
Java併發程式設計中volatile實現過程詳細解析
阿新 • • 發佈:2018-12-14
首先併發程式設計有三大特性: 可見性,有序性,原子性。volatile關鍵字實現了前面兩個特性。那麼它是如何實現這兩個特性的呢?
首先是可見性。可見性主要是讓快取,直接寫穿透到主存中。然後另外的cpu 通過底層的硬體層面的嗅探,可以發現自己cpu本地的快取已經失效。然後到主存中直接讀取。現在讓我們來看看,cpu裡面的快取具體和主存如何互動。
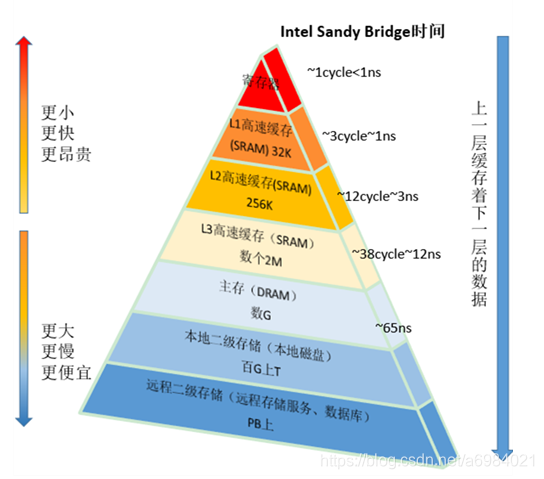
說道這裡首先需要了解,計算機內部儲存器結構。每個核中都有自己的通用暫存器,比如eax,ebx,edx,esi,esp.訪問這些暫存器裡面的內容,只要一個機器週期,就夠了,通常小於1ns…然後是L1,L2的本地core的快取。 通常在10個機器週期左右。大約10ns. L3級快取是多core共享的。
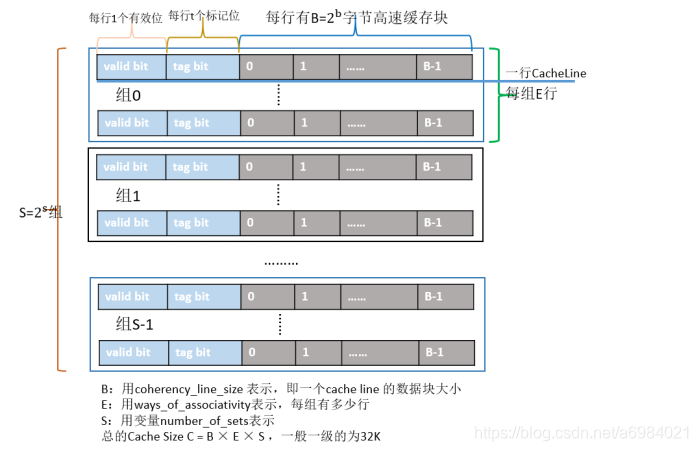
以我們常見的X86晶片為例,Cache的結構下圖所示:整個Cache被分為S個組,每個組是又由E行個最小的儲存單元——Cache Line所組成,而一個Cache Line中有B(B=64)個位元組用來儲存資料,即每個Cache Line能儲存64個位元組的資料,每個Cache Line又額外包含一個有效位(valid bit)、t個標記位(tag bit),其中valid bit用來表示該快取行是否有效;tag bit用來協助定址,唯一標識儲存在CacheLine中的塊;而Cache Line裡的64個位元組其實是對應記憶體地址中的資料拷貝。根據Cache的結構題,我們可以推算出每一級Cache的大小為B×E×S。
1級大概是32k 或者32K X2 ,2級大概是 256K或者256KX2 ,L3一般是3M左右。當多執行緒併發訪問一段程式碼的時候,讀取變數到本地的core進行計算,然後把資料寫入到快取中,假如沒有volatile關鍵字的話,快取採用的是write back 策略,直接寫到快取,看如下程式碼,雖然啟用了10個執行緒進行計數,但是打印出來的count值是0.即使sleep(100),100ms,等所有執行緒都起來了,也是得到的結果都是不定的,因為無法確定快取什麼時候,換出寫到主存中。1 public class VolatileTest {
2
3 private int count ;
4 public void increase() {
5 count++;
6 }
7 public void getCount(){
8 System.out.println(count);
9 }
10 public static void main(String[] args) throws InterruptedException{
11 VolatileTest test = new VolatileTest();
12 for(int i=0;i<10;i++){
13 new Thread(){
14 @Override
15 public void run() {
16 for(int j=0;j<1000;j++)
17 test.increase();
18 }
19 }.start();
20 }
21 Thread.sleep(100);
22 test.getCount();
23 }
24 } volatile 作用1 就是一個執行緒改變了共享變數的值,其它執行緒馬上能看見,就是可見性。比如下面的這段程式碼。
1 import java.util.concurrent.CountDownLatch;
2
3 public class VolatileTest2 {
4
5 private static volatile boolean status=false ;
6
7 private static CountDownLatch start = new CountDownLatch(1);
8
9 public void setStatusTrue(){
10 status =true;
11 }
12 public void getStatus(){
13 System.out.println(status);
14 }
15 public static void main(String[] args) throws InterruptedException{
16 VolatileTest2 test = new VolatileTest2();
17 new Thread(new Task2(start,test)).start();
18 for(int i=0;i<10;i++){
19 new Thread(new Task1(start,test)).start();
20 }
21 }
22 }
23
24 class Task1 implements Runnable{
25 private CountDownLatch latch;
26 private VolatileTest2 test ;
