
搜狗日誌分析
Mapreduce程式碼:https://github.com/pickLXJ/analysisSogou.git
Log日誌:https://pan.baidu.com/s/112P_hR9FlQq7htyTVjxgwg
一、日誌格式
搜狗格式查詢https://www.sogou.com/labs/resource/q.php
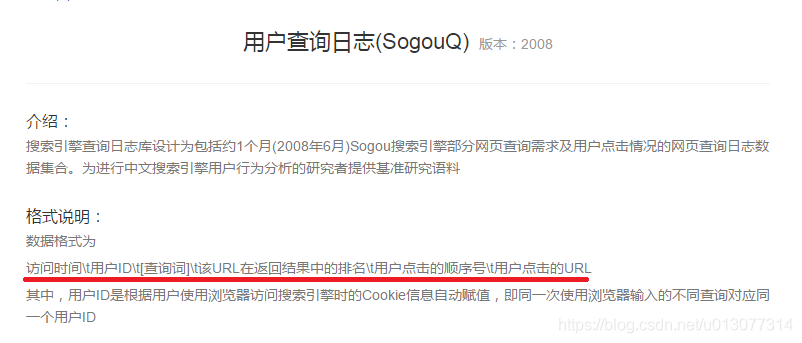
原始資料
20111230000418 e686beaf83faa9a106b1a023923edd74 黑鏡頭 9 2 http://bbs.tiexue.net/post_4161367_1.html 20111230000418 5467c699d1ae4a61b6d53bb2fe83c04a 搜尋 WWW.MMPPTV.COM 6 3 http://9bc947d.he.artseducation.com.cn/ 20111230000418 55623d0852a5161063c6d01f0856a814 百裡挑一主題歌是什麼 5 1 http://zhidao.baidu.com/question/169708995 20111230000418 8d737be3a9c125181bdd422287bee65f 鑽石價格查詢 4 2 http://tool.wozuan.com/ 20111230000419 bbe344592ade912de81595d2ec140c0d 眉山電信 9 1 http://www.aibang.com/detail/1232487017-414995109 20111230000419 df79cc0c9a4c9faa1656023c5c12265e 好看的高幹文 8 2 http://www.tianya.cn/publicforum/content/funinfo/1/1643841.shtml 20111230000419 ec0363079f36254b12a5e30bdc070125 AQVOX 8 7 http://www.erji.net/simple/index.php?t122047.html
二、資料清洗
指令碼去除空白資料,轉化部分資料
擴充套件指令碼 (年月日)
vim log-extend.sh
[[email protected] ~]#log-extend.sh /home/samba/sample/file/sogou.500w.utf8 /home/samba/sample/file/sogou_log.txt
過濾指令碼(過濾搜尋為空)
Vim log-filter.sh
#!/bin/bash #infile=/home/sogou_log.txt infile=$1 #outfile=/home/sogou_log.txt.flt outfile=$2 awk -F "\t" '{if($2 != "" && $3 != "" && $2 != " " && $3 != " ") print $0}' $infile > $outfile
[[email protected] ~]# log-filter.sh /home/samba/sample/file/sogou_log.txt /home/samba/sample/file/sogou_log.txt.flt
基於HIve構建日誌資料的資料倉庫
- 建立資料庫
hive> create database sogou;
- 使用資料庫
Hive> use sogou;
- 建立擴充套件 4 個欄位(年、月、日、小時)資料的外部表:
hive> CREATE EXTERNAL TABLE sogou_data( ts string, uid string, keyword string, rank int, sorder int, url string, year int, month int, day int, hour int) > ROW FORMAT DELIMITED > FIELDS TERMINATED BY '\t' > STORED AS TEXTFILE; OK Time taken: 0.412 seconds
- Hive表載入本地資料
load data local inpath '/home/samba/sample/file/sogou_log.txt.flt' into table sogou_data;
- 建立帶分割槽的表:
hive> CREATE EXTERNAL TABLE sogou_partitioned_data(
ts string,
uid string,
keyword string,
rank int,
sorder int,
url string)
> PARTITIONED BY(year int,month int,day int,hour int)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY '\t'
> STORED AS TEXTFILE;- 設定動態分割槽
hive> set hive.exec.dynamic.partition.mode=nonstrict;
hive> INSERT OVERWRITE TABLE sogou_partitioned_data partition(year,month,day,hour) SELECT * FROM sogou_data;
查詢測試
- 查詢前十個資料:
> select * from sogou_data limit 10;
OK
20111230000005 57375476989eea12893c0c3811607bcf 奇藝高清 1 1 http://www.qiyi.com/ 2011 11 23 0
20111230000005 66c5bb7774e31d0a22278249b26bc83a 凡人修仙傳 3 1 http://www.booksky.org/BookDetail.aspx?BookID=1050804&Level=1 2011 11 23 0
20111230000007 b97920521c78de70ac38e3713f524b50 本本聯盟 1 1 http://www.bblianmeng.com/ 2011 11 23 0
20111230000008 6961d0c97fe93701fc9c0d861d096cd9 華南師範大學圖書館 1 1 http://lib.scnu.edu.cn/ 2011 11 23 0
