
Source Map的原理探究
摘要: Source Map很神奇,它的原理挺複雜的…
Fundebug經授權轉載,版權歸原作者所有。
線上產品程式碼一般是編譯過的,前端的編譯處理過程包括不限於
- 轉譯器/Transpilers (Babel, Traceur)
- 編譯器/Compilers (Closure Compiler, TypeScript, CoffeeScript, Dart)
- 壓縮/Minifiers (UglifyJS)
這裡提及的都是可生成Source Map的操作。
經過這一系列騷氣的操作後,釋出到線上的程式碼已經面目全非,對頻寬友好了,但對開發者除錯並不友好。於是就有了Source Map。顧名思義,他是原始碼的對映,可以將壓縮後的程式碼再對應回未壓縮的原始碼。使得我們在除錯線上產品時,就好像在除錯開發環境的程式碼。
來看一個工作的示例
準備兩個測試檔案,一個 log.js 裡包含一個輸出內容到控制檯的函式:
function sayHello(name) {
if (name.length > 2) {
name = name.substr(0, 1) + '...'
}
console.log('hello,', name)
}
一個main.js 檔案裡面對這個方法進行了呼叫:
sayHello('世界')
sayHello('第三世界的人們')
我們使用 uglify-js 將兩者合併打包並且壓縮。
npm install uglify-js -g
uglifyjs log.js main.js -o output.js --source-map "url='/output.js.map'" 安裝並執行後,我們得到了一個輸出檔案 output.js,同時生成了一個Source Map檔案 output.js.map。
output.js
function sayHello(name){if(name.length>2){name=name.substr(0,1)+"..."}console.log("hello,",name)}sayHello("世界");sayHello("第三世界的人們");
//# sourceMappingURL=/output.js.map
output.js.map
{"version":3,"sources":["log.js","main.js" 為了能夠讓Source Map能夠被瀏覽器載入和解析,
- 再新增一個
index.html來載入我們生成的這個output.js檔案。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>source map demo</title>
</head>
<body>
Source Mapdemo
<script src="output.js"></script>
</body>
</html>
- 然後開啟一個本地伺服器,這裡我使用 python 自帶的server 工具:
