
關於面試總結6-SQL經典面試題
阿新 • • 發佈:2018-12-14
前言
用一條SQL 語句查詢xuesheng表每門課都大於80 分的學生姓名,這個是面試考sql的一個非常經典的面試題
having和not in
查詢 xuesheng表每門課都大於80 分的學生姓名
| name | kecheng | score |
|---|---|---|
| 張三 | 語文 | 81 |
| 張三 | 數學 | 73 |
| 李四 | 語文 | 86 |
| 李四 | 數學 | 90 |
| 王五 | 數學 | 89 |
| 王五 | 語文 | 88 |
| 王五 | 英語 | 96 |
解決辦法一: having
如果不考慮學生的課程少錄入情況(比如張三隻有2個課程,王五有3個課程)
SELECT name
FROM xuesheng
GROUP BY name
HAVING MIN(score)> 80如果考慮學生的課程數大於等於3的情況
SELECT name
FROM xuesheng
GROUP BY name
HAVING MIN(score)> 80
AND COUNT(kecheng)>=3解決辦法二:not in
可以用反向思維,先查詢出表裡面有小於80分的name,然後用not in去除掉
SELECT DISTINCT name
FROM xuesheng
WHERE name NOT IN
(SELECT DISTINCT name
FROM xuesheng
WHERE score <=80);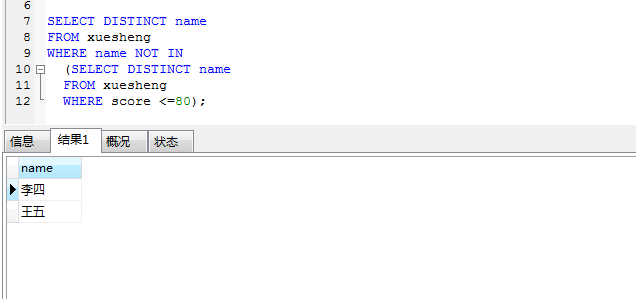
刪除
學生表xueshengbiao 如下:自動編號 學號 姓名 課程編號 課程名稱 分數
| autoid | id | name | kcid | kcname | score |
|---|---|---|---|---|---|
| 1 | 2005001 | 張三 | 0001 | 數學 | 69 |
| 2 | 2005002 | 李四 | 0001 | 數學 | 89 |
| 3 | 2005001 | 張三 | 0001 | 數學 | 69 |
刪除除了自動編號不同, 其他都相同的學生冗餘資訊
DELETE t1
FROM xueshengbiao t1, xueshengbiao t2
WHERE t1.id = t2.id
and t1.name = t2.name
and t1.kcid = t2.kcid
and t1.kcname = t2.kcname
and t1.score = t2.score
and t1.autoid < t2.autoid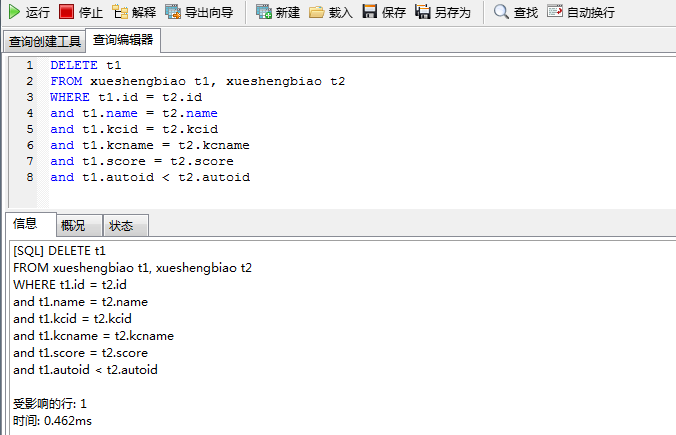
如果只是查詢出自動編號不同, 其他都相同的學生冗餘資訊,可以用group by
SELECT * from xueshengbiao t1
WHERE t1.autoid
NOT IN
(SELECT MIN(autoid) as autoid FROM xueshengbiao
GROUP BY id, name, kcid, kcname, score)
模糊查詢%
表名:student ,用sql查詢出“張”姓學生中平均成績大於75分的學生資訊;
| name | kecheng | score |
|---|---|---|
| 張青 | 語文 | 72 |
| 張華 | 英語 | 81 |
| 王華 | 數學 | 72 |
| 張青 | 物理 | 67 |
| 李立 | 化學 | 98 |
| 張青 | 化學 | 76 |
select * from student
where name in
(select name from student
where name like '張%' group by name having avg(score) > 75);SQL 萬用字元
在 SQL 中,萬用字元與 SQL LIKE 操作符一起使用。SQL 萬用字元用於搜尋表中的資料。在 SQL 中,可使用以下萬用字元:
| 萬用字元 | 描述 |
|---|---|
| % | 替代 0 個或多個字元 |
| _ | 替代一個字元 |
| [charlist] | 字元列中的任何單一字元 |
| [^charlist]或[!charlist] | 不在字元列中的任何單一字元 |
MySQL 中使用 REGEXP 或 NOT REGEXP 運算子 (或 RLIKE 和 NOT RLIKE) 來操作正則表示式
找出姓張和姓李的同學, 用rlike實現匹配多個
-- 找出姓張和姓李的
select * from xuesheng
where name in
(select name from xuesheng
where name rlike '[張李]' group by name having avg(score) > 75);也可以用 REGEXP,結合正則匹配
select * from xuesheng
where name in
(select name from xuesheng
where name REGEXP '^[張李]' group by name having avg(score) > 75);