20111230000008 f2f5a21c764aebde1e8afcc2871e086f 線上代理 2 1 http://proxyie.cn/ 2011 11 23 0
20111230000009 96994a0480e7e1edcaef67b20d8816b7 偉大導演 1 1 http://movie.douban.com/review/1128960/ 2011 11 23 0
20111230000009 698956eb07815439fe5f46e9a4503997 youku 1 1 http://www.youku.com/ 2011 11 23 0
20111230000009 599cd26984f72ee68b2b6ebefccf6aed 安徽合肥365房產網 1 1 http://hf.house365.com/ 2011 11 23 0
20111230000010 f577230df7b6c532837cd16ab731f874 哈薩克網址大全 1 1 http://www.kz321.com/ 2011 11 23 0
20111230000010 285f88780dd0659f5fc8acc7cc4949f2 IQ數碼 1 1 http://www.iqshuma.com/ 2011 11 23 0
Time taken: 2.522 seconds, Fetched: 10 row(s)
- 查詢使用者搜尋的內容
> select * from sogou_data limit 10;
OK
20111230000005 57375476989eea12893c0c3811607bcf 奇藝高清 1 1 http://www.qiyi.com/ 2011 11 23 0
20111230000005 66c5bb7774e31d0a22278249b26bc83a 凡人修仙傳 3 1 http://www.booksky.org/BookDetail.aspx?BookID=1050804&Level=1 2011 11 23 0
20111230000007 b97920521c78de70ac38e3713f524b50 本本聯盟 1 1 http://www.bblianmeng.com/ 2011 11 23 0
20111230000008 6961d0c97fe93701fc9c0d861d096cd9 華南師範大學圖書館 1 1 http://lib.scnu.edu.cn/ 2011 11 23 0
20111230000008 f2f5a21c764aebde1e8afcc2871e086f 線上代理 2 1 http://proxyie.cn/ 2011 11 23 0
20111230000009 96994a0480e7e1edcaef67b20d8816b7 偉大導演 1 1 http://movie.douban.com/review/1128960/ 2011 11 23 0
20111230000009 698956eb07815439fe5f46e9a4503997 youku 1 1 http://www.youku.com/ 2011 11 23 0
20111230000009 599cd26984f72ee68b2b6ebefccf6aed 安徽合肥365房產網 1 1 http://hf.house365.com/ 2011 11 23 0
20111230000010 f577230df7b6c532837cd16ab731f874 哈薩克網址大全 1 1 http://www.kz321.com/ 2011 11 23 0
20111230000010 285f88780dd0659f5fc8acc7cc4949f2 IQ數碼 1 1 http://www.iqshuma.com/ 2011 11 23 0
Time taken: 2.522 seconds, Fetched: 10 row(s)
hive> select * from sogou_data where uid='6961d0c97fe93701fc9c0d861d096cd9';
OK
20111230000008 6961d0c97fe93701fc9c0d861d096cd9 華南師範大學圖書館 1 1 http://lib.scnu.edu.cn/ 2011 11 23 0
20111230065007 6961d0c97fe93701fc9c0d861d096cd9 華南師範大學圖書館 1 1 http://lib.scnu.edu.cn/ 2011 11 23 0
Time taken: 0.653 seconds, Fetched: 2 row(s)
hive>
- 查詢總條數
hive> select count(*) from sogou_partitioned_data;
Query ID = root_20181214010000_020e4437-b637-4861-bac3-21be3a0754b5
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1544683093139_0001, Tracking URL = http://bigdata000:8088/proxy/application_1544683093139_0001/
Kill Command = /app/hadoop-2.6.0-cdh5.15.1/bin/hadoop job -kill job_1544683093139_0001
Hadoop job information for Stage-1: number of mappers: 2; number of reducers: 1
Ended Job = job_1544683093139_0001
MapReduce Jobs Launched:
Stage-Stage-1: Map: 2 Reduce: 1 Cumulative CPU: 70.68 sec HDFS Read: 573691364 HDFS Write: 8 SUCCESS
Total MapReduce CPU Time Spent: 1 minutes 10 seconds 680 msec
OK
5000000
Time taken: 236.402 seconds, Fetched: 1 row(s)
hive> hive> select count(*) from sogou_partitioned_data;
- 非空查詢條數