python3 -m http.server
- 在瀏覽器中開啟Source Map
Source Map在瀏覽器中預設是關閉的,這樣就不會影響正常使用者。當我們開啟後,瀏覽器就根據壓縮程式碼中指定的Source Map地址去請求 map 資源。
最後,就可以訪問 http://localhost:8000/ 來測試我們的程式碼了。
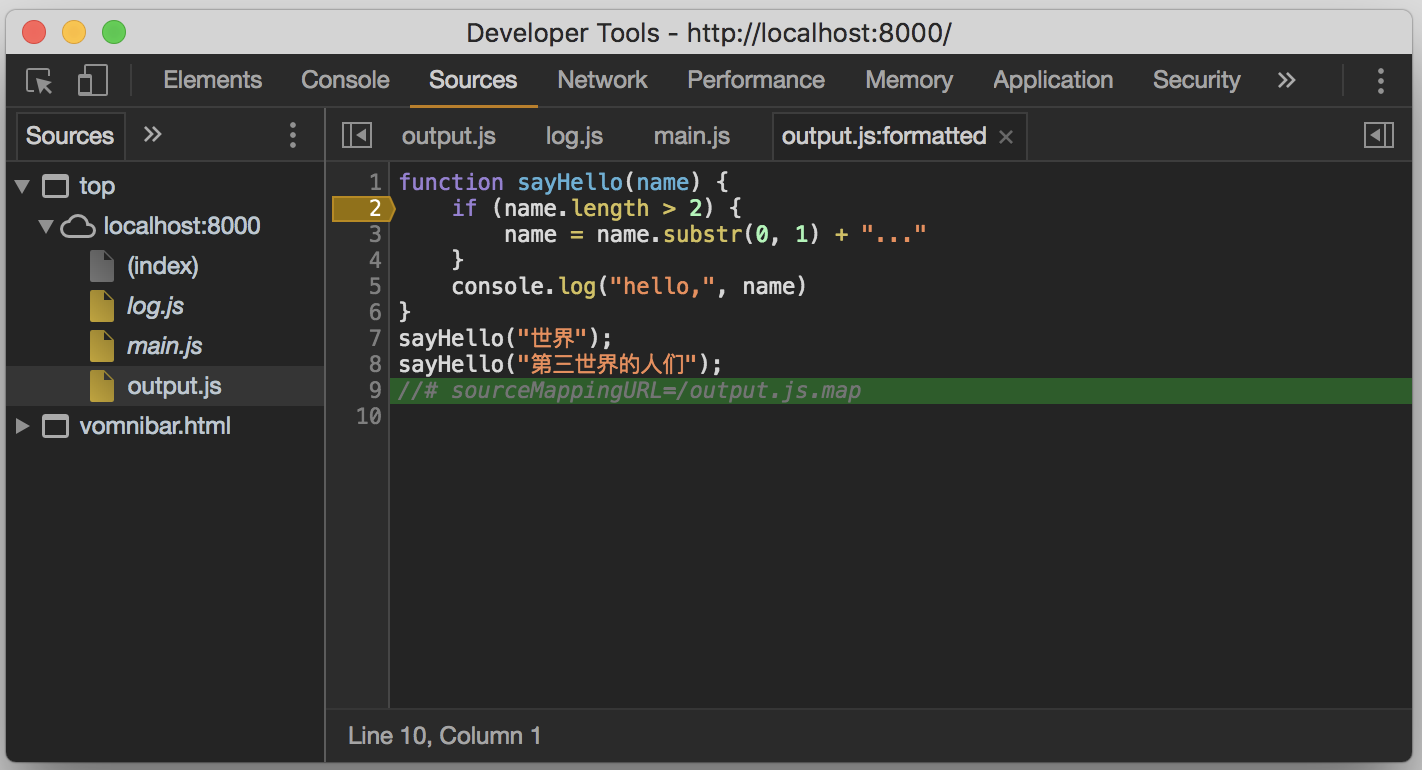
- 在壓縮過的程式碼中打斷點
從截圖中可以看到,開啟Source Map後,除了頁面中引用的 output.js 檔案,瀏覽器還載入了生成它的兩個原始檔,以方便我們在除錯瀏覽器會自動映射回未壓縮合並的原始檔。
為了測試,我們將 output.js 在除錯工具中進行格式化,然後在 sayHello 函式中打一個斷點,看它是否能將這個斷點的位置還原到這段程式碼真實所在的檔案及位置。
重新整理頁面後,我們發現,斷點正確定位到了 log.js 中正確的位置。
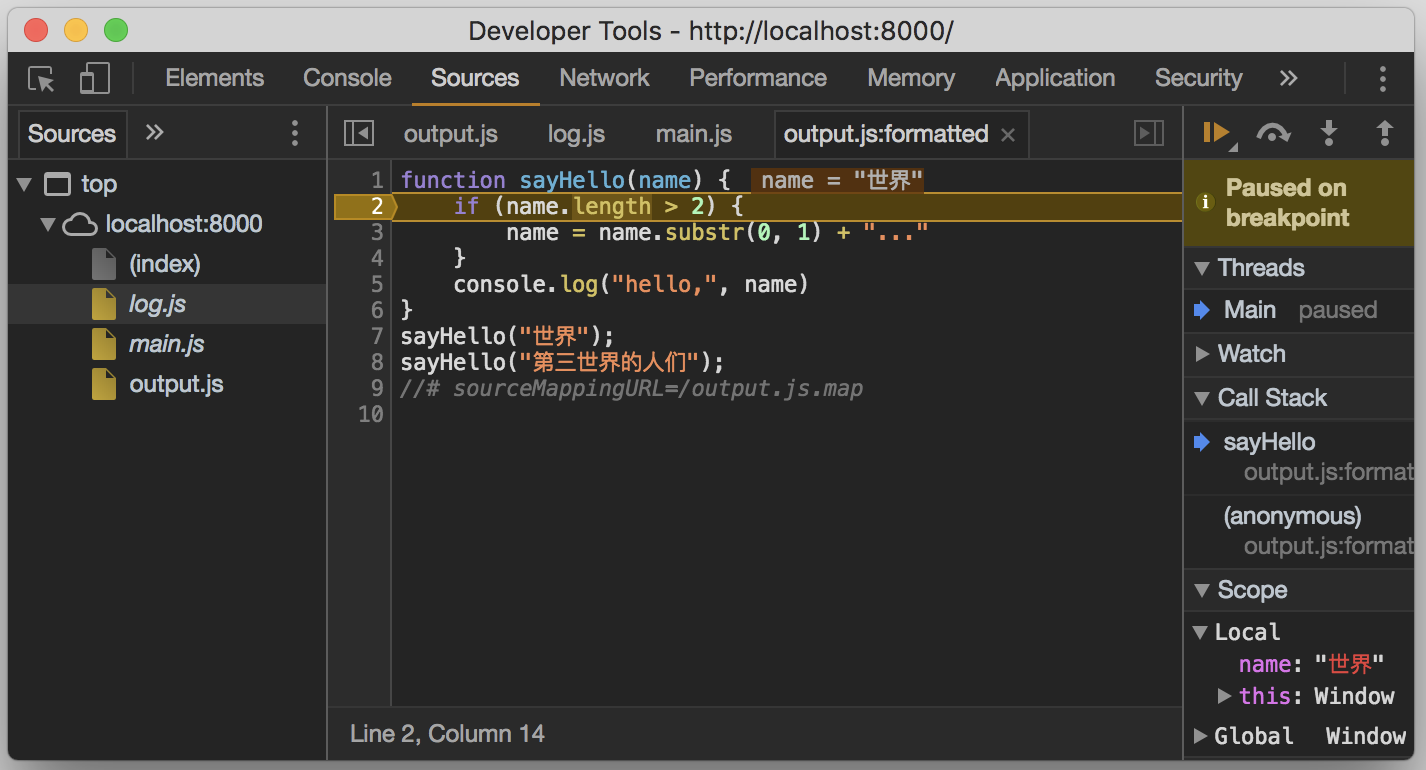
會否覺得很贊啊!
下面我們來了解它的工作原理。
我們所想象的Source Map
將現實中的情況簡化一下無非是以下的場景:
輸入 ⇒ 處理轉換(uglify) ⇒ 輸出(js)
上面,輸出無疑就是需要釋出到產品線上的瀏覽器能執行的程式碼。這裡只討論js,所以輸出是js程式碼,當然,其實Source Map也可以運用於其他資源比如LESS/SASS等編譯到的CSS。
而Source Map的功能是幫助我們在拿到輸出後還原回輸入。如果我們自己來實現,應該怎麼做。
最直觀的想法恐怕是,將生成的檔案中每個字元位置對應的原位置儲存起來,一一對映。請看來自這篇文章中給出的示例:
“feel the force” ⇒ Yoda ⇒ “the force feel”
一個簡單的文字轉換輸出,其中 Yoda 可以理解為一個轉換器。將上面的的輸入與輸出列成表格可以得出這個轉換後輸入與輸出的對應關係。
| 輸出位置 | 輸入 | 在輸入中的位置 | 字元 |
|---|---|---|---|
| 行 1, 列 0 | Yoda_input.txt | 行 1, 列 5 | t |
| 行 1, 列 1 | Yoda_input.txt | 行 1, 列 6 | h |
| 行 1, 列 2 | Yoda_input.txt | 行 1, 列 7 | e |
| 行 1, 列 4 | Yoda_input.txt | 行 1, 列 9 | f |
| 行 1, 列 5 | Yoda_input.txt | 行 1, 列 10 | o |
| 行 1, 列 6 | Yoda_input.txt | 行 1, 列 11 | r |
| 行 1, 列 7 | Yoda_input.txt | 行 1, 列 12 | c |
| 行 1, 列 8 | Yoda_input.txt | 行 1, 列 13 | e |
| 行 1, 列 10 | Yoda_input.txt | 行 1, 列 0 | f |
