
楊超越微博爬蟲(微博文字+圖片)粉絲資訊待續
阿新 • • 發佈:2018-12-14
# -*- coding: utf-8 -*- import urllib.request import json import time import random from urllib.request import urlopen from bs4 import BeautifulSoup import threading import requests from urllib.request import urlretrieve import re import sys import string import os import socket import urllib id= '5644764907' # 定義要爬取的微博id。楊超越微博https://m.weibo.cn/u/5644764907 proxy = [ {'http': '106.14.47.5:80'}, {'http': '61.135.217.7:80'}, {'http': '58.53.128.83:3128'}, {'http': '58.118.228.7:1080'}, {'http': '221.212.117.10:808'}, {'http': '115.159.116.98:8118'}, {'http': '121.33.220.158:808'}, {'http': '124.243.226.18:8888'}, {'http': '124.235.135.87:80'}, {'http': '14.118.135.10:808'}, {'http': '119.176.51.135:53281'}, {'http': '114.94.10.232:43376'}, {'http': '218.79.86.236:54166'}, {'http': '221.224.136.211:35101'}, {'http': '58.56.149.198:53281'}] # 設定代理IP # 定義頁面開啟函式 def use_proxy(url,proxy_addr): req = urllib.request.Request(url) req.add_header("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0") proxy = urllib.request.ProxyHandler(proxy_addr) opener = urllib.request.build_opener(proxy,urllib.request.HTTPHandler) urllib.request.install_opener(opener) data = urllib.request.urlopen(req).read().decode('utf-8','ignore') return data # 獲取微博使用者的基本資訊,如:微博暱稱、微博地址、微博頭像、關注人數、粉絲數、性別、等級等 def get_userInfo(id): url = 'https://m.weibo.cn/api/container/getIndex?type=uid&value='+id # 個人資訊介面 seed_num = random.randint(1,15)-1 proxy_addr = proxy[seed_num] data = use_proxy(url, proxy_addr) content = json.loads(data).get('data') profile_image_url = content.get('userInfo').get('profile_image_url') description = content.get('userInfo').get('description') profile_url = content.get('userInfo').get('profile_url') verified = content.get('userInfo').get('verified') guanzhu = content.get('userInfo').get('follow_count') name = content.get('userInfo').get('screen_name') fensi = content.get('userInfo').get('followers_count') gender = content.get('userInfo').get('gender') urank = content.get('userInfo').get('urank') print("微博暱稱:"+name+"\n"+"微博主頁地址:"+profile_url+"\n"+"微博頭像地址:"+profile_image_url+"\n"+"是否認證:"+str(verified)+"\n"+"微博說明:"+description+"\n"+"關注人數:"+str(guanzhu)+"\n"+"粉絲數:"+str(fensi)+"\n"+"性別:"+gender+"\n"+"微博等級:"+str(urank)+"\n") pass def save_pics(pics_info,m): print("pic_save start") for pic_info in pics_info: pic_url=pic_info['large']['url']#原圖 #pic_url=pic_info['url']#低清圖 