> select count(*) from sogou_partitioned_data where keyword is not null and keyword!='';
Query ID = root_20181214010606_d8a11bd2-3cbc-482b-ba0d-27bf65d1589c
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1544683093139_0002, Tracking URL = http://bigdata000:8088/proxy/application_1544683093139_0002/
Kill Command = /app/hadoop-2.6.0-cdh5.15.1/bin/hadoop job -kill job_1544683093139_0002
Hadoop job information for Stage-1: number of mappers: 2; number of reducers: 1
MapReduce Total cumulative CPU time: 1 minutes 12 seconds 720 msec
Ended Job = job_1544683093139_0002
MapReduce Jobs Launched:
Stage-Stage-1: Map: 2 Reduce: 1 Cumulative CPU: 72.72 sec HDFS Read: 573693021 HDFS Write: 8 SUCCESS
Total MapReduce CPU Time Spent: 1 minutes 12 seconds 720 msec
OK
5000000
Time taken: 90.678 seconds, Fetched: 1 row(s)hive> select count(*) from sogou_partitioned_data where keyword is not null and keyword!='';
- 無重複總條數
hive> select count(*) from(select count(*) as no_repeat_count from sogou_partitioned_data group by ts,uid,keyword,url having no_repeat_count=1) a;
MapReduce Jobs Launched:
Stage-Stage-1: Map: 2 Reduce: 3 Cumulative CPU: 383.06 sec HDFS Read: 573702274 HDFS Write: 351 SUCCESS
Stage-Stage-2: Map: 1 Reduce: 1 Cumulative CPU: 12.22 sec HDFS Read: 5186 HDFS Write: 8 SUCCESS
Total MapReduce CPU Time Spent: 6 minutes 35 seconds 280 msec
OK
4999272
Time taken: 448.265 seconds, Fetched: 1 row(s)
hive> hive> select count(*) from(select count(*) as no_repeat_count from sogou_partitioned_data group by ts,uid,keyword,url having no_repeat_count=1) a;
- 獨立UID總數
hive> select count(distinct(uid)) from sogou_partitioned_data;
Ended Job = job_1544683093139_0006
MapReduce Jobs Launched:
Stage-Stage-1: Map: 2 Reduce: 1 Cumulative CPU: 88.13 sec HDFS Read: 573691789 HDFS Write: 8 SUCCESS
Total MapReduce CPU Time Spent: 1 minutes 28 seconds 130 msec
OK
1352664
Time taken: 91.419 seconds, Fetched: 1 row(s)hive> select count(distinct(uid)) from sogou_partitioned_data;
實現資料分析需求二:關鍵字分析
(1)查詢頻度排名(頻度最高的前50詞)
> select keyword,count(*)query_count from sogou_partitioned_data group by keyword
Total MapReduce CPU Time Spent: 3 minutes 10 seconds 30 msec
OK
百度 38441
baidu 18312
人體藝術 14475
4399小遊戲 11438
qq空間 10317
優酷 10158
新亮劍 9654
館陶縣縣長閆寧的父親 9127
公安賣萌 8192
百度一下 你就知道 7505
百度一下 7104
4399 7041
魏特琳 6665
qq網名 6149
7k7k小遊戲 5985
黑狐 5610
兒子與母親不正當關係 5496
新浪微博 5369
李宇春體 5310
新疆暴徒被擊斃圖片 4997
hao123 4834
123 4829
4399洛克王國 4112
qq頭像 4085
nba 4027
龍門飛甲 3917
qq個性簽名 3880
張去死 3848
cf官網 3729
凰圖騰 3632
快播 3423
金陵十三釵 3349
吞噬星空 3330
dnf官網 3303
武動乾坤 3232
新亮劍全集 3210
電影 3155
優酷網 3115
兩次才處決美女罪犯 3106
電影天堂 3028
土豆網 2969
qq分組 2940
全國各省最低工資標準 2872
清代姚明 2784
youku 2783
爭產案 2755
dnf 2686
12306 2682
身份證號碼大全 2680
火影忍者 2604
Time taken: 240.291 seconds, Fetched: 50 row(s)hive> select keyword,count(*)query_count from sogou_partitioned_data group by keyword order by query_count desc limit 50;
實現資料分析需求三:UID分析
- 查詢次數大於2次的使用者總數