| 行 1, 列 11 | Yoda_input.txt | 行 1, 列 1 | e |
| 行 1, 列 12 | Yoda_input.txt | 行 1, 列 2 | e |
| 行 1, 列 13 | Yoda_input.txt | 行 1, 列 3 | l |
這裡之所以將輸入檔案也作為對映的必需值,它可以告訴我們從哪裡去找原始檔。並且,在程式碼合併時,生成輸出檔案的原始檔不止一個,記錄下每處程式碼來自哪個檔案,在還原時也很重要。
上面可以直觀看出,生成檔案中 (1,0) 位置的字元對應原始檔中 (1,5)位置的字元,… 將上面的表格整理記錄成一個對映編碼看起來會是這樣的:
mappings(283 字元):1|0|Yoda_input.txt|1|5, 1|1|Yoda_input.txt|1|6, 1|2|Yoda_input.txt|1|7, 1|4|Yoda_input.txt|1|9, 1|5|Yoda_input.txt|1|10, 1|6|Yoda_input.txt|1|11, 1|7|Yoda_input.txt|1|12, 1|8|Yoda_input.txt|1|13, 1|10|Yoda_input.txt|1|0, 1|11|Yoda_input.txt|1|1, 1|12|Yoda_input.txt|1|2, 1|13|Yoda_input.txt|1|3
這樣確實能夠將處理後的檔案映射回原來的檔案,但隨著內容的增多,轉換規則更加地複雜,這個記錄對映的編碼將飛速增長。這裡原始檔 feel the force 才12個字元,而記錄他轉換的對映就已經達到了283個字元。所以這個編碼的方式還有待改進。
省去輸出檔案中的行號
大多數情況下處理後的檔案行數都會少於原始檔,特別是 js,使用 UglifyJS 壓縮後的檔案通常只有一行。基於此,每必要在每條對映中都帶上輸出檔案的行號,轉而在這些對映中插入;來標識換行,可以節省大量空間。
mappings (245 字元): 0|Yoda_input.txt|1|5, 1|Yoda_input.txt|1|6, 2|Yoda_input.txt|1|7, 4|Yoda_input.txt|1|9, 5|Yoda_input.txt|1|10, 6|Yoda_input.txt|1|11, 7|Yoda_input.txt|1|12, 8|Yoda_input.txt|1|13, 10|Yoda_input.txt|1|0, 11|Yoda_input.txt|1|1, 12|Yoda_input.txt|1|2, 13|Yoda_input.txt|1|3;
可符號化字元的提取
這個例子中,一共有三個單詞,拿輸出檔案中 the 來說,當我們通過它的第一個字母t(1,0)確定出對應原始檔中的位置(1,5),後面的he 其實不用再記錄映射了,因為the 可以作為一個整體來看,試想 js 原始碼中一個變數名,函式名這些都不會被拆開的,所以當我們確定的這個單詞首字母的對映關係,那整個單詞其實就能還原到原來的位置了。
