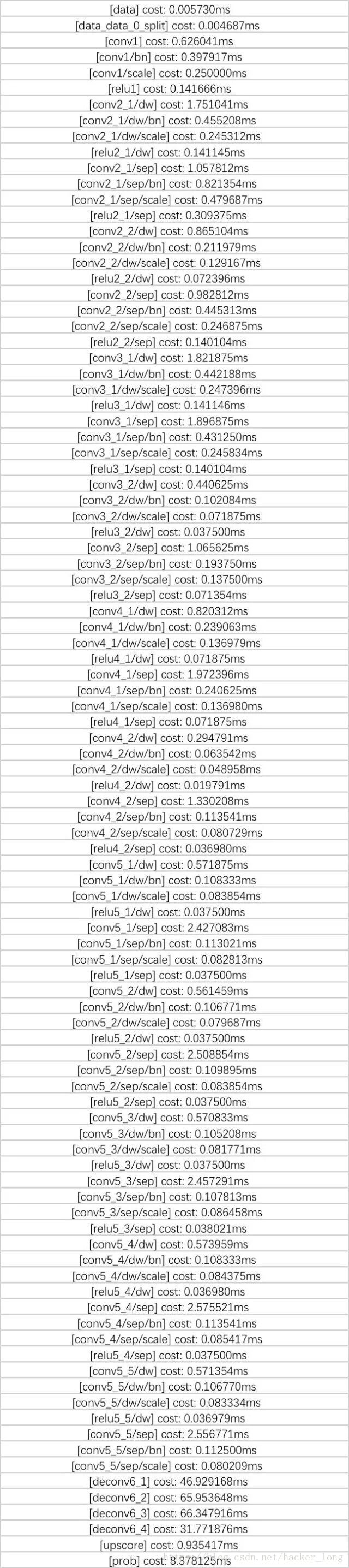
總共274ms,我們稱這個模型為mobilenet_v0。
2.1 如何決定輸入尺度
輸入尺度絕對是任務驅動的,不同的任務需要不同的輸入尺度,分割比分類需要尺度一般更大,檢測又比分割所需要的尺度更大,在這裡,我們限定一個比較簡單的分割任務,然後將輸入尺度定為80*80,就將該任務稱為A吧。
2.2 如何調整網路寬度與深度
通道數決定網路的寬度,對時間和網路大小的貢獻是一個乘因子,這是優化模型首先要做的,下面開始做。
2.2.1 反捲積
看上面的模型我們可以看出,反捲積所佔用時間遠遠大於前面提取特徵的卷積,這是因為我們沒有去優化過這個引數。那麼,到底選擇多少才合適呢?
在這裡經驗就比較有用了。卷積提取特徵的過程,是featuremap尺度變小,channel變大,反捲積正好相反,featuremap不斷變大,通道數不斷變小。這裡有4次放大2倍的卷積,考慮到每次縮放一倍,所以第一次的channel數量不能小於2^4=16,一不做二不休,我們乾脆就幹為16。
我們稱這個模型為mobilenet_v1
我們看下時間對比

再看下效能對比。

這樣,一舉將模型壓縮5倍,時間壓縮5倍,而且現在反捲積的時間代價幾乎已經可以忽略。
2.2.2 粗暴地減少網路寬度
接下來我們再返回第1部分,conv5_1到conv5_5的計算量和時間代價都是不小的,且這一部分featuremap大小不再發生變化。這意味著什麼?這意味著這一部分,純粹是為了增加網路的非線性性。
下面我們直接將conv5_1到conv5_5的featuremap從512全部幹到256,稱其為mobilenet2.1.1,再看精度和時間代價。

時間代價和網路大小又有了明顯下降,不過精度也有下降。
2.2.3 粗暴地減少網路深度
網路層數決定網路的深度,在一定的範圍內,深度越深,網路的效能就越優異。但是從第一張圖我們可看出來了,網路越深,featureamap越小,channel數越多,這個時候的計算量也是不小的。
所以,針對特定的任務去優化模型的時候,我們有必要去優化網路的深度,當然是在滿足精度的前提下,越小越好。
我們從一個比較好的起點開始,從mobilenet_v1開始吧,直接砍掉conv5_5這個block,將其稱為mobilenet_v2.1.2。
下面來看看比較。

從結果來看,精度下降尚且不算很明顯,不過時間的優化很有限,模型大小壓縮也有限。
下面在集中看一下同時粗暴地減少網路深度和寬度的結果,稱其為mobilenet_v2.1.3

以損失將近1%的代價,將模型壓縮到2.7m,40ms以內,這樣的結果,得看實際應用能不能滿足要求了。
總之,粗暴地直接減小深度和寬度,都會造成效能的下降。
2.2.4 怎麼彌補通道的損失
從上面我們可以看出,減少深度和寬度,雖然減小了模型,但是都帶來了精度的損失,很多時候這種精度損失導致模型無法上線。所以,我們需要一些其他方法來解決這個問題。
2.2.4.1 crelu通道補償
從上面可以看出,網路寬度對結果的影響非常嚴重,如果我們可以想辦法維持原來的網路寬度,且不顯著增加計算量,那就完美了。正好有這樣的方法,來源於這篇文章《Understanding and Improving Convolutional Neural Networks via Concatenated Rectified Linear Units》,它指出網路的引數有互補的現象,如果將減半後的通道補上它的反,會基本上相當於原有的模型,雖然原文針對的是網路淺層有這樣的現象,不過深層我們不妨一試,將其用於引數量和計算代價都比較大的conv5_1到conv5_4,我們直接從mobilenet_v2.1.3開始,增加conv5_1到conv5_4的網路寬度,稱之為mobilenet_v2.1.4。

2.2.4.2 skip connect,融合不同層的資訊
這是說的不能再多,用的不能再多了的技術。從FCN開始,為了恢復分割細節,從底層新增branch到高層幾乎就是必用的技巧了,它不一定能在精度指標上有多少提升,但是對於分割的細節一般是正向的。
我們直接從mobilenet_v2.1.3開始,新增3個尺度的skip connection。由於底層的channel數量較大,deconv後的channel數量較小,因此我們新增1*1卷積改變通道,剩下來就有了兩種方案,1,concat。2,eltwise。
針對這兩種方案,我們分別進行試驗。

從上表可以看出,兩個方案都不錯,時間代價和模型大小增加都很小,而精度提升較大。
現在反過頭回去看剛開始的模型v0,在精確度沒有下降的情況下,我們已經把速度優化了5倍以上,模型大小壓縮到原來的1/10,已經滿足一個通用的線上模型了。
當然,我們不可能道盡所有的技術,而接著上面的思路,也還有很多可以做的事情,本篇的重點,是讓大家學會分析效能網路的效能瓶頸,從而針對性的去優化網路。更多類似技巧和實驗,作為技術人員,自己嘗試去吧。
同時,在我的知乎專欄也會開始同步更新這個模組,歡迎來交流
注:部分圖片來自網路
—END—