pic_path=pics_dir + '\\%d.jpg'%m try: #下載圖片 with open(pic_path,'wb') as f: for chunk in requests.get(pic_url,stream=True).iter_content(): f.write(chunk) except: print(pic_path + '儲存失敗') else: print(pic_path + '儲存成功') m+=1 # 獲取微博主頁的containerid,爬取微博內容時需要此id def get_containerid(url,proxy_addr): data = use_proxy(url, proxy_addr) content = json.loads(data).get('data') for data in content.get('tabsInfo').get('tabs'): if(data.get('tab_type') == 'weibo'): containerid = data.get('containerid') return containerid # 獲取微博內容資訊,並儲存到文字中,內容包括:每條微博的內容、微博詳情頁面地址、點贊數、評論數、轉發數等 def get_weibo(id, file,file_content): i = 1 m = 0 while True: num = random.randint(1,15)-1 proxy_addr = proxy[num] url = 'https://m.weibo.cn/api/container/getIndex?type=uid&value='+id weibo_url = 'https://m.weibo.cn/api/container/getIndex?type=uid&value='+id+'&containerid='+get_containerid(url,proxy_addr)+'&page='+str(i) print(url) print(weibo_url) try: data = use_proxy(weibo_url, proxy_addr) content = json.loads(data).get('data') cards = content.get('cards') if(len(cards)>0): threads = [] for j in range(len(cards)): print("第"+str(i)+"頁,第"+str(j)+"條微博") card_type = cards[j].get('card_type') if(card_type == 9): mblog = cards[j].get('mblog') attitudes_count = mblog.get('attitudes_count') comments_count = mblog.get('comments_count') created_at = mblog.get('created_at') reposts_count = mblog.get('reposts_count') scheme = cards[j].get('scheme') print(i) #獲取微博內容 try: text = mblog.get('text') text = re.sub(u"\<.*?\>", "", text) except: return None with open(file_content, 'a+',encoding='utf-8') as f1: f1.write(str(text)+"\n") pass #下載圖片 try: pics_info = mblog.get('pics') except: pass else: if pics_info: print("have pics") save_pics(pics_info,m) m += 1 with open(file, 'a+', encoding='utf-8') as fh: fh.write("第"+str(i)+"頁,第"+str(j)+"條微博"+"\n") fh.write("微博地址:"+str(scheme)+"\n"+"釋出時間:"+str(created_at)+"\n"+"微博內容:"+text+"\n"+"點贊數:"+str(attitudes_count)+"\n"+"評論數:"+str(comments_count)+"\n"+"轉發數:"+str(reposts_count)+"\n") pass pass pass i += 1 time.sleep(random.randint(1,3)) pass else: break except Exception as e: print(e) pass pass pass if __name__ == "__main__": print('開始---') pics_dir = r"D:\software_study\my_jupyter_notebook\scrawl\pics_origin" file_all = "ycy_all.txt" file_content = "ycy_content.txt" #pic_index get_userInfo(id) get_weibo(id, file_all, file_content) print('完成---') pass
結果展示:
微博內容:
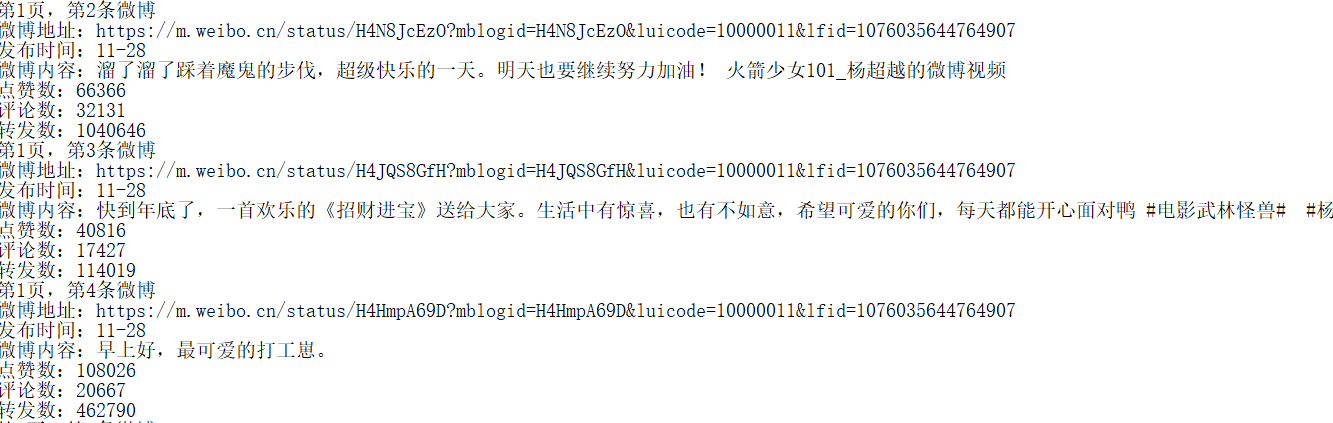
微博圖片:

GO! 衝鴨!!!超越一切