所以,首先我們將檔案中可符號化的字元提取出來,將他們作為整體來處理。
| 序號 | 符號 |
|---|---|
| 0 | the |
| 1 | force |
| 2 | feel |
於是得到一個所有包含所有符號的陣列:
names: ['the','force','feel']
在記錄時,只需要記錄一個索引,還原時通過索引來這個names 陣列中找即可。所以上面對映規則中最後一列本來記錄了每個字元,現在改為記錄一個單詞,而單詞我們只記錄其在抽取出來的符號陣列中的索引。
所以 the 的對映由原來的
0|Yoda_input.txt|1|5, 1|Yoda_input.txt|1|6, 2|Yoda_input.txt|1|7
可以簡化為
0|Yoda_input.txt|1|5|0
同時,考慮到程式碼經常會有合併打包的情況,即輸入檔案不止一個,所以可以將輸入檔案抽取一個數組,記錄時,只需要記錄一個索引,還原的時候再到這個陣列中通過索引取出檔案的位置及檔名即可。
sources: ['Yoda_input.txt']
所以上面the 的對映進一步簡化為:
0|0|1|5|0
於是我們得到了完整的對映為:
sources: ['Yoda_input.txt']
names: ['the','force','feel']
mappings (31 字元): 0|0|1|5|0, 4|0|1|9|1, 10|0|1|0|2;
記錄相對位置
當檔案內容巨大時,上面精簡後的編碼也有可能會因為數字位數的增加而變得很長,同時,處理較大數字總是不如處理較小數字容易和方便。於是考慮將上面記錄的這些位置用相對值來記錄。比如(1,1001)第一行第999列的符號,如果用相對值,我們就不用每次記錄都從0開始數,假如前一個符號位置為 (1,999),那後面這個符號可記錄為(0,2),類似這樣的相對值幫我們節省了空間,同時降低了資料的維度。
具體到本例中,看看最初的表格中,記錄的輸出檔案中的位置:
| 輸出位置 | 輸出位置 |
|---|---|
| 行 1, 列 0 | 行 1, 列 0 |
| 行 1, 列 4 | 行 1, 列 (上一值 + 4 = 4) |
| 行 1, 列 10 | 行 1, 列 (上一值 + 6 = 10) |
對應到整個表格則是:
| 輸出位置 | 輸入檔案的索引 | 輸入的位置 | 符號索引 |
|---|---|---|---|
| 行 1, 列 0 | 0 | 行 1, 列 5 | 0 |
| 行 1, 列 +4 | +0 | 行 1, 列 +4 | +1 |
| 行 1, 列 +6 | +0 | 行 1, 列 -9 | +1 |
然後我們得到的編碼為:
sources: ['Yoda_input.txt']
names: ['the','force','feel']
mappings (31 字元): 0|0|1|5|0, 4|0|1|4|1, 6|0|1|-9|1;
注意
- 上面記錄相對位置後,我們的數字中出現了負值,所以之後解析Source Map檔案看到負值就不會感到奇怪了
- 另外一點我的思考,對於輸出位置來說,因為是遞增的,相對位置確實有減小數字的作用,但對於輸入位置,效果倒未必是這樣了。拿上面對映中最後一組來說,原來的值是
10|0|1|0|2,改成相對值後為6|0|1|-9|1。第四位的值即使去掉減號,因為它在原始檔中的位置其實是不確定的,這個相對值可以變得很大,原來一位數記錄的,完全有可能變成兩位甚至三位。不過這種情況應該比較少,它增加的長度比起對於輸出位置使用相對記法後節約的長度要小得多,所以總體上來說空間是被節約了的。
VLQ (Variable Length Quantities)
VLQ 以數字的方式呈現
如果你想順序記錄4個數字,最簡單的辦法就是將每個數字用特殊的符號隔開:
1|2|3|4
如果如果提前告訴你這些被記錄的數字都是一位的,那這個分隔線就沒必要了,只需要簡單記錄成如下樣子也能被正確識別出來:
1234
此時這個記錄值的長度是原來的1/2,省了不少空間。
但實際上我們不可能只記錄個位數的數字,使用 VLQ 方式時,如果一個數字後面還跟有剩餘數字,將其標識出來即可。假設我們想記錄如下的四個數字:
1|23|456|7
我們使用下劃線來標識一個數字後跟有其他數字:
1234567
所以解讀規則為:
- 1沒有下劃線,那解析出來第一個數字便是1
- 2有下劃線,則繼續解析,碰到3,3沒有下劃線,第二位數的解析到此為止,所以第二位數為23
- 4有下劃線,繼續,5也有,繼續,6沒有下劃線,所以第三位數字為456
- 7沒有下劃線,第四位數字則為7
VLQ 以二進位制方式的方式呈現
上面的示例中,引入了數字系統外的符號來標識一個數字還未結束。在二進位制系統中,我們使用6個位元組來記錄一個數字(可表示至多64個值),用其中一個位元組來標識它是否未結束(正文 C 標識),不需要引入額外的符號,再用一位標識正負(下方 S),剩下還有四位用來表示數值。用這樣6個位元組組成的一組拼起來就可以表示出我們需要的數字串了。
| B5 | B4 | B3 | B2 | B1 | B0 |
|---|---|---|---|---|---|
| C | Value | S |
第一個位元組組(四位作為值)
這樣一個位元組組可以表示的數字範圍為:
| Binary group | Meaning |
|---|---|
| 000000 | 0 |
| 000001 * | -0 |
| 000010 | 1 |
| 000011 | -1 |
| 000100 | 2 |
| 000101 | -2 |
| … | … |
| 011110 | 15 |
| 011111 | -15 |
| 100000 | 未結束的0 |
| 100001 | 未結束的-0 |
| 100010 | 未結束的1 |
| 100011 | 未結束的-1 |
| … | … |
| 111110 | 未結束的15 |
| 111111 | 未結束的-15 |