hive>
>
> select count(*) from( select count(*) as query_count from sogou_partitioned_data group by uid having query_count > 2) a;
Write: 7 SUCCESS
Total MapReduce CPU Time Spent: 3 minutes 19 seconds 420 msec
OK
546353
Time taken: 249.635 seconds, Fetched: 1 row(s)hive> select count(*) from( select count(*) as query_count from sogou_partitioned_data group by uid having query_count > 2) a;
- 查詢次數大於2次的使用者佔比
A:
hive> select count(*) from(select count(*) as query_count from sogou_partitioned_data group by uid having query_count > 2) a;
Write: 7 SUCCESS
Total MapReduce CPU Time Spent: 3 minutes 13 seconds 250 msec
OK
546353
Time taken: 239.699 seconds, Fetched: 1 row(s)hive> select count(*) from(select count(*) as query_count from sogou_partitioned_data group by uid having query_count > 2)
B:
> select count(distinct(uid)) from sogou_partitioned_data;
Stage-Stage-1: Map: 2 Reduce: 1 Cumulative CPU: 106.46 sec HDFS Read: 573691789 HDFS Write: 8 SUCCESS
Total MapReduce CPU Time Spent: 1 minutes 46 seconds 460 msec
OK
1352664
Time taken: 109.001 seconds, Fetched: 1 row(s)hive> select count(distinct(uid)) from sogou_partitioned_data;
A/B
hive> select 546353/1352664;
OK
0.40390887907122536
Time taken: 0.255 seconds, Fetched: 1 row(s)hive> select 546353/1352664;
- rank次數在10以內的點選次數佔比(rank既是第四列的內容)
A:
hive> select count(*) from sogou_partitioned_data where rank < 11;
4999869
Time taken: 29.653 seconds, Fetched: 1 row(s)
B:
hive> select count(*) from sogou_partitioned_data;
5000000
A/B
hive> select 4999869/5000000;
OK
0.9999738
- 直接輸入URL查詢的比例
A:
hive> select count(*) from sogou_partitioned_data where keyword like '%www%';
OK
73979
B:
hive> select count(*) from sogou_partitioned_data;
OK
5000000
A/B
hive> select 73979/5000000;
OK
0.0147958
實現資料分析需求四:獨立使用者行為分析
(1)查詢搜尋過”仙劍奇俠傳“的uid,並且次數大於3
> select uid,count(*) as cnt from sogou_partitioned_data where keyword='仙劍奇俠傳' group by uving cnt > 3;
Query ID = root_20181214020303_dbf96d64-9f8e-4ed5-844d-711de957e8b8
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 3
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1544683093139_0015, Tracking URL = http://bigdata000:8088/proxy/application_1544683093139_0015/
Kill Command = /app/hadoop-2.6.0-cdh5.15.1/bin/hadoop job -kill job_1544683093139_0015
Hadoop job information for Stage-1: number of mappers: 2; number of reducers: 3
MapReduce Total cumulative CPU time: 1 minutes 37 seconds 730 msec
Ended Job = job_1544683093139_0015
MapReduce Jobs Launched:
Stage-Stage-1: Map: 2 Reduce: 3 Cumulative CPU: 97.73 sec HDFS Read: 573703160 HDFS Write: 70 SUCCESS
Total MapReduce CPU Time Spent: 1 minutes 37 seconds 730 msec
OK
653d48aa356d5111ac0e59f9fe736429 6
e11c6273e337c1d1032229f1b2321a75 5
Time taken: 106.129 seconds, Fetched: 2 row(s)hive> select uid,count(*) as cnt from sogou_partitioned_data where keyword='仙劍奇俠傳' group by uid having cnt > 3;