27 public Task1(CountDownLatch start,VolatileTest2 test){
28 this.latch = start;
29 this.test = test;
30 }
31 @Override
32 public void run() {
33 try{
34 latch.await();
35 }catch (Exception e){
36 }
37 test.getStatus();
38 }
39 }
40
41 /**
42 *
這個執行緒吧狀態設定成true,然後同步計數器馬上變成0.之後,就其它執行緒馬上就能看到status狀態為true
43 */
44 class Task2 implements Runnable{
45 private CountDownLatch latch;
46 private VolatileTest2 test ;
47 public Task2(CountDownLatch start,VolatileTest2 test){
48 this.latch = start;
49 this.test = test;
50 }
51 @Override
52 public void run() {
53 test.setStatusTrue();
54 latch.countDown();
55 System.out.println(“countDown===”);
56 }
57 }
具體的原理,這裡涉及到快取一致性原理,MESI 協議
失效(Invalid)快取段,要麼已經不在快取中,要麼它的內容已經過時。為了達到快取的目的,這種狀態的段將會被忽略。一旦快取段被標記為失效,那效果就等同於它從來沒被載入到快取中。
共享(Shared)快取段,它是和主記憶體內容保持一致的一份拷貝,在這種狀態下的快取段只能被讀取,不能被寫入。多組快取可以同時擁有針對同一記憶體地址的共享快取段,這就是名稱的由來。
獨佔(Exclusive)快取段,和S狀態一樣,也是和主記憶體內容保持一致的一份拷貝。區別在於,如果一個處理器持有了某個E狀態的快取段,那其他處理器就不能同時持有它,所以叫“獨佔”。這意味著,如果其他處理器原本也持有同一快取段,那麼它會馬上變成“失效”狀態。
已修改(Modified)快取段,屬於髒段,它們已經被所屬的處理器修改了。如果一個段處於已修改狀態,那麼它在其他處理器快取中的拷貝馬上會變成失效狀態,這個規律和E狀態一樣。此外,已修改快取段如果被丟棄或標記為失效,那麼先要把它的內容回寫到記憶體中——這和回寫模式下常規的髒段處理方式一樣。
在寫入時鎖定快取,稱為Exclusive狀態,然後同時寫入快取和主存,當讀取資料的時候,強行,從主存中讀取,並且申請快取行填充。2 有序性,這個又如何保證呢?
《深入理解Java虛擬機器》中有這句話“”“觀察加入volatile關鍵字和沒有加入volatile關鍵字時所生成的彙編程式碼發現,加入volatile關鍵字時,會多出一個lock字首指令”“”,lock字首指令實際上相當於一個記憶體屏障(也成記憶體柵欄)它確保指令重排序時不會把其後面的指令排到記憶體屏障之前的位置,也不會把前面的指令排到記憶體屏障的後面;即在執行到記憶體屏障這句指令時,在它前面的操作已經全部完成;至於什麼是記憶體屏障,不做深入瞭解。只需要知道是CPU Out-of-order execution 和 compiler reordering optimizations。用於對記憶體操作的順序限制。
Memory access instructions, such as loads and stores, typically take longer to execute than other instructions. Therefore, compilers use registers to hold frequently used values and processors use high speed caches to hold the most frequently used memory locations. Another common optimization is for compilers and processors to rearrange the order that instructions are executed so that the processor does not have to wait for memory accesses to complete. This can result in memory being accessed in a different order than specified in the source code. While this typically will not cause a problem in a single thread of execution, it can cause a problem if the location can also be accessed from another processor or device.
文章來自: