
從VirtualBox安裝到使用Hadoop單詞計數詳細圖解
Ⅰ安裝VirtualBox虛擬機器以及Ubuntu(linux)系統
1.先下載安裝包
2.先安裝VirtualBox虛擬機器

安裝完成

3.在虛擬機器上安裝Ubuntu系統




安裝完成

Ⅱ在linux上安裝JDK
1.下載並安裝JDK

2.修改配置變數
(1)通過vim進入profile
![]()
(2)修改環境變數

3.檢查是否安好

Ⅲ下載、安裝、配置Hadoop環境、並啟動Hadoop
1.下載Hadoop
![]()

2.安裝Hadoop
(1)先把安裝包放到/opt/檔案下
![]()
(2)然後進行解壓![]()
(3)解壓後的檔案
![]()


(4)進入配置資料夾
![]()


紅框內的檔案是要修改的配置檔案
(5)修改配置
i)對hadoop-env.sh進行修改
![]()

ii)對core-site.xml進行修改
![]()

iii)對hdfs-site.xml進行修改
![]()

iv)對mapred-site.xml進行修改
![]()

v)對profile進行修改
![]()

(6)檢視Hadoop是否配好
![]()

(7)對namenode進行format處理


(8)通過start-all.sh啟動hadoop

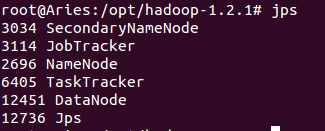
(9)通過jps命令檢視hadoop是否啟動成功
Ⅳ執行wordcount示例
要求:WordCount單詞計算
計算檔案中出現每個單詞的頻數
輸入結果按照字母順序進行排序
例如:
輸入:
hello world bye world
hello hadoop bye hadoop
bye hadoop hello hadoop
輸出:
bye 3
hello 3
hadoop 4
world 2
map、reduce的理論過程:


準備:wordcount.java檔案
![]()
檢視程式碼內容:

正式開始
(1)首先檢視hadoop是否執行

(2) vim WordCount.java編譯程式,這裡我們使用上面準備好的程式碼
![]()

(3) 對WordCount.java進行編譯,因為匯入一些hadoop的架包,所以要通過classpath對命令列進行加入
javac -classpath /opt/hadoop-1.2.1/hadoop-core-1.2.1.jar:/opt/hadoop-1.2.1/l ib/commons-cli-1.2.jar -d word_count_class/ WordCount.java
![]()
(4)進入word_count_class資料夾並觀察內容
![]()
![]()
(5)把當前目錄下所有class檔案打包成wordcount.jar:jar -cvf wordcount.jar *.class

(6)再次檢視當前檔案,可以觀測到多了一個wordcount.jar檔案
![]()
(7)返回到word_count資料夾下,進入到input資料夾,寫入file1和file2

編輯file1

編輯file2

(8)返回word_count資料夾
![]()
把file1和file2都放在input_wordcount 資料夾下:hadoop fs -put input/* input_wordcount/

建立之前如果沒有input_wordcount資料夾需要先建立一個:hadoop fs -mkdir input_wordcount
![]()
建立後再提交:hadoop fs -put input/* input_wordcount/
![]()
(9)用hadoop fs -ls命令檢視放到哪了,觀察到檔案放在/user/root/input_wordcount

(10)檢視是否是file1檔案
hadoop fs -cat input_wordcount/file1
(11)執行hadoop的命令:hadoop jar word_count_class/wordcount.jar WordCount input_wordcount output_wordcount

知識點:先map再reduce,簡單來說,只有map達到100%之後才能進行reduce
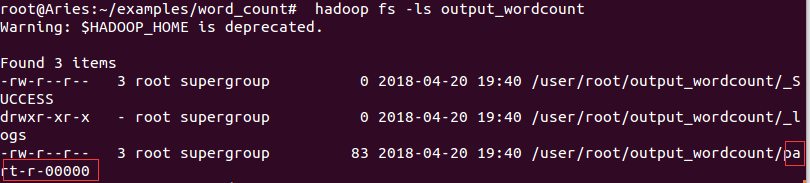
(12)檢視結果:hadoop fs -ls output_wordcount,執行結果在紅框路徑內
(13)查到執行結果:hadoop fs -cat output_wordcount/part-r-00000,其結果是按照字典的順序進行排序的

參考文獻:
學習視訊連結:https://www.imooc.com/learn/391
PS:其實這是分散式計算的作業,感謝孫老師的教導