* -0 沒有實際意義,但技術上它是存在的
任意數字中,第一個位元組組中已經標明瞭該數字的正負,所以後續的位元組組中無需再標識,於是可以多出一位來作表示值。
| B5 | B4 | B3 | B2 | B1 | B0 |
|---|---|---|---|---|---|
| C | Value |
未結束的位元組組(五位作為值)
現在我們使用上面的二進位制規則來重新編碼之前的這個數字序列 1|23|456|7。
先看每個數字對應的真實二進位制是多少:
| 數值 | 二進位制 |
|---|---|
| 1 | 1 |
| 23 | 10111 |
| 456 | 111001000 |
| 7 | 111 |
- 對1進行編碼
1需要一位來表示,還好對於首個位元組組,我們有四位來表示值,所以是夠用的。
| B5© | B4 | B3 | B2 | B1 | B0(S) |
|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 1 | 0 |
- 對23進行編碼
23的二進位制為10111一共需要5位,第一組位元組組只能提供4位來記錄值,所以用一組位元組組不行,需要使用兩組位元組組。將 10111拆分為兩組,後四位0111放入第一個位元組組中,剩下一位1放入第二個位元組組中。
| B5© | B4 | B3 | B2 | B1 | B0(S) | B5© | B4 | B3 | B2 | B1 | B0 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
- 對456進行編碼
456的二進位制111001000需要佔用9個位元組,同樣,一個位元組組放不下,先拆出最後四位(1000)放入一個首位位元組組中,剩下的5位(11100)放入跟隨的位元組組中。
| B5© | B4 | B3 | B2 | B1 | B0(S) | B5© | B4 | B3 | B2 | B1 | B0 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 |
- 對7進行編碼
3的二進位制為111,首位位元組組能夠存放得下,於是編碼為:
| B5© | B4 | B3 | B2 | B1 | B0(S) |
|---|---|---|---|---|---|
| 0 | 0 | 1 | 1 | 1 | 0 |
將上面的編碼合併得到最終的編碼:
000010 101110 000001 110000 011100 001110
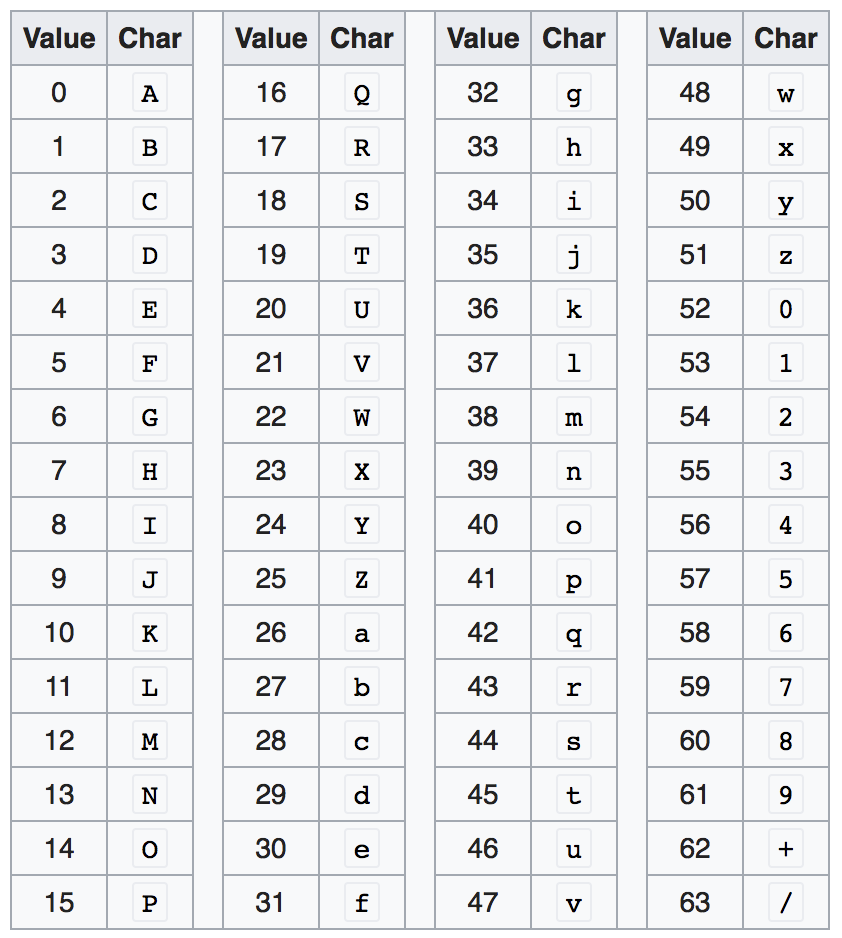
結合上面的 Base64 編碼表,上面的結果轉成對應的 base64 字元為:
CuBwcO
利用 Base64 VLQ 編碼生成最終的 srouce map
通過上面討論的方法,回到開始的示例中,前面我們已經得到的編碼為
sources: ['Yoda_input.txt']
names: ['the','force','feel']
mappings (31 字元): 0|0|1|5|0, 4|0|1|4|1, 6|0|1|-9|1;
現在來編碼 0|0|1|5|0。先用二進位制對每個數字進行表示,再轉成 VLQ 表示:
0-> 0 -> 000000 //0
0-> 0 -> 000000 //0
1-> 1 -> 000010 //2
5-> 101 -> 001010 // 10
0-> 0 -> 000000 //0
合併後的編碼為:
000000 000000 000001 000101 000000
再轉 Base64 後得到字元形式的結果:
AACKA
後面兩串數通過類似的做法也能得到對應的 Base64編碼,所以最終我們得到的Source Map看起來是這樣的:
sources: ['Yoda_input.txt']
names: ['the','force','feel']
mappings (18 字元): AACKA, IACIC, MACTC;
而真實的 srouce map 如我們文章開頭那個示例一樣,是一個 json 檔案,所以最後我們得到的一分像模像樣的Source Map為:
{
"version": 3,
"file": "Yoda_output.txt",
"sources": ["Yoda_input.txt"],
"names": ["the", "force", "feel"],
"mappings": "AACKA,IACIC,MACTC;"
}
略去不必要的欄位
上面的例子中,每一片段的編碼由五位組成。真實場景中,有些情況下某些欄位其實不必要,這時就可以將其省略。當然,這裡給出的這個例子看不出來。
省略其中某些欄位後,一個編碼片段就不一定是5位了,他的長度有可能為1,4或者5。
- 5 - 包含全部五個部分:輸出檔案中的列號,輸入檔案索引,輸入檔案中的行號,輸入檔案中的列號,符號索引
- 4 - 輸出檔案中的列號,輸入檔案索引,輸入檔案中的行號,輸入檔案中的列號
- 1 - 輸出檔案中的列號
以上,便探究完了 srouce map 生成的全過程,瞭解了其原理。
如果感興趣,這個Source map visualizer tool 工具可以線上將Source Map與對應程式碼可見化展現出來,方便理解。
另外需要介紹的是,儘管Source Map對於線上除錯非常有用,各主流瀏覽器也實現對其的支援,但關於它的規範沒有見諸各 Web 工作組或團體的官方文件中,它的規範是寫在一個 Google 文件中的!這你敢信,不信去看一看嘍~ Source Map Revision 3 Proposal。
相關資料
後續
- Source Map的保護
關於Fundebug
Fundebug專注於JavaScript、微信小程式、微信小遊戲、支付寶小程式、React Native、Node.js和Java實時BUG監控。 自從2016年雙十一正式上線,Fundebug累計處理了7億+錯誤事件,得到了Google、360、金山軟體、百姓網等眾多知名使用者的認可。歡迎